计算机内存系统详解:从RAM到虚拟内存
版权申诉
92 浏览量
更新于2024-07-03
收藏 3.98MB PPT 举报
"这是一份关于计算机组成原理的课件,主要讲解了计算机的内存系统,包括内存系统的概述、半导体RAM存储器、只读存储器、内存层次结构、缓存存储器、虚拟内存以及辅助存储器等内容。"
在计算机科学中,内存系统是计算机硬件的核心组成部分,它对计算机性能和效率起着至关重要的作用。本课件详细阐述了以下几个方面:
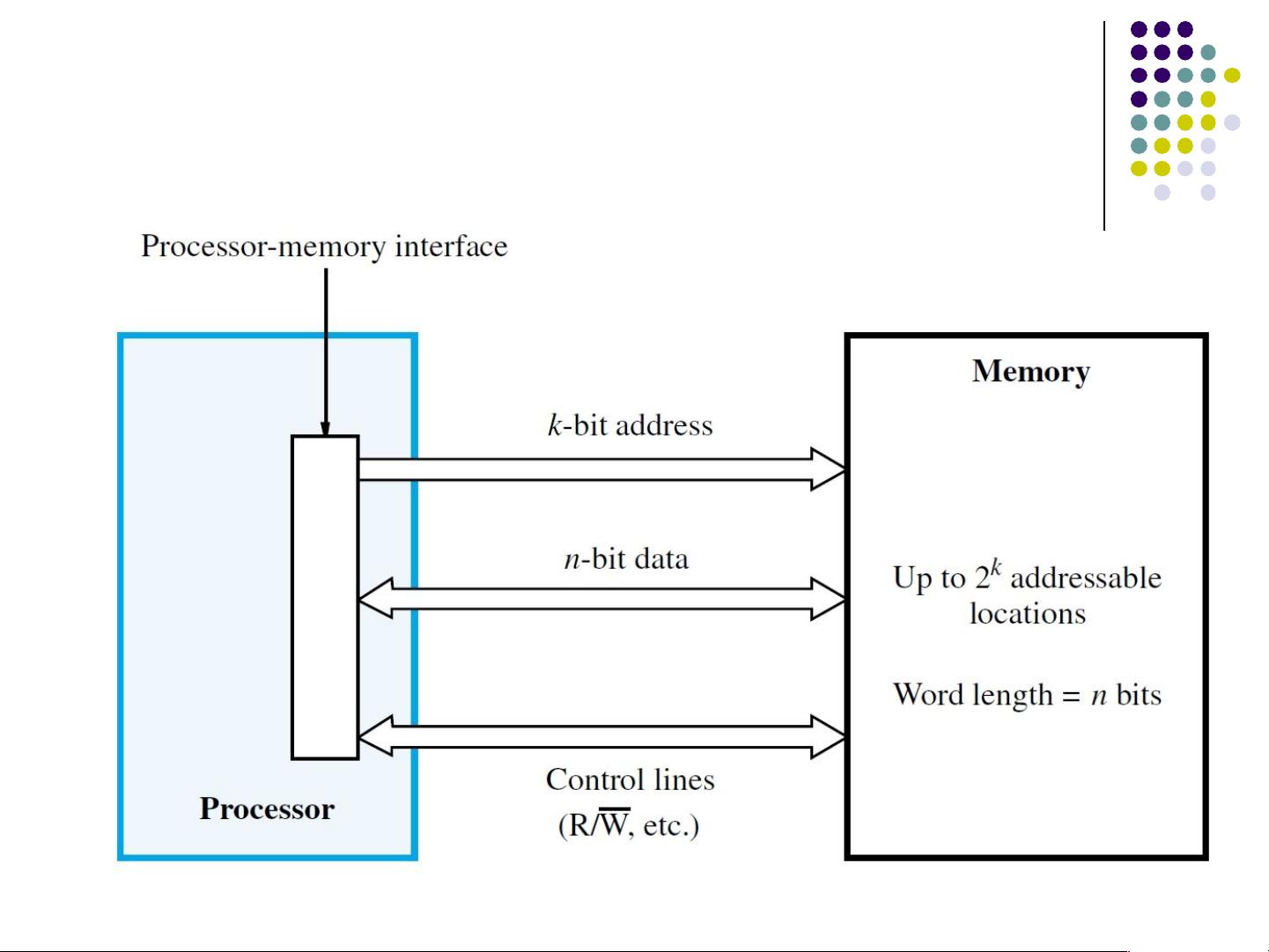
1. **内存系统概述**:计算机内存分为内部存储(主存储)和外部存储(次级存储)。内部存储器,如主内存、缓存和处理器寄存器,直接与处理器交互,提供快速的数据存取。外部存储,例如硬盘或固态驱动器,虽然存储容量大,但访问速度相对较慢,通常通过I/O模块进行数据交换。
2. **半导体RAM存储器**:随机存取存储器(RAM)是计算机中常用的临时数据存储媒介。它可以随时读取和写入数据,但断电后数据会丢失。根据其工作原理,RAM可分为动态RAM(DRAM)和静态RAM(SRAM),两者在速度和功耗上有所差异。
3. **只读存储器**:只读存储器(ROM)中的数据在制造时就被固化,一般用于存储固定的系统程序或初始化数据,如BIOS,即使电源断开,数据也能保持不变。
4. **内存层次结构**:内存层次结构是为了平衡性能和成本而设计的,从高速缓存(L1、L2、L3)到主内存,再到外部硬盘,形成了一个金字塔结构。高速缓存位于处理器附近,能提供最快的数据访问,而更慢但更大的存储设备则位于金字塔底层。
5. **缓存存储器**:缓存是一种非常小但速度极快的内存,用于存储处理器频繁访问的数据,以减少对主内存的访问次数,提高整体性能。缓存的工作机制基于局部性原理,即程序执行时,数据倾向于在一段时间内集中在较小的区域。
6. **虚拟内存**:当物理内存不足时,虚拟内存(也称为页面或交换空间)将部分硬盘空间作为内存使用。通过虚拟内存管理,操作系统可以运行超过实际物理内存大小的程序,但会导致性能下降,因为硬盘访问速度远低于主内存。
7. **辅助存储器**:次级存储通常指硬盘、SSD等,它们容量大、价格相对较低,但访问速度慢。这些设备用于长期存储大量数据,如操作系统、应用程序和用户文件。
理解计算机的内存系统对于深入学习计算机工作原理至关重要,它涉及到数据的存储、访问和管理,直接影响到计算机的性能和效率。本课件提供了全面的理论知识和实践背景,是学习这一主题的重要参考资料。

12
Basic Concepts
Memory Locations and Addresses
Word Alignment
Words are said to be aligned in memory if they begin at a
byte address that is a multiple of the number of bytes in a
word.
Word are said to be unaligned in memory if they begin at an
arbitrary byte address.
Accessing Numbers, Characters, and Character
Strings
Numbers: specify their word addresses
Individual characters: specify their byte addresses
Character Strings of Variable Length: give the byte address
containing the first character, length of the string

剩余61页未读,继续阅读
2023-06-02 上传
2024-04-15 上传
2023-03-27 上传
2023-06-02 上传
2023-05-19 上传
2023-06-02 上传
2023-06-07 上传
2023-06-08 上传

智慧安全方案
- 粉丝: 3789
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
