IBM-SPSS对应分析详解:揭示定性变量关联
版权申诉
173 浏览量
更新于2024-07-07
收藏 1.09MB PPT 举报
"IBM-SPSS第25章 对应分析.ppt"
对应分析是一种多元统计方法,由法国统计学家J.P.Benoit Beozecri在1970年提出,它结合了R型和Q型因子分析,主要用于揭示定性变量之间的联系。简单对应分析是对应分析的一个基础形式,它专注于分析两个分类变量之间的关系。这种分析方法通过将联列表的行和列中的元素比例结构映射到低维度空间的点,以便更直观地展示两个分类变量间的关系,类似于分类变量的典型相关分析。
在IBM SPSS软件中执行对应分析,用户需要依次点击“分析”、“降维”、“对应分析”。在对应分析对话框中,将研究中的分类变量分别放入“行”和“列”。例如,在案例中,"部位"放入“行”,"症状"放入“列”。
进一步的设置包括:
1. “定义范围”按钮允许用户为行和列设置特定的范围和条件。
2. “模型”按钮打开模型对话框,用户可以选择不同的模型类型以适应具体的研究需求。
3. “统计量”按钮通常不需要修改,但用户可以根据需要定制所需的统计信息。
4. “绘制”按钮则用于调整输出图形的设置,以便更好地展示分析结果。
在结果解读方面,对应分析的结果通常包括:
- 对应表,它相当于两个变量的交叉表,显示每个分类的个案分布。但仅凭此表无法直接看出变量间的关联。
- 统计摘要表,其中的“惯量”(特征值)是评估每个维度解释数据变异程度的指标。较高的惯量表示该维度对数据变异的贡献更大。
例如,如果最大维度为3(活动列变量类别数4减1),而第一维度的惯量为0.664,这是最高的,意味着第一维度在解释数据变异上最为重要。通过分析这些统计摘要,研究者可以理解哪些维度对揭示变量间关系最关键。
对应分析的图形输出,如散点图或双轴图,能够直观地展现行变量和列变量之间的相对位置,距离相近的点代表相关性较强,而距离较远的点则表示相关性较弱。这些图形对于非数值数据的可视化和解释非常有价值,可以帮助研究人员识别出哪些定性变量之间存在显著的相关性。
对应分析是一种强大的工具,尤其在处理分类变量时,它能帮助我们理解和揭示看似无关的定性变量之间的隐藏关系。在实际应用中,如上述案例中的大脑疾病研究,对应分析可以帮助找出特定症状与不同大脑部位损伤之间的关联,从而为医学研究和临床实践提供有价值的洞见。
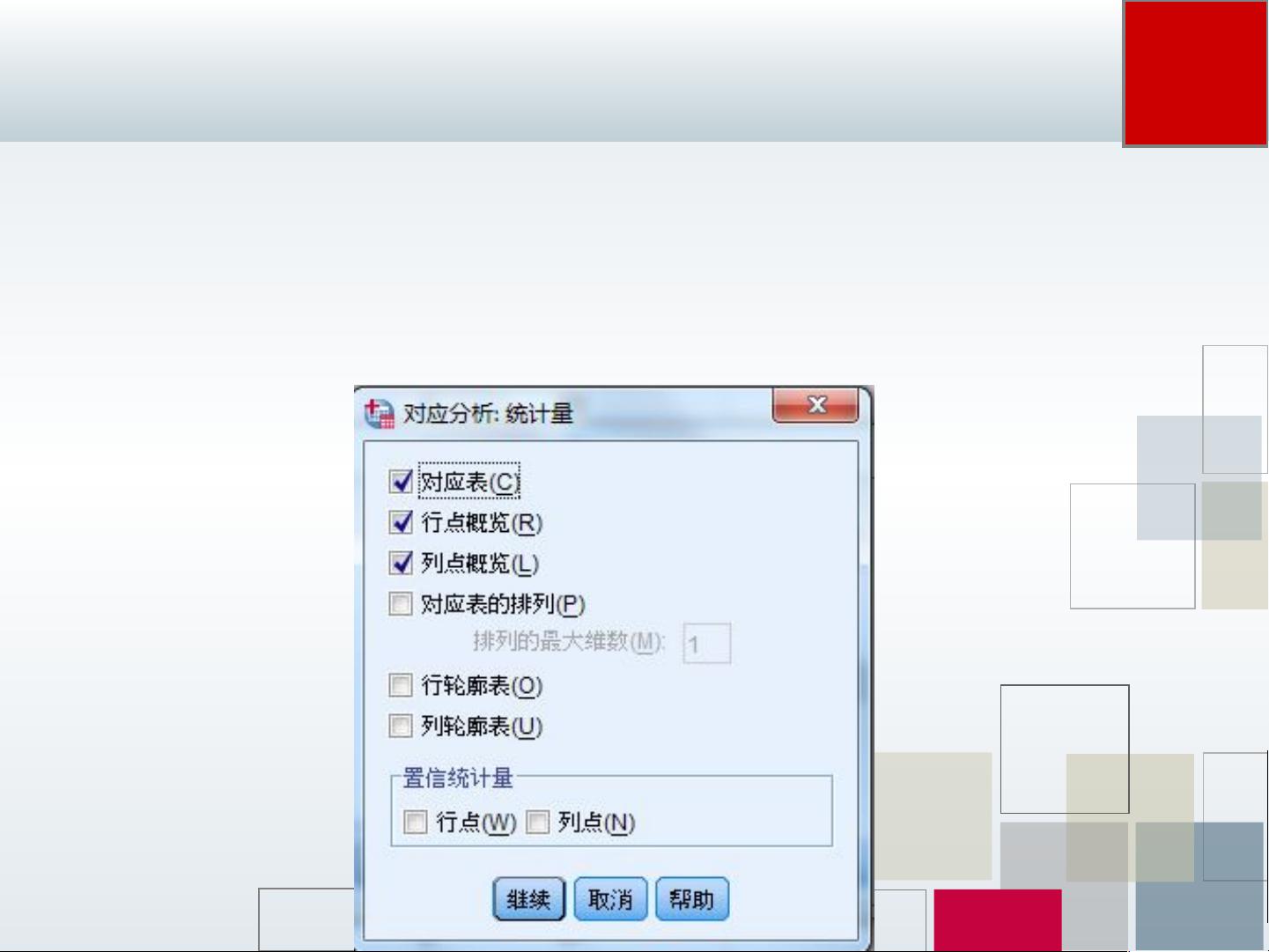
4 .“统计量”按钮
单击“统计量”按钮,弹出图 25-4 所示的“统计量”
对话框,此对话框一般不需要改动。
剩余43页未读,继续阅读
2023-07-05 上传
2021-12-23 上传
2021-11-06 上传
2021-11-16 上传
2021-10-29 上传
2022-06-18 上传
2022-06-29 上传
2021-12-23 上传
2021-10-11 上传

等天晴i
- 粉丝: 5881
- 资源: 10万+
 我的内容管理
展开
我的内容管理
展开







