数据挖掘深度解析:分类技术与应用
需积分: 9 93 浏览量
更新于2024-07-26
收藏 1.81MB PPT 举报
"数据挖掘——分类"
数据挖掘是一种从大量数据中发现有价值信息的过程,而分类是其中一种核心的方法。分类技术主要用于预测未知数据的类别,通过对已知数据(训练集)的学习,构建一个模型,该模型能根据输入的属性值来决定其所属的类别。在分类过程中,每个记录都包含一组属性,其中一个属性被称为类标,即我们想要预测的目标。
分类的定义:
给定一个记录集合(训练集),每个记录都有若干个属性,其中一个是类标。分类的目的是找到一个模型,将其他属性的值作为输入,来预测类标。这个模型的目标是在未见过的新记录上进行预测时,尽可能准确地分配类别。为了评估模型的准确性,通常会将原始数据集划分为训练集和测试集,用训练集构建模型,然后用测试集验证模型的效果。
分类任务实例:
1. 预测肿瘤细胞是良性还是恶性。
2. 判断信用卡交易是否合法或欺诈。
3. 将新闻故事归类为金融、天气、娱乐、体育等不同类别。
4. 对蛋白质的二级结构进行分类,如α螺旋、β折叠或无规卷曲。
分类技术主要包括以下几种方法:
1. 决策树方法:通过创建分枝结构来表示属性值与类别之间的关系,如ID3、C4.5和CART算法。
2. 规则基方法:建立一组规则来描述类别的特征,如CRI和M5。
3. 基于记忆的推理:利用相似案例的已有结果来预测新案例的类别,如K近邻(K-NN)算法。
4. 神经网络:通过模拟大脑神经元的工作方式来学习和预测,包括多层感知器和自组织映射。
5. 朴素贝叶斯和贝叶斯信念网络:基于贝叶斯定理,利用条件概率来预测类别。
6. 支持向量机(SVM):寻找最大边距超平面,以区分不同类别。
在实际应用中,选择哪种分类技术取决于问题的特性、数据的规模、预测精度的要求以及计算资源。每种方法都有其优势和局限性,例如决策树易于理解和解释,但可能过拟合;K-NN简单但计算复杂度高;而SVM在处理高维数据时表现优秀,但训练时间较长。
在数据挖掘过程中,模型的评估是至关重要的。常见的评估指标包括准确率、召回率、F1分数、混淆矩阵等。此外,还有交叉验证、网格搜索等技术用于参数调优,以提高模型的泛化能力。
总结来说,分类数据挖掘是通过分析历史数据构建模型,用于对未知数据进行预测分类的技术。它涵盖多种方法,并在各种领域如医学、金融、新闻分析等方面有着广泛的应用。理解并熟练掌握这些方法,对于提升数据分析和预测的准确性具有重要意义。
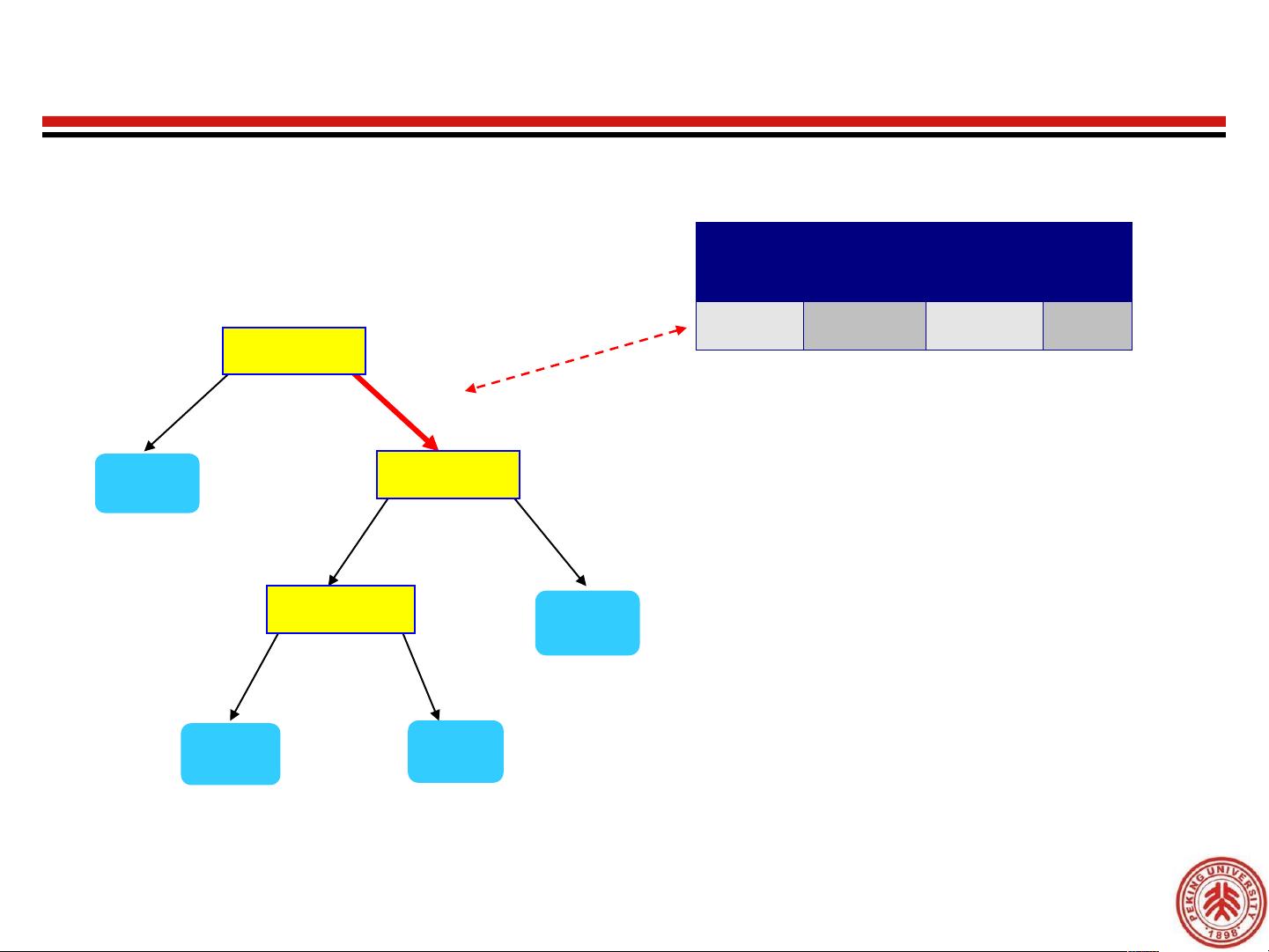
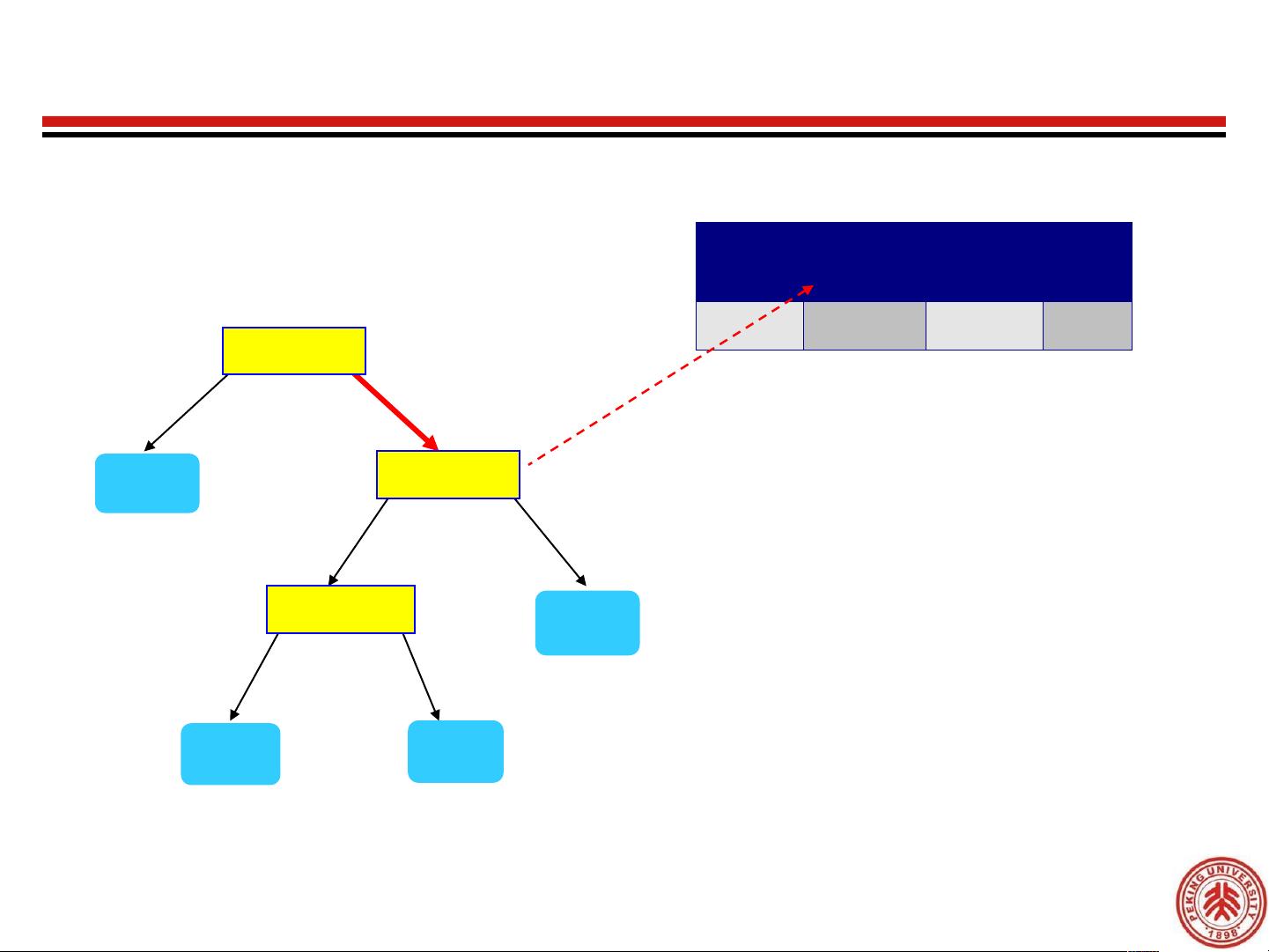
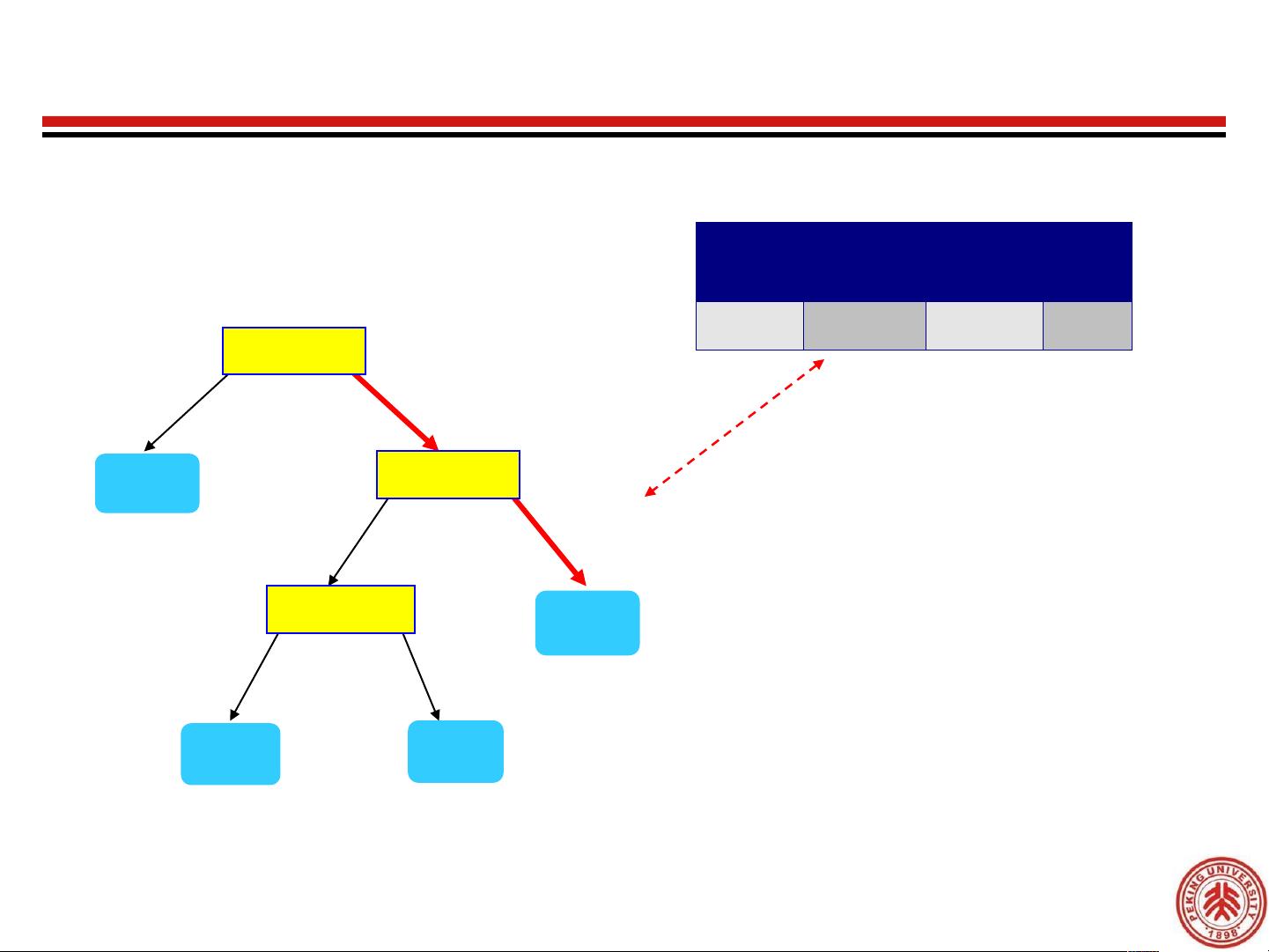
Apply Model to Test Data
Refund
MarSt
TaxInc
YES
NO
NO
NO
Yes No
Married
Single, Divorced
< 80K > 80K
Refund Marital
Status
Taxable
Income
Cheat
No Married 80K
?
10
Test Data
剩余63页未读,继续阅读
2011-10-05 上传
2008-12-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-12-06 上传
2023-09-08 上传
2023-05-19 上传

春水照夜白
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
