解析Qualcomm MSM7627平台Android Boot流程:Arm11启动详解
"本文档深入探讨了Android系统的启动过程,特别是在高通MSM7627平台上的具体实现,重点聚焦于Arm11端的AppsBoot bootloader。作者林耕书以Android 4系统为背景,从Arm9启动Arm11的详细流程出发,首先回顾了前文对Arm9启动的介绍,然后详细解析了两个关键函数:oemsbl_load_aarm_bootloader和oemsbl_create_aarm_partition_tbl。
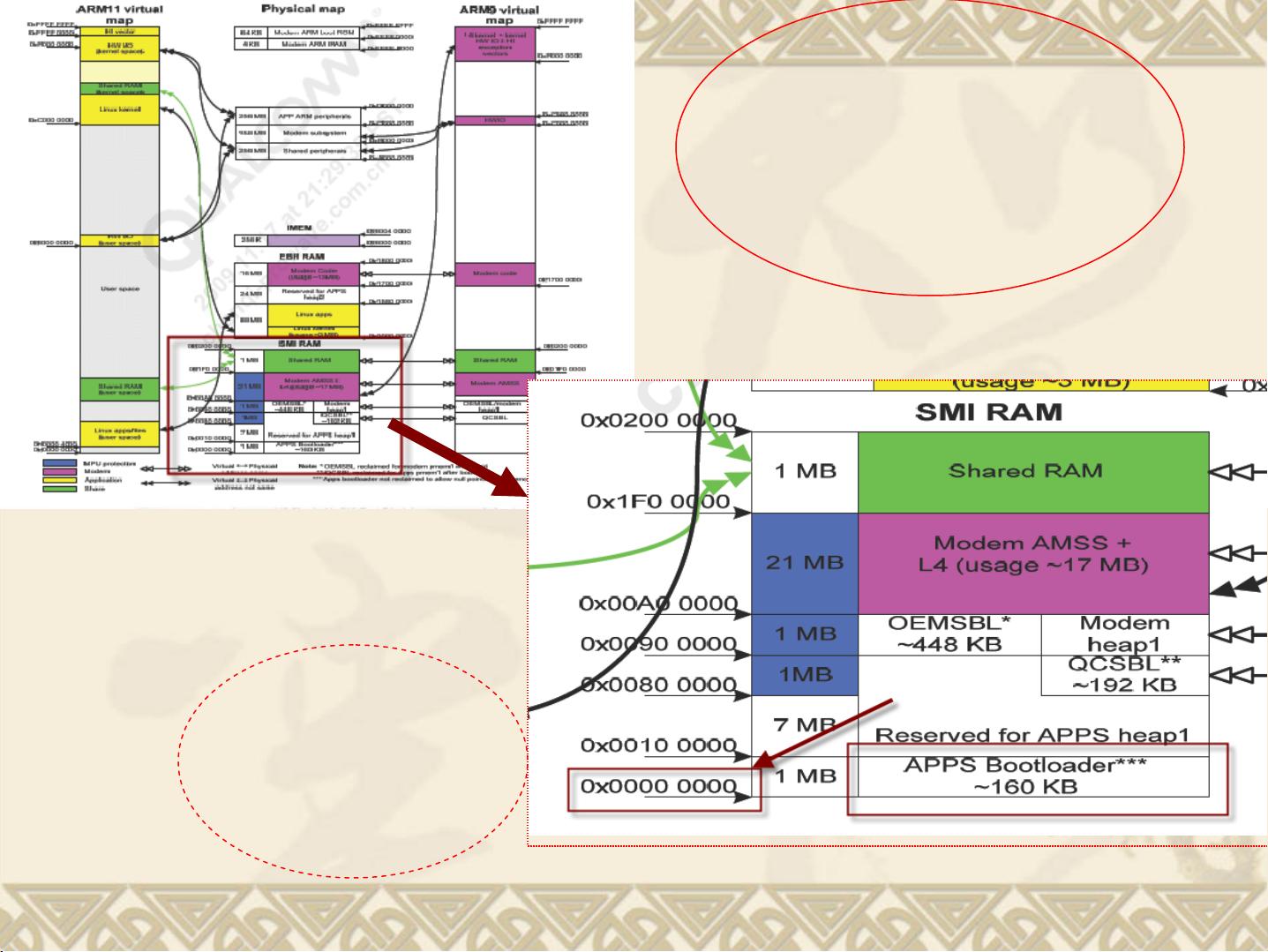
在oemsbl_load_aarm_bootloader函数中,文档展示了如何将AppsBoot bootloader的MBN(Mobile Bootloader Network)文件appsboot.mbn加载到RAM中,特别提到了它被定位在0x00000000地址,这与技术规格中的描述相吻合。作者通过口头讲解和图表辅助,帮助读者理解这一过程。
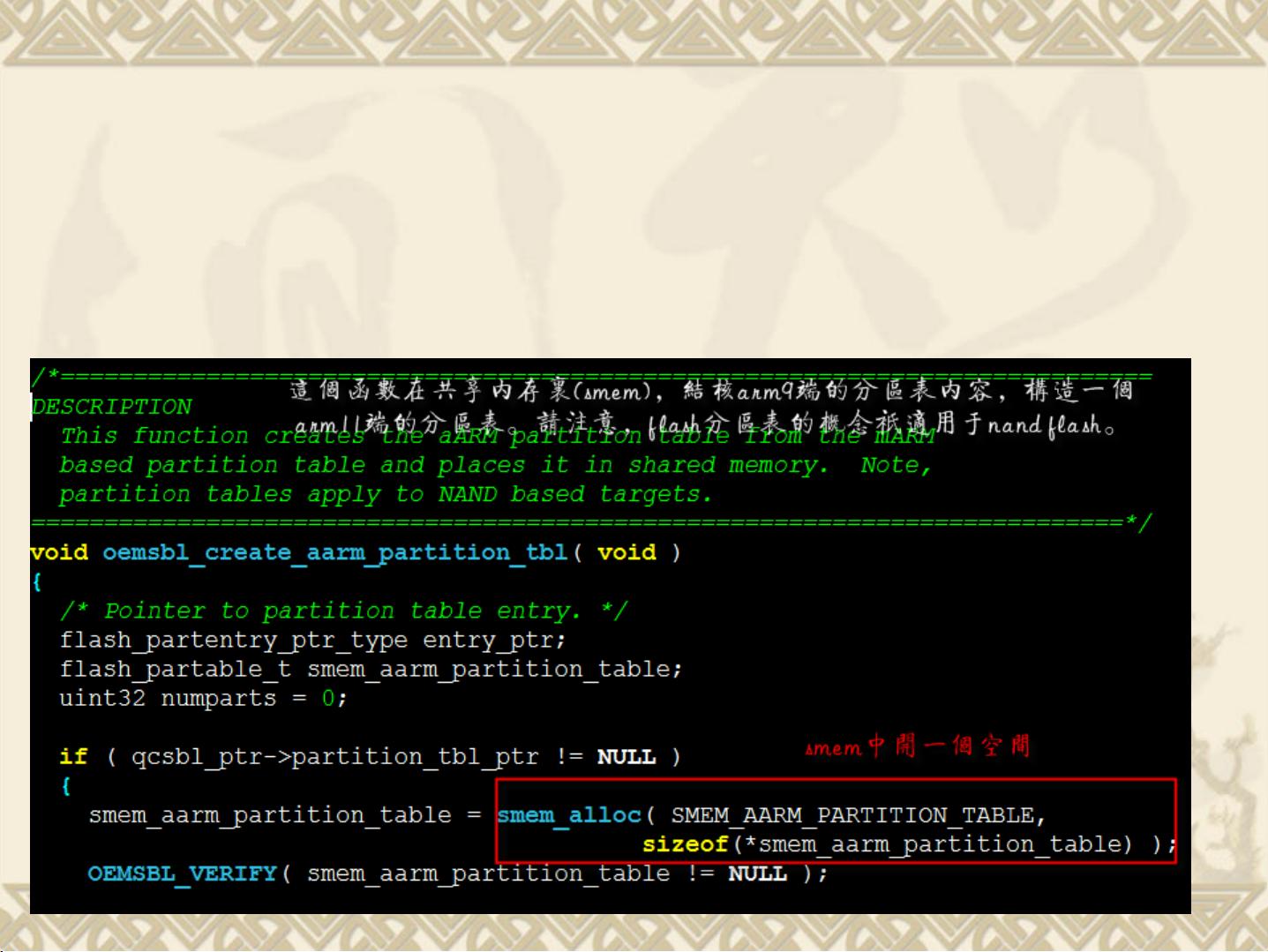
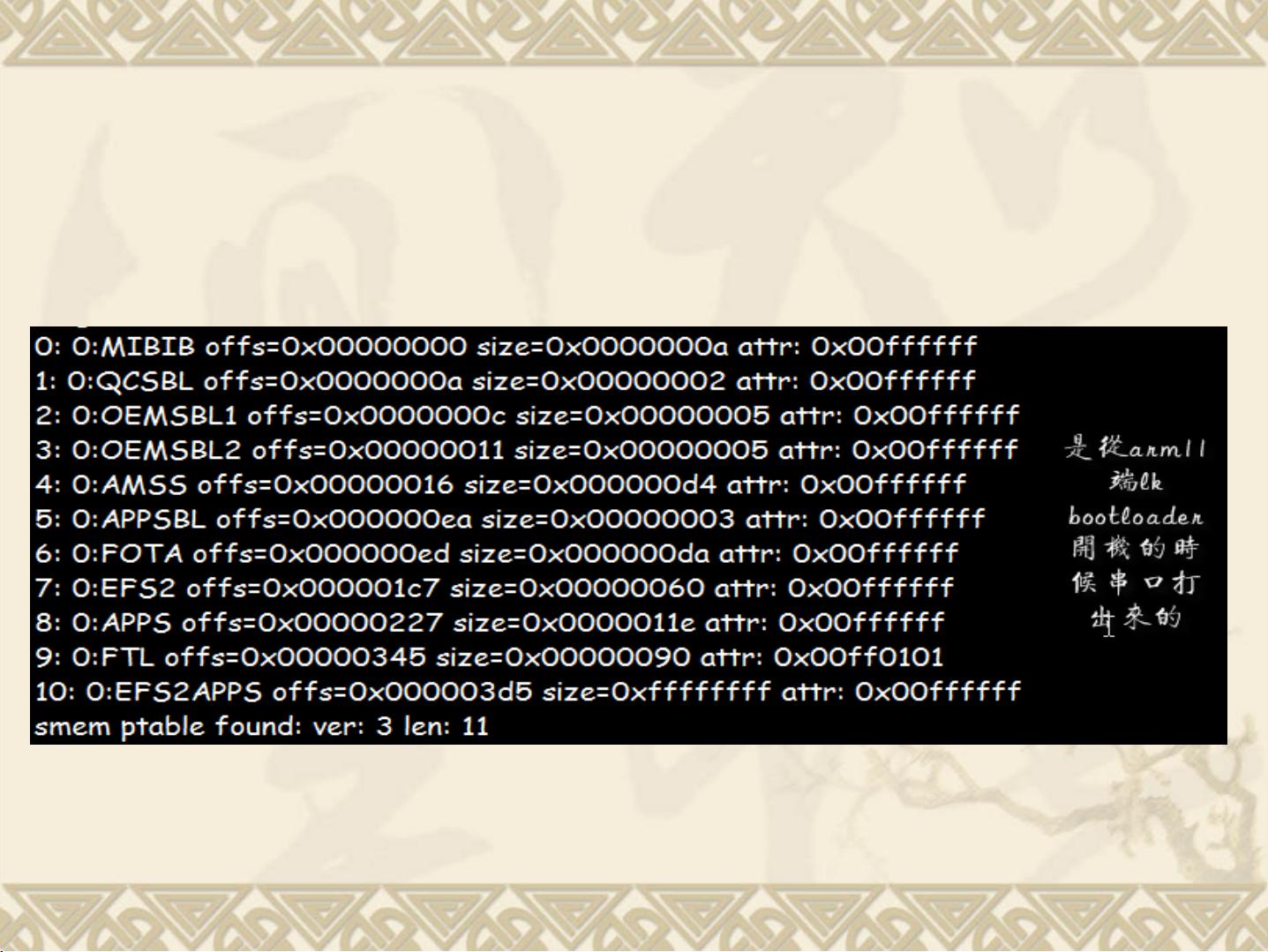
接下来,oemsbl_create_aarm_partition_tbl函数的作用在于在共享内存中创建一个分区表,用于管理不同分区的数据存储和访问。尽管具体实现未在文中详述,但这个步骤是引导Arm11启动的重要环节,因为它配置了系统启动时所需的各种分区信息。
在整个流程中,作者强调了通过这些函数之间的交互,逐步引导Arm11进入运行状态,确保了从低级硬件抽象层(如Arm9)向高级应用执行环境(如Arm11的AppsBoot bootloader)的平稳过渡。此外,文档还可能包含对项目杂谈的部分,可能涉及到开发者的经验和注意事项,以供读者参考。
这篇文档深入剖析了Android系统启动过程中在高通MSM7627平台上的Arm11 bootloader的关键细节,为深入理解Android内核启动机制提供了宝贵的教学资料。"
点击了解资源详情
点击了解资源详情
点击了解资源详情
2015-12-17 上传
2021-11-16 上传
2022-01-06 上传
2021-12-04 上传
2021-10-06 上传
2019-06-13 上传

ahaochina
- 粉丝: 25
- 资源: 62
 我的内容管理
展开
我的内容管理
展开







