华为Uma Maheshwara Rao G探讨HDFS NameNode的高可用性关键技术
需积分: 9 7 浏览量
更新于2024-07-23
收藏 941KB PDF 举报
在2012年的HBTC会议上,来自华为电信与核心网产品线BigData团队的架构师Uma Maheshwara Rao G,以其深厚的专业背景和丰富的HDFS开发经验,分享了关于HDFS Name Node高可用性的深入研究。作为HDFS的核心设计者之一,Maheshwara在演讲中详细探讨了HDFS Name Node在不同版本中的高可用性策略,尤其是在Hadoop-2中,他重点介绍了基于BookKeeper的Name Node高可用性解决方案。
Hadoop-2时代的HDFS Name Node高可用性设计中,BookKeeper被用作共享存储,提供了一种可靠的方式来确保Name Node服务的连续性和数据完整性。BookKeeper的分布式一致性特性使得在主Name Node(Active NN)发生故障时,能够快速选举新的Active NN,实现无感知的服务切换。这一过程中,BookKeeper不仅支持智能客户端自动发现并连接到有效的Name Node,还通过流式更新备份Name Node(Backup NN)以及定期的数据一致性检查点,确保数据的一致性和恢复能力。
此外,演讲者还回顾了他们在2011年为Hadoop 0.20.1引入Name Node高可用性(基于Backup NN和ZooKeeper)的工作,其中关键功能包括:
1. 客户端智能地从配置的Name Node列表中找到活动节点。
2. 实现对Backup NN的实时编辑同步。
3. 同时向活动Name Node和Backup NN发送块报告,增强数据冗余。
4. Backup NN进行定期数据备份,确保数据持久性。
5. 依赖ZooKeeper进行领导选举,实现快速故障转移和热备份。
Maheshwara的贡献体现在他所修复的超过500个Hadoop缺陷,并将这些改进回馈给社区,进一步提升了HDFS的整体稳定性和可靠性。他的工作涵盖了Hadoop生态系统中的多个组件,如HBase的次级索引、YARN中的MapReduce资源管理器HA、Hadoop-1中的Job Tracker HA以及Hive的高可用性开发,展示了他在Hadoop领域的全面影响力和专业知识。Maheshwara的演讲深入剖析了HDFS Name Node高可用性的实现技术,为Hadoop用户和开发者提供了宝贵的学习资源。
HUAWEI TECHNOLOGIES CO., LTD.
Slide title :32-35pt
Color: R153 G0 B0
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Slide text :20-22pt
Bullets level 2-5:
18pt
Color:Black
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Top right corner
for field-mark,
customer or partner
logotypes.
----------------
The following nine
groups of colors
are an example of
how our design
colors can be used,
please take note
that you should
only use one
design color group
per slide.
For specific usage
details, refer to the
“Typesetting
Standard”.
Page 5
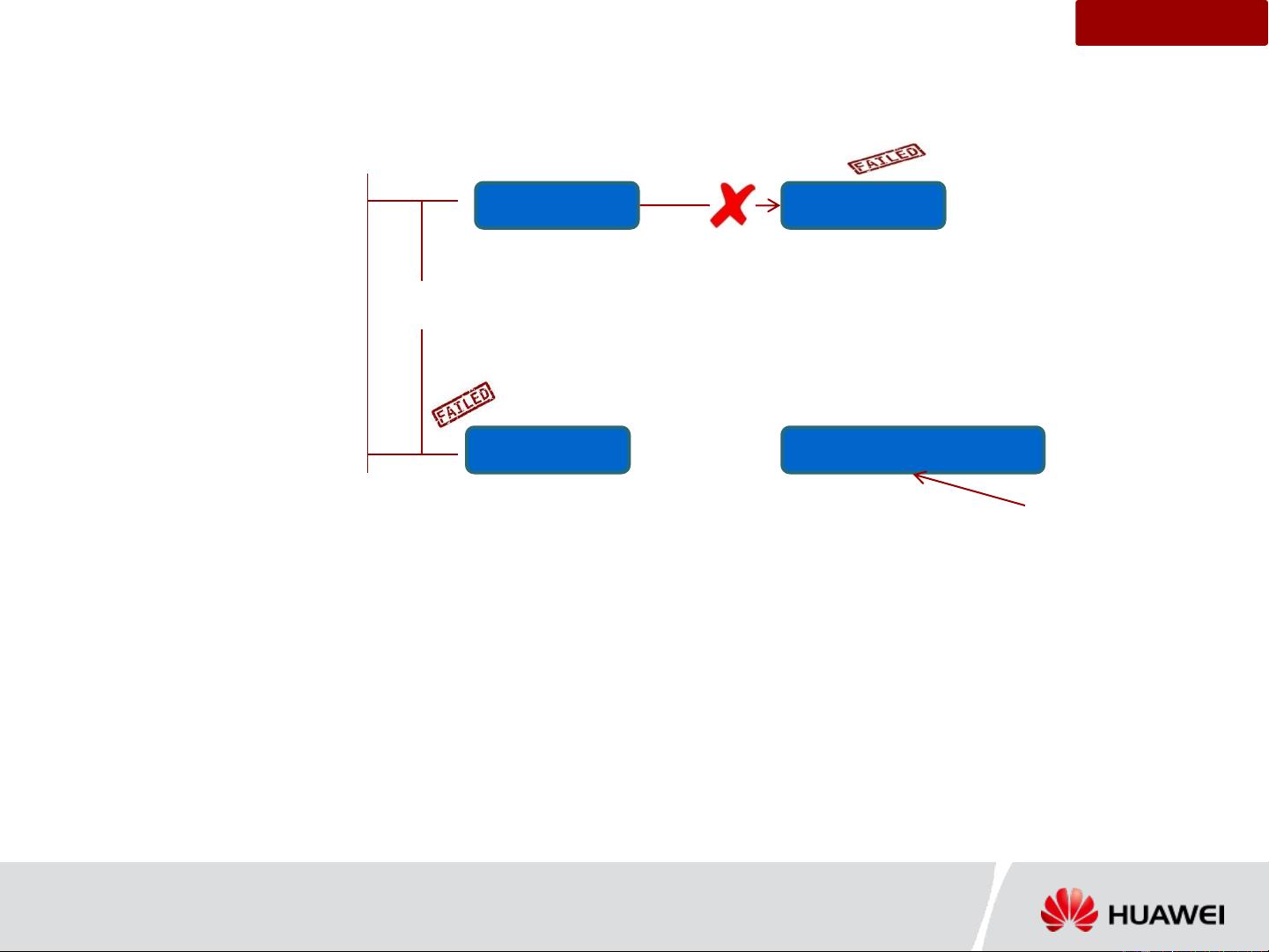
What is Double Failure here?
Active NN
Backup NN
Active NN Start - Active NN
Checkpoint – t1
Checkpoint – t2
NN-1
NN-2
NN-1 NN-2
X - Operation logs in NN1 and could not stream to
BNN (NN2)
Not aware of X - Operation logs
from NN1. DataLoss!!!
NN1 is active and NN2 is Backup node
NN1 failed to stream edits to the Backup node and removed the stream
NN1 received X- operation edit logs, where NN2 not aware of them
Now NN1 crashed, NN2 becomes active
NN2 continues to work but not aware of the edits after checkpoint:t1
NameNode HA
剩余20页未读,继续阅读
2021-06-01 上传
2023-10-17 上传
2023-04-28 上传
2023-08-15 上传
2023-05-19 上传
2023-07-30 上传
2023-09-04 上传
2023-07-12 上传
2023-12-29 上传

阿斗
- 粉丝: 28
- 资源: 167
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
