"实验报告:英文文本哈夫曼编码译码系统设计与实现"
版权申诉
139 浏览量
更新于2024-03-07
收藏 651KB PDF 举报
本实验旨在设计一个哈夫曼编码、译码系统,对ASCII编码的文本文件中的字符进行哈夫曼编码,生成编码文件,并能将编码文件译码还原为一个文本文件。具体步骤包括:首先从文件中读入任意一篇英文短文,然后统计并输出不同字符在文章中出现的频率,包括空格、换行、标点等都按字符处理。接着根据字符频率构造哈夫曼树,并给出每个字符的哈夫曼编码。然后将文本文件利用哈夫曼树进行编码,存储成压缩文件,并且计算文件压缩率。最后进行译码,将huf文件译码为ASCII编码的txt文件,并与原txt文件进行比较。
在本实验中,哈夫曼树的构建是关键的部分。其理论创建过程包括构成初始集合对给定的n个权值{W1, W2, W3, ..., Wi, ..., Wn}构成n棵二叉树的初始集合F={T1, T2, T3, ..., Ti, ..., Tn},其中每棵二叉树Ti中只有一个权值为Wi的根节点,它的左右子树均为空。接下来,通过合并权值最小的两棵树来构建哈夫曼树,直至所有权值都被合并完成。最终得到的哈夫曼树即可用于对文本文件进行编码和译码的操作。
在实验过程中,需要先将给定的文本文件转换为ASCII编码,并且通过字符统计来得到每个字符出现的频率。根据字符频率构建哈夫曼树,并给出每个字符的编码。然后利用得到的哈夫曼树对文本文件进行编码,并计算文件的压缩率。最后进行译码操作,将编码文件还原为文本文件,并与原始文件进行比较,以验证译码的正确性。
通过本实验,我们可以更加深入地理解哈夫曼编码与译码的原理及实现方法,以及对文本文件进行压缩与解压缩的过程。同时,通过实际操作,也能够加深对哈夫曼树构建过程的理解,并且体会到哈夫曼编码在实际应用中的重要性和优越性。
总的来说,本实验通过对哈夫曼编码、译码系统的设计与实现,加深了对哈夫曼编码原理的理解,并且通过编码与译码的操作,加深了对哈夫曼编码的应用及效果的认识。同时,也对字符统计、哈夫曼树的构建等操作有了更深入的认识。通过本实验,不仅学到了相关知识,也加强了对课堂知识的应用和实践能力。
数据结构选择与算法设计
数据结构选择:
signode:
struct signode{ //signode节点,哈夫曼树节点//
char c; //字符//
int weight; //权重//
bool b; //文章中是否出现//
signode * parent;
signode * left;
signode * right;
signode(){ //初始化//
c=NULL;
b=false;
weight=0;
parent=left=right=NULL;
}
};
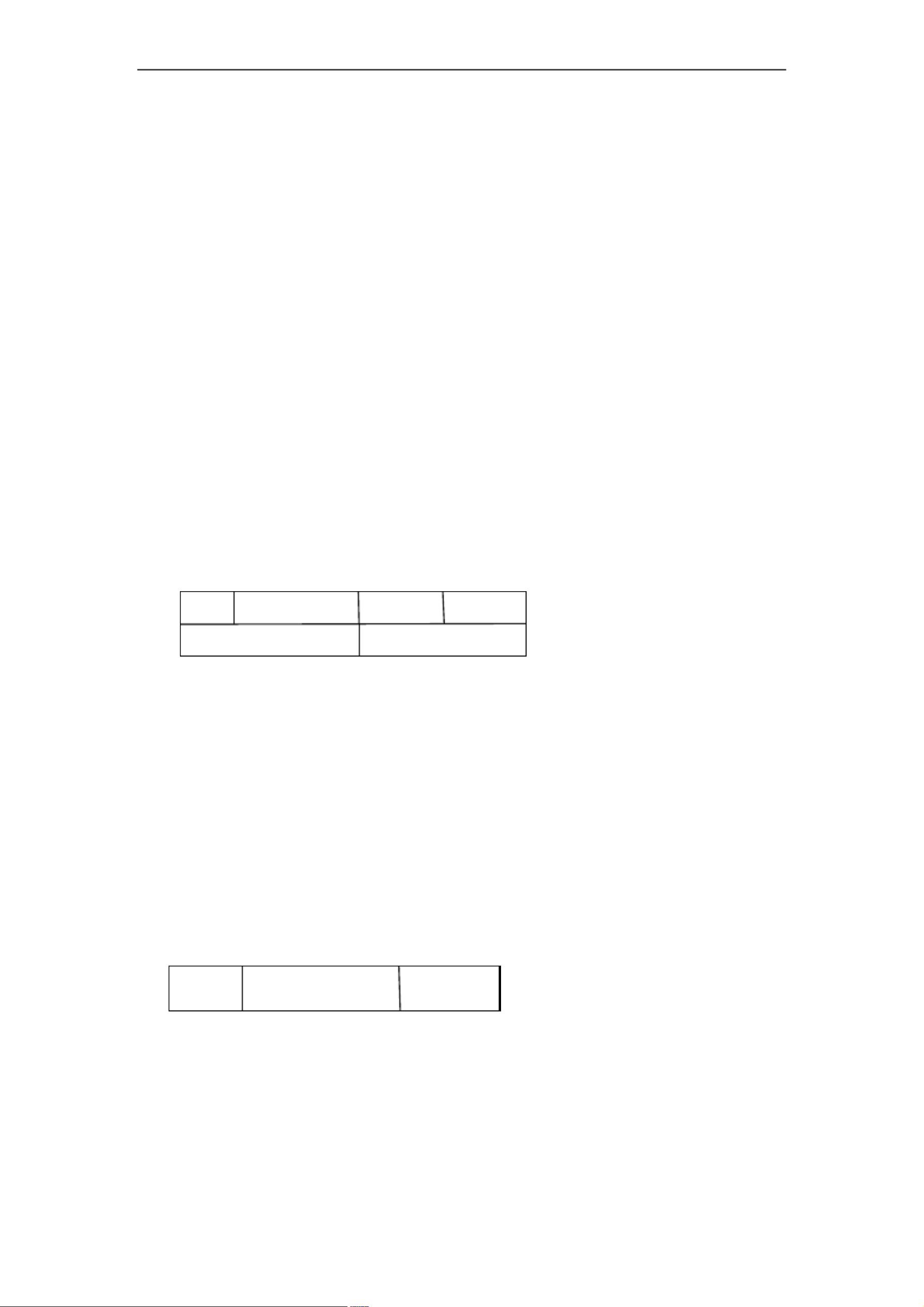
C weight b parent
left right
hufnode:
struct hufnode{ //哈夫曼编码对照表节
点//
signode * sig;
int code[100]; //保存哈夫曼编码//
int size;
bool b;
hufnode(){sig=NULL;size=0;b=true;}
};
code[100] sizeSig
HFM:
class HFM{ //哈夫曼类//
3 / 15
剩余14页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-07-05 上传
2022-11-11 上传
2022-10-30 上传
2022-07-05 上传
2022-10-30 上传
2022-11-11 上传

若♡
- 粉丝: 6385
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
