Spark作业调度详解:从逻辑执行图到计算链
需积分: 10 29 浏览量
更新于2024-09-12
收藏 5.57MB PDF 举报
"Spark作业调度涉及RDD的创建、转换、行动操作以及依赖关系的构建,是Spark处理数据的核心流程。"
Spark作业调度是大数据处理框架Spark中的关键环节,它负责组织和协调数据处理任务,确保高效、可靠地完成计算。在Spark中,数据是以弹性分布式数据集(Resilient Distributed Dataset,简称RDD)的形式存在。RDD是不可变的、分区的数据集合,具备容错能力。
1. **RDD的创建与转换**
- **创建**: 通过`parallelize()`或`createRDD()`方法从数据源创建初始RDD。数据源可以是本地文件、内存数据结构、HDFS、HBase等。例如,`parallelize()`用于将Java或Scala集合转化为RDD。
- **转换**: RDD支持一系列转换操作,如`map()`、`filter()`、`reduceByKey()`等,这些转换会产生新的RDD。转换操作不会立即执行,而是形成一个任务链,只有当执行行动操作时才会触发计算。
2. **RDD的依赖关系**
- **宽依赖与窄依赖**: RDD间的依赖关系分为两类,宽依赖(全连接依赖)和窄依赖(一对一或一对多依赖)。窄依赖可以在一个分区上并行计算,而宽依赖则需要等待所有父RDD分区计算完毕。理解依赖关系对于优化调度至关重要。
3. **行动操作**
- **行动**: 如`count()`、`collect()`、`saveAsTextFile()`等,它们触发实际的计算并将结果返回给Driver程序或存储到外部系统。`count()`不仅包括`action()`,还包括内部的`sum()`计算。
4. **RDD缓存与检查点**
- **缓存**: `cache()`或`persist()`方法用于将RDD持久化到内存,提高后续重用时的效率。可以选择不同级别的持久化策略,如内存、磁盘甚至跨节点复制。
- **检查点**: `checkpoint()`用于将RDD写入磁盘,提供故障恢复,特别是在大规模数据处理中。
5. **计算逻辑与compute()方法**
- **计算**: 每个RDD都有`compute()`方法,它负责执行来自上一RDD的输入记录的转换操作,并生成输出记录。计算逻辑根据所应用的转换操作来确定。
6. **优化与调度**
- **Stage划分**: Spark通过将宽依赖作为切割点,将任务划分为Stage,每个Stage内的任务可以并行执行,以优化性能。
- **Task调度**: Spark的DAGScheduler和TaskScheduler负责将任务分解为Task并分配到集群的Executor上执行。
理解Spark作业调度的工作原理有助于编写更高效的Spark程序,包括合理安排RDD的创建、转换和行动操作,以及充分利用Spark的并行计算能力和容错机制。通过深入学习和实践,开发者能够更好地控制和优化Spark作业,以满足大数据处理的需求。
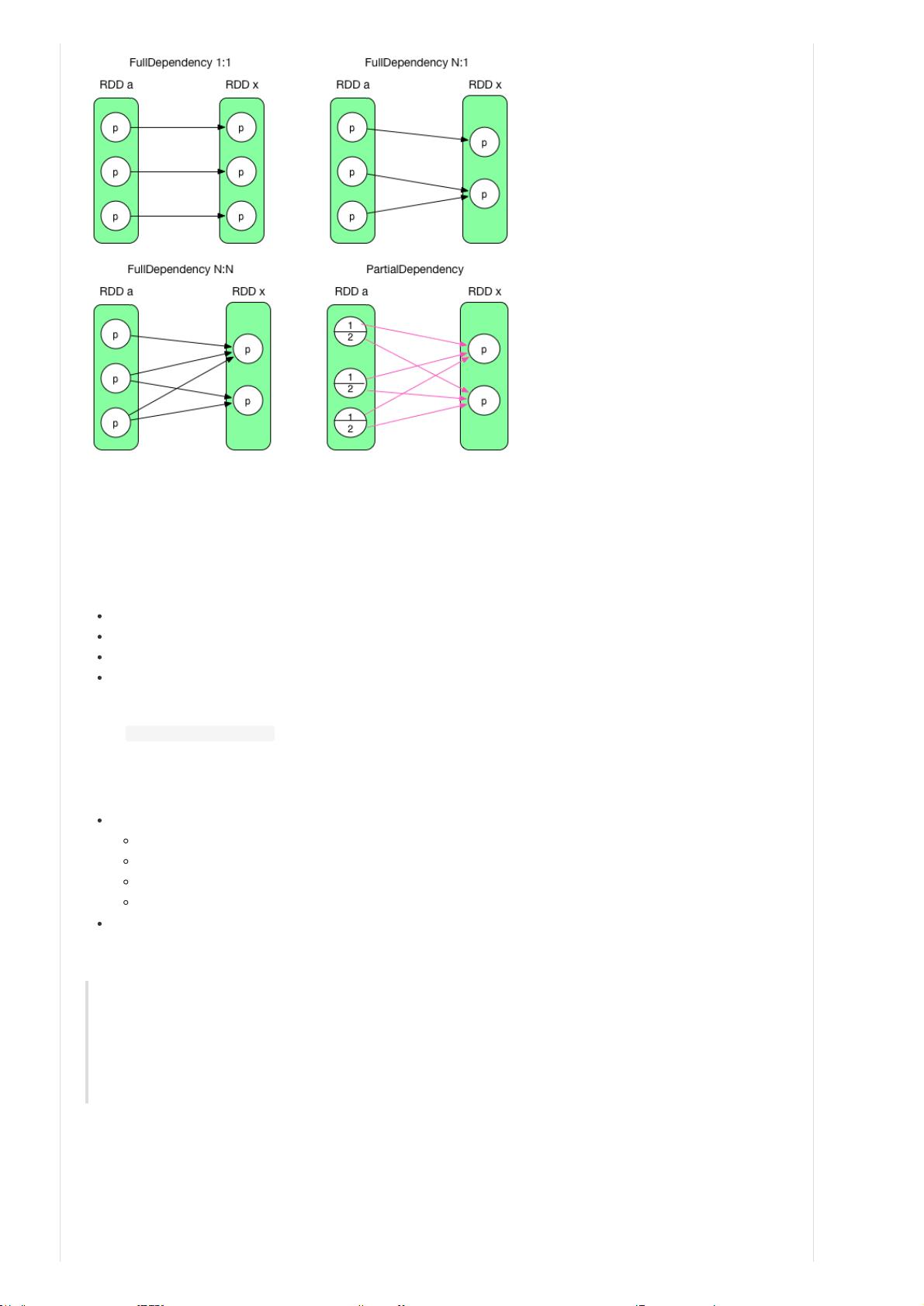
前三个是完全依赖,RDD x 中的 partition 与 parent RDD 中的 partition/partitions 完全相关。最后一个是部分依赖,RDD
x 中的 partition 只与 parent RDD 中的 partition 一部分数据相关,另一部分数据与 RDD x 中的其他 partition 相关。
在 Spark 中,完全依赖被称为 NarrowDependency,部分依赖被称为 ShuffleDependency。其实 ShuffleDependency 跟
MapReduce 中 shuffle 的数据依赖相同(mapper 将其 output 进行 partition,然后每个 reducer 会将所有 mapper 输出中
属于自己的 partition 通过 HTTP fetch 得到)。
第一种 1:1 的情况被称为 OneToOneDependency。
第二种 N:1 的情况被称为 N:1 NarrowDependency。
第三种 N:N 的情况被称为 N:N NarrowDependency。不属于前两种情况的完全依赖都属于这个类别。
第四种被称为 ShuffleDependency。
对于 NarrowDependency,具体 RDD x 中的 partitoin i 依赖 parrent RDD 中一个 partition 还是多个 partitions,是由 RDD
x 中的 getParents(partitioni) 决定(下图中某些例子会详细介绍)。还有一种 RangeDependency 的完全依赖,不过
该依赖目前只在 UnionRDD 中使用,下面会介绍。
所以,总结下来 partition 之间的依赖关系如下:
NarrowDependency (使用黑色实线或黑色虚线箭头表示)
OneToOneDependency (1:1)
NarrowDependency (N:1)
NarrowDependency (N:N)
RangeDependency (只在 UnionRDD 中使用)
ShuffleDependency (使用红色箭头表示)
之所以要划分 NarrowDependency 和 ShuffleDependency 是为了生成物理执行图,下一章会具体介绍。
需要注意的是第三种 NarrowDependency (N:N) 很少在两个 RDD 之间出现。因为如果 parent RDD 中的 partition 同
时被 child RDD 中多个 partitions 依赖,那么最后生成的依赖图往往与 ShuffleDependency 一样。只是对于 parent
RDD 中的 partition 来说一个是完全依赖,一个是部分依赖,而箭头数没有少。所以 Spark 定义的 NarrowDepedency
其实是 “each partition of the parent RDD is used by at most one partition of the child RDD“,也就是只有
OneToOneDependency (1:1) 和 NarrowDependency (N:1) 两种情况。但是,自己设计的奇葩 RDD 确实可以呈现出
NarrowDependency (N:N) 的情况。这里描述的比较乱,其实看懂下面的几个典型的 RDD 依赖即可。
如何计算得到 RDD x 中的数据(records)?下图展示了 OneToOneDependency 的数据依赖,虽然 partition 和 partition
之间是 1:1,但不代表计算 records 的时候也是读一个 record 计算一个 record。 下图右边上下两个 pattern 之间的差别类
似于下面两个程序的差别:
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-02-29 上传
点击了解资源详情
2024-06-28 上传
2017-03-10 上传
2021-05-16 上传
点击了解资源详情

tianbianlan
- 粉丝: 3
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- ATT7022B-programe,网络验证c语言源码,c语言
- Utils:一些实用程序
- chatomud
- configs:基于UNIX的点文件
- Feminazi a flor-crx插件
- 802.11b PHY Simulink 模型:802.11b 基带物理层的 Simulink:registered: 模型。-matlab开发
- SQLITE
- CpuTimer0,c语言read源码,c语言
- java-projects
- 오늘의 운세-crx插件
- technical-community-builders:雇用技术社区建设者的公司
- csrf_attack_example
- grpar:提取构建引擎组(.grp)文件的工具-开源
- Backjoon
- 每日日记:一种日记应用程序,融合了我在编码过程中所学到的技术
- AT89C2051UPS,c语言输出图形源码,c语言
