MapReduce编程模型:分布式大数据处理的核心技术
需积分: 9 198 浏览量
更新于2024-09-11
收藏 570KB PDF 举报
"MapReduce是Google提出的一种分布式计算模型,用于处理海量数据集。它基于函数式编程中的map和reduce概念,但在MapReduce框架中,这两个函数被用于处理键值对,实现数据的并行处理和结果聚合。Map阶段将原始数据转化为中间键值对,Reduce阶段则对相同键的值进行合并,以生成最终结果。MapReduce广泛应用于各种场景,如分布式Grep、URL访问频率统计、逆向Web-Link图构建、主机关键向量指标计算以及分布式排序等。这些示例展示了MapReduce在数据处理和分析领域的强大能力。"
MapReduce的核心在于它的两个主要操作:Map和Reduce。Map函数接受输入数据,通常是键值对,对其进行处理,并生成新的中间键值对。这个过程允许数据在分布式环境中并行处理,极大地提高了处理速度。Reduce函数随后接收Map阶段产生的中间键值对,通过聚集相同键的值,进行必要的计算和聚合,最终输出处理后的结果。
在应用实例中,分布式Grep允许用户在大量文本中搜索特定模式,只需在Map阶段检查每一行是否匹配,然后由Reduce阶段直接输出匹配的行。URL访问频率统计则通过Map计算每个URL出现的次数,Reduce则汇总这些信息,输出每个URL及其对应的访问次数。逆向Web-Link图构建则用于分析网页之间的链接关系,Map输出所有指向目标URL的源URL,Reduce聚合这些信息,形成目标URL的链接列表。
主机关键向量指标计算是文本分析的一个例子,Map计算每个文档(根据URL获取主机名)的关键词频率,Reduce则整合所有文档的关键词向量,去除不常用词汇,生成最终的主机关键词向量。逆序索引的构建则通过Map生成(Word, DocumentID)对,Reduce按关键词对DocumentID排序,创建方便查询的索引结构。分布式排序则是对整个数据集进行全局排序的关键步骤,Map抽取关键字,Reduce负责按照关键字排序并输出。
MapReduce的优势在于其可扩展性和容错性,能够处理PB级别的数据,并在硬件故障时自动恢复工作。此外,由于Map和Reduce的抽象层次较高,程序员可以专注于业务逻辑,而不用过多关心底层的分布式细节。然而,MapReduce也存在缺点,如不适合实时或低延迟处理,以及对于迭代计算效率较低。尽管如此,MapReduce仍然是大数据处理领域的重要工具,为Hadoop等开源框架提供了基础,对现代大数据处理技术的发展产生了深远影响。
MapReduce简介
概述
MapReduce最早是由Google提出的用于一种分布式架构中的计算海量数据集的编程模型,它起源于函数式程程序的map
和reduce两个函数,但它们在MapReduce模型中的应用和原来的使用上的大相径庭。在MapReduce模型中,用户指定一
个Map(映射)函数,通过这个Map函数处理键值(KeyValue)对,产生一系列的中间键值对,并且使用一个Reduce(化
简/规约)函数来合并具有相同键(Key)的中间键值对中的值(Value)。
应用
MapReduce算法在实际的系统中使用非常广泛,下面是一些简单有趣的例子,它们都可以使用MapReduce算法来进行计
算。
分布式Grep:如果Map函数检查输入行,满足条件的时候,Map函数就把本行输出。Reduce函数就是一个直通函数,简
单地把中间数据输出就可以了。
URL访问频率统计:Map函数处理请求和应答(URL,1)的Log。Reduce函数把所有相同的URL的值合并,并且输出一个成
对的(URL,总个数)。
逆向WebLink图:Map函数输出所有包含指向目标URL的网页,用(目标URL,源URL)这样的结构对输出。Reduce函数
聚合所有关联相同目标URL的列表、源URL并且输出一个(目标URL,List(源URL))的结构。
主机关键向量指标(TermVectorperHosts):关键词向量指标简而言之就是指在一个文档或者一组文档中的重点词出现的
频率,用(Word,Frequency)表达。Map函数计算每一个输入文档(主机名字是从文档的URL取出的)的关键词向量,然后
输出(Hostname,关键词向量(TermVector))。Reduce函数处理所有相同主机的所有文档关键词向量。去掉不常用的关
键词,并且输出最终的(Hostname,关键词向量)对。
逆序索引:Map函数分析每一个文档,并且产生一个序列(Word,Documen tID)组。Reduce函数处理指定Word的所有
序列组,并且对相关的DocumentID进行排序,输出一个(Word,List(Documen tID))组。所有的输出组,组成一个简
单的逆序索引。通过这种方法可以很容易地保持关键词在文档库中的位置。
分布式排序:Map函数从每条记录中抽取关键字,并且产生(Key,Record)对。Reduce函数原样输出所有的关键字对。
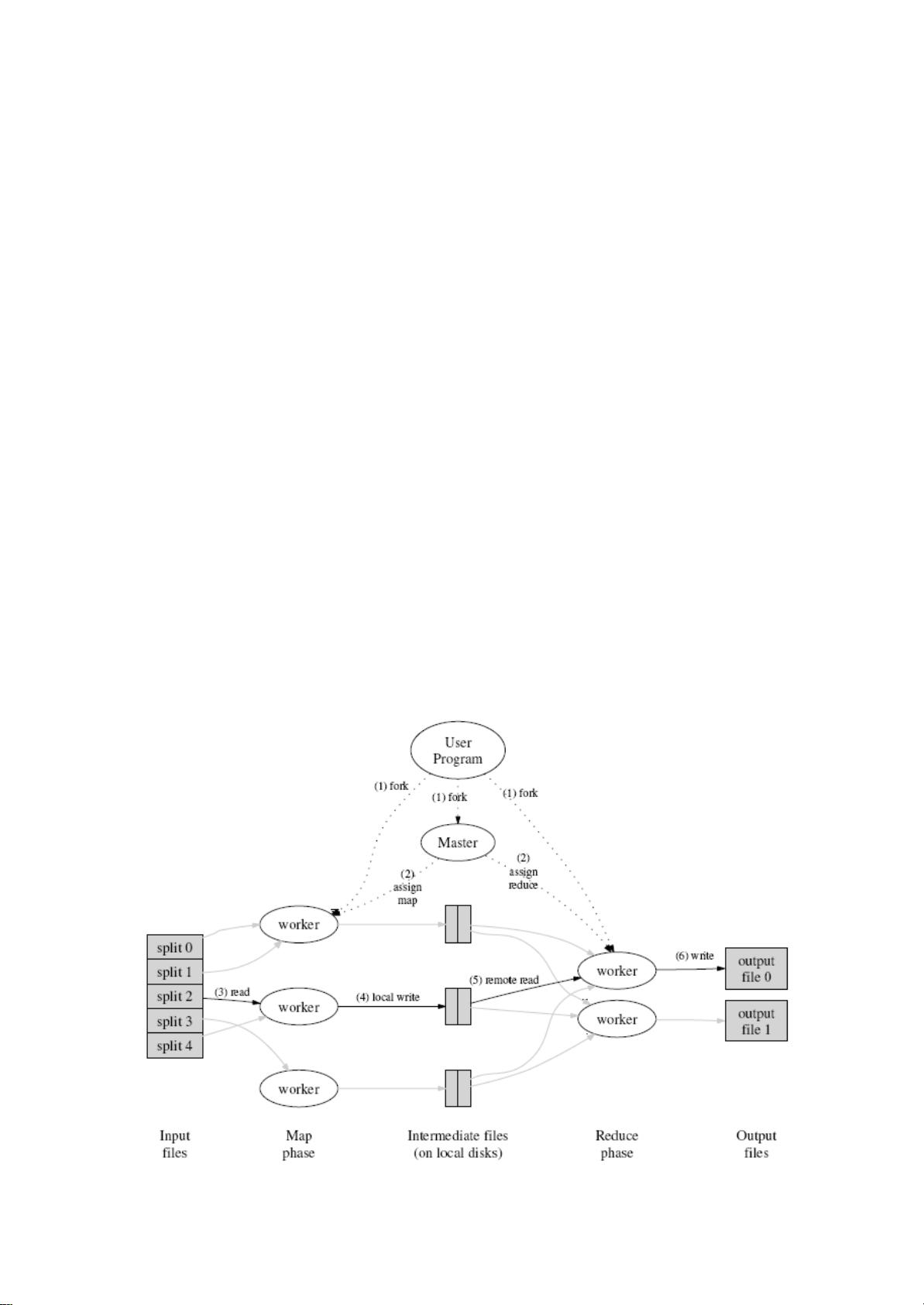
原理
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
132 浏览量
2012-03-20 上传
122 浏览量
2011-12-04 上传
114 浏览量
2021-06-22 上传

NinjaPanda
- 粉丝: 30
- 资源: 231
 我的内容管理
展开
我的内容管理
展开







