深入解析CUDA线程束与内存模型
版权申诉
106 浏览量
更新于2024-12-11
收藏 1.92MB DOCX 举报
资源摘要信息:"本次分享将深入解读CUDA(Compute Unified Device Architecture)的线程束(Thread Block)和内存模型(Memory Model),探讨CUDA并行计算的基础知识。CUDA是NVIDIA推出的一种通用并行计算架构,它利用GPU的强大计算能力来解决复杂的计算问题。开发者可以通过CUDA编程模型,在NVIDIA的GPU上运行程序。
首先,我们将解析CUDA中的线程束(又称线程块)的概念。线程束是CUDA编程模型中并行执行的基本单位,是GPU中一组并行执行的线程。每个线程束由一定数量的线程组成(通常为32个线程),它们共享执行上下文并且并行执行同一个指令。理解线程束的调度和执行机制对于编写高效的CUDA程序至关重要。它决定了数据的局部性和缓存使用效率,进而影响整体程序的性能。
接着,我们将深入讨论CUDA内存模型。CUDA内存模型包括多种内存类型,如全局内存、共享内存、常量内存和纹理内存。每种内存类型都有其特定的用途和访问特性。全局内存是GPU中容量最大,但访问速度最慢的内存类型,它可以被所有线程束访问。共享内存则是一种在每个块(Block)中私有的,容量较小但访问速度极快的内存,它被线程束中的所有线程共享,并且可以用来存储临时计算数据或中间结果。正确使用共享内存是提高CUDA程序性能的关键。常量内存和纹理内存通常用于存储只读数据,并且通过缓存机制来提高访问效率。
除此之外,我们还将涉及CUDA内存访问模式和对齐(Padding)的概念,以及内存访问的一致性问题。在CUDA编程中,正确的内存访问模式可以显著减少内存访问延时和提升数据吞吐量。而内存对齐则指为了最大化内存访问性能,对数据进行特定方式的布局。最后,一致性问题指的是保证GPU上的不同内存类型中数据的一致性,这是CUDA编程中一个高级且重要的课题。
通过本次分享,参与者将能够了解CUDA线程束和内存模型的工作原理,以及它们如何共同协作来提升GPU编程的效率。最终目标是让开发者能够利用CUDA的强大功能,解决现实世界中的复杂计算问题,特别是那些适合并行计算的问题。
为了实现上述目标,我们将通过实际的代码示例和图表来说明这些抽象概念。通过这样的实践,参与者将能更深入地理解CUDA编程模型,并掌握如何编写高性能的并行程序。"
CUDA(Compute Unified Device Architecture)是一种由NVIDIA推出的并行计算平台和编程模型,它允许开发者利用NVIDIA的GPU进行通用计算。CUDA编程模型主要基于线程的概念,以线程束(Thread Block)和网格(Grid)作为执行单元,实现了从硬件到软件的抽象,使得开发者能够更容易地编写并行程序。
线程束是CUDA中的基本执行单元,一个线程束由一定数量的线程组成,它们能够同步执行,并且可以访问同一块共享内存。线程束的概念类似于CPU中的超线程技术,都是为了更高效地利用硬件资源。每个线程束中的线程是高度相互依赖的,当线程束中的任何一个线程执行指令时,整个线程束中的线程都必须执行这个指令。由于这个特点,线程束对于提升CUDA程序的性能至关重要。
内存模型方面,CUDA中存在多种不同类型的内存:全局内存、共享内存、常量内存、纹理内存和本地内存。全局内存适用于线程间通信和存储全局数据,但访问速度相对慢;共享内存是一种快速、块内共享的内存,被同一线程束中的所有线程访问,用于存放临时数据和实现线程间通信;常量和纹理内存主要用于存储只读数据,并且可以利用GPU的缓存机制来提升访问速度。理解这些内存类型及其访问模式,是优化CUDA程序性能的关键。
CUDA的内存访问模式对性能有很大影响,开发者需要根据数据的访问模式和访问频率来选择合适的内存类型。比如,对于频繁访问的数据,可能需要将其放置在共享内存中,以减少访问延迟。而对齐(Padding)则是指对数据结构进行布局优化,以更好地适应GPU的内存访问模式,从而提高内存访问效率。
一致性问题涉及到GPU内存中数据的一致性保证,因为GPU中有多种内存层级,开发者需要保证不同内存层级中数据的一致性。例如,在全局内存中更新了数据,那么必须确保所有相关的缓存和内存副本都得到更新,以保持数据的一致性。
通过掌握CUDA的线程束和内存模型,开发者可以更好地理解CUDA编程模型的工作原理,编写出更加高效的并行程序,充分利用GPU的强大计算能力,从而提升计算密集型任务的执行效率。
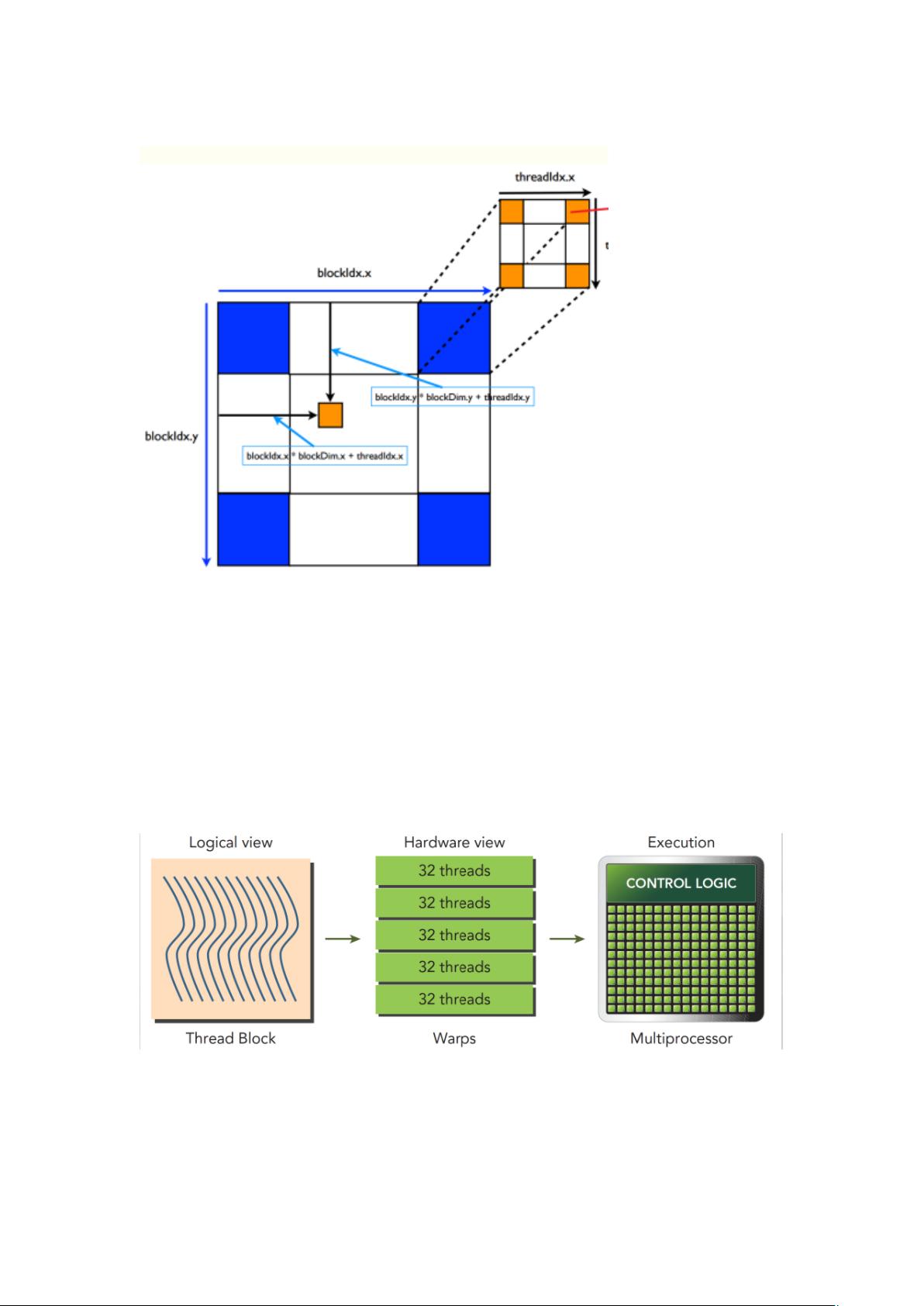
Cuda thread 组成 block,block 组成 grid(目的:矩阵并行计算时,能对应矩阵位置)
线程束
SM 是一种单指令多线程((single Instruction MultipleThread,SIMT)架构的处理器,线程
束是 SM 中基本的执行单元,CUDA 执行的实质是线程束的执行(所有线程按照 SIMT 的方式执
行,每一步执行相同的指令,但是处理的数据为私有数据)。
当一个 grid 被启动后等价于 core 被启动,每个 core 对应自己的 grid,grid 里包含了
blocks,当线程块被分到 SM 之后会被分成多个线程束(线程块分批在物理机器上运行,线程
块内线程束可能进度不一样,线程束内线程进度一样。),每个线程束一般有 32 个线程。
当一个线程块中有 128 个线程的时候,其分配到 SM 上执行时,会分成 4 个块:
Warp1:thread 0... thread31
Warp2:thread 32... thread63
Warp3:thread 64... thread95
Warp4:thread 96... thread127
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-05-11 上传

极智视界
- 粉丝: 3w+
- 资源: 1769
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
