分布式SQL计算系统:融合数据库与Hadoop优势
173 浏览量
更新于2024-08-28
收藏 396KB PDF 举报
在现代IT领域,随着数据量的爆炸式增长和复杂查询的需求增加,传统的分布式数据库和Hadoop技术逐渐暴露出了局限性。面对分布式数据库在执行复杂SQL(如排序、分组、JOIN、子查询,特别是处理非均衡字段操作时的性能瓶颈,以及Hadoop在处理SQL计算时的不足,比如存储结果的局限性和单一的MapReduce计算模型),设计师们决定创新并提出一种分布式SQL计算系统。
该系统的设计灵感源于对分布式数据库和Hadoop的深入理解和对比分析。首先,它采用了数据库水平分割策略,即只进行分库不拆分表,可以根据数据量动态调整分库数量,这样既能保持数据的一致性,又能有效应对大规模数据。这种设计使得系统能够适应不同规模的数据存储需求,提高了效率。
其次,系统借鉴了MapReduce的核心思想,但进行了优化。原有的MapReduce在Hadoop中是以磁盘为主存储,且计算模型相对固定。而在新的系统中,计算过程更倾向于将Map和Reduce操作嵌入到SQL中,实现了SQL驱动的计算,这不仅简化了编程复杂性,还借助数据库的缓存机制来动态决定数据在内存或磁盘上的存储,提升了性能。此外,系统允许使用更灵活的计算模型,比如Spark的RDD迭代计算,以适应不同的业务场景。
在架构上,系统提供了两种选择:无代理节点和有代理节点。无代理节点模式下,客户端承担更多的职责,包括处理请求、解析SQL等,而有代理节点模式则将这些功能转移到代理节点,减轻了客户端的负担,并提供了对外部协议的支持,如MySQL接口,方便用户以更直观的方式交互。
这种分布式SQL计算系统通过整合分布式数据库的优点(高效存储和一致性)和MapReduce的计算灵活性,以及引入数据库缓存和多样的计算模型,创造了一个在大规模数据处理和复杂查询上更为高效和灵活的解决方案。这不仅解决了现有技术的痛点,也为未来的数据处理和分析提供了新的可能。
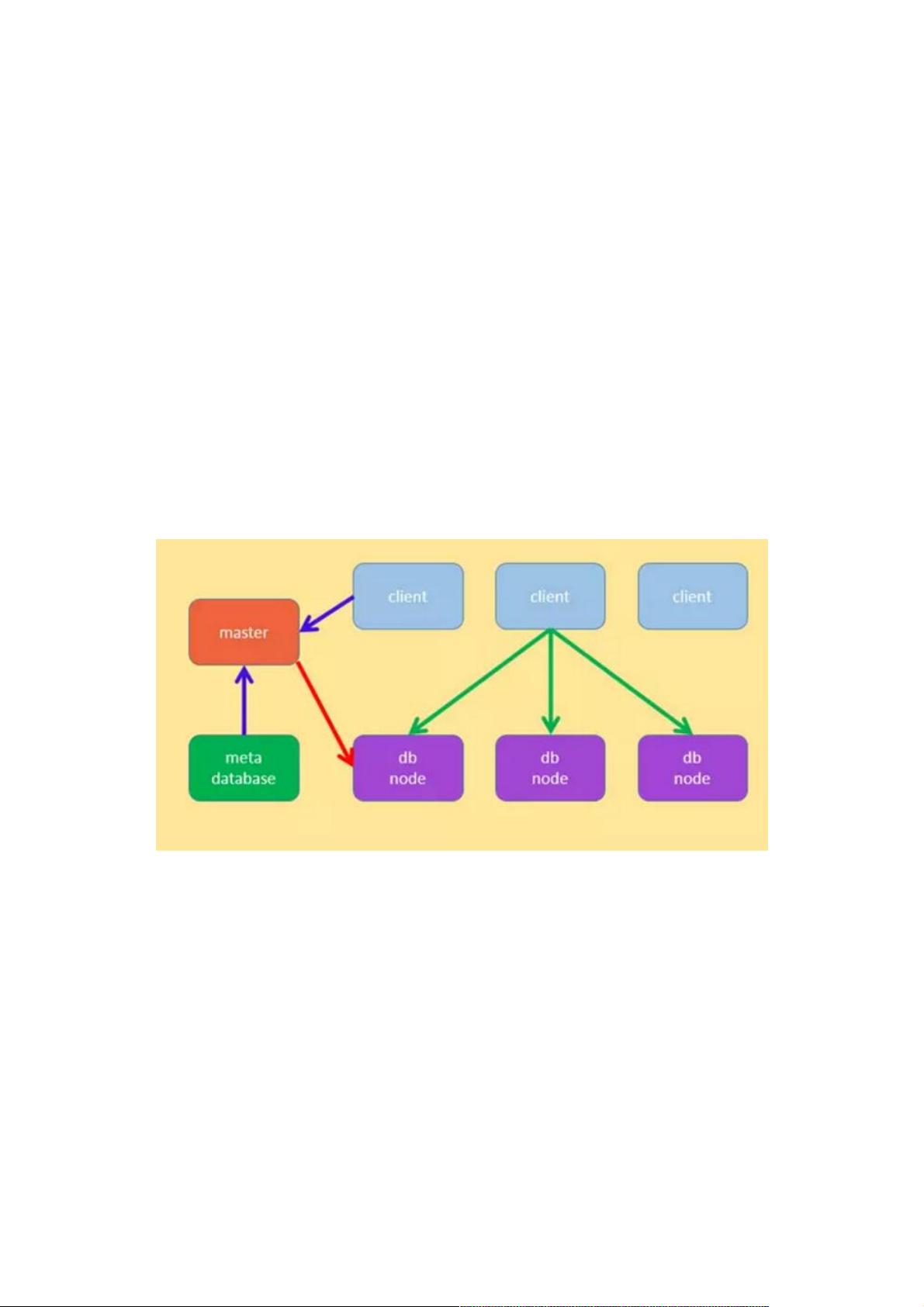
分布式数据库和分布式数据库和Hadoop都不够好,于是我们设计了分布式都不够好,于是我们设计了分布式
SQL计算系统计算系统
设计思想
为了解决分布式数据库下,复杂的 SQL(如全局性的排序、分组、join、子查询,特别是非均衡字段的这些逻辑操作)难以实
现的问题;在有了一些分布式数据库和 Hadoop 实际应用经验的基础上,对比两者的优点和不足,加上自己的一些提炼和思
考, 设计了一套综合两者的系统,利用两者的优点, 补充两者的不足。具体的说, 使用数据库水平分割的思想实现数据存储,
使用 MapReduce的思想实现 SQL 计算。
这里的数据库水平分割的意思是只分库不分表,对于不同数量级别的表,分库的数量可以不一样,例如 1 亿的数据量分 10 个
分库,10 亿的分 50 个分库。对于使用 MapReduce的思想实现计算 ; 对于一个需求,转换成一个或多个有依赖关系的SQL,
其中的每个SQL分解成一个或多个 MapReduce任务,每个 MapReduce任务又包含 mapsql、洗牌(shuffle)、reducesql,
这个过程可以理解为类似 hive,区别是连 MapReduce任务中的 map 和 reduce 操作也是通过 SQL 实现, 而非 Hadoop 中的
map 和 reduce 操作.
这是基本的 MapReduce的思想,但是在 Hadoop 的生态圈中, 第一代的 MapReduce将结果存储于磁盘,第二代的
MapReduce根据内存使用情况将结果存储于内存或磁盘,类比一下用数据库来存储,那么 MapReduce 的结果就是存储在表
中,而数据库的缓存机制天然支持根据内存情况决定存储在内存还是磁盘 ; 另外,Hadoop 生态圈中, 计算模型也并非一种,
这里的 MapReduce的计算思想,可以用类似 spark 的 RDD 迭代计算方式来替代 ; 本系统还是基于 MapReduce来说明的。
架构
根据以上的思想, 系统的架构如下:
没有代理节点
有代理节点
下载后可阅读完整内容,剩余6页未读,立即下载
2013-04-24 上传
2017-09-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-09-24 上传
2021-08-10 上传
点击了解资源详情

weixin_38701407
- 粉丝: 5
- 资源: 917
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
