KMP算法详解:提升字符串匹配效率的关键
需积分: 5 199 浏览量
更新于2024-06-15
收藏 484KB DOCX 举报
KMP算法,全称为克努特—莫里斯—普拉特算法,是一种高效的字符串匹配算法,最初由计算机科学家D.E.Knuth、J.H.Morris和V.R.Pratt提出。相较于暴力的逐字符比较方法,KMP算法通过优化搜索策略,显著减少了匹配次数,从而降低时间复杂度,达到O(m+n)的性能,其中m和n分别为模式串(子串)和主串的长度。
该算法的核心思想是利用模式串的局部匹配信息,通过预处理生成一个名为next数组的数据结构。next数组记录了在模式串中,当发生不匹配时,为了保持匹配过程的连续性,应该跳过多少个字符的索引。例如,当比较过程中遇到不匹配,根据next数组,模式串会直接跳过一个或多个已知匹配的字符,而不是重新从头开始。
在暴力法中,当i和j指针不匹配时,会退回至之前的匹配位置并各自向右移动;而在KMP算法中,不匹配时会根据next数组找到一个新的起始位置,避免重复比较。这使得算法能够在大部分情况下只遍历一次主串,即使不完全匹配也能保持高效。
理解KMP算法的关键在于理解next数组的构建过程,通常通过以下步骤:
1. 初始化next数组,对于第一个字符,next[0]总是0,表示没有前一个字符可以参考。对于后续的每个字符,next[i]等于最长的前缀和后缀相等子串的长度,或者在模式串中找不到这样的子串时,设置为0。
2. 当在主串和模式串的比较过程中遇到不匹配时,检查next[j],它指示在模式串中应该跳过的字符数量。将模式串的指针j更新为next[j],然后继续比较主串的下一个字符。
3. 如果模式串的j指针到达了子串末尾,说明找到了一个匹配,记录下主串中的起始位置,然后从下一个字符继续匹配。
4. 若主串的长度小于模式串,KMP算法依然能找到所有可能的匹配位置,因为每次不匹配都会缩小搜索范围。
KMP算法的代码实现并不难,但理解其原理和背后的逻辑至关重要。掌握这种算法不仅可以提高字符串匹配的效率,还可以应用于其他类似问题,如正则表达式匹配和文本处理等领域。学习KMP算法时,理解next数组的动态构建和应用是核心,同时也需要通过实践来巩固理解。
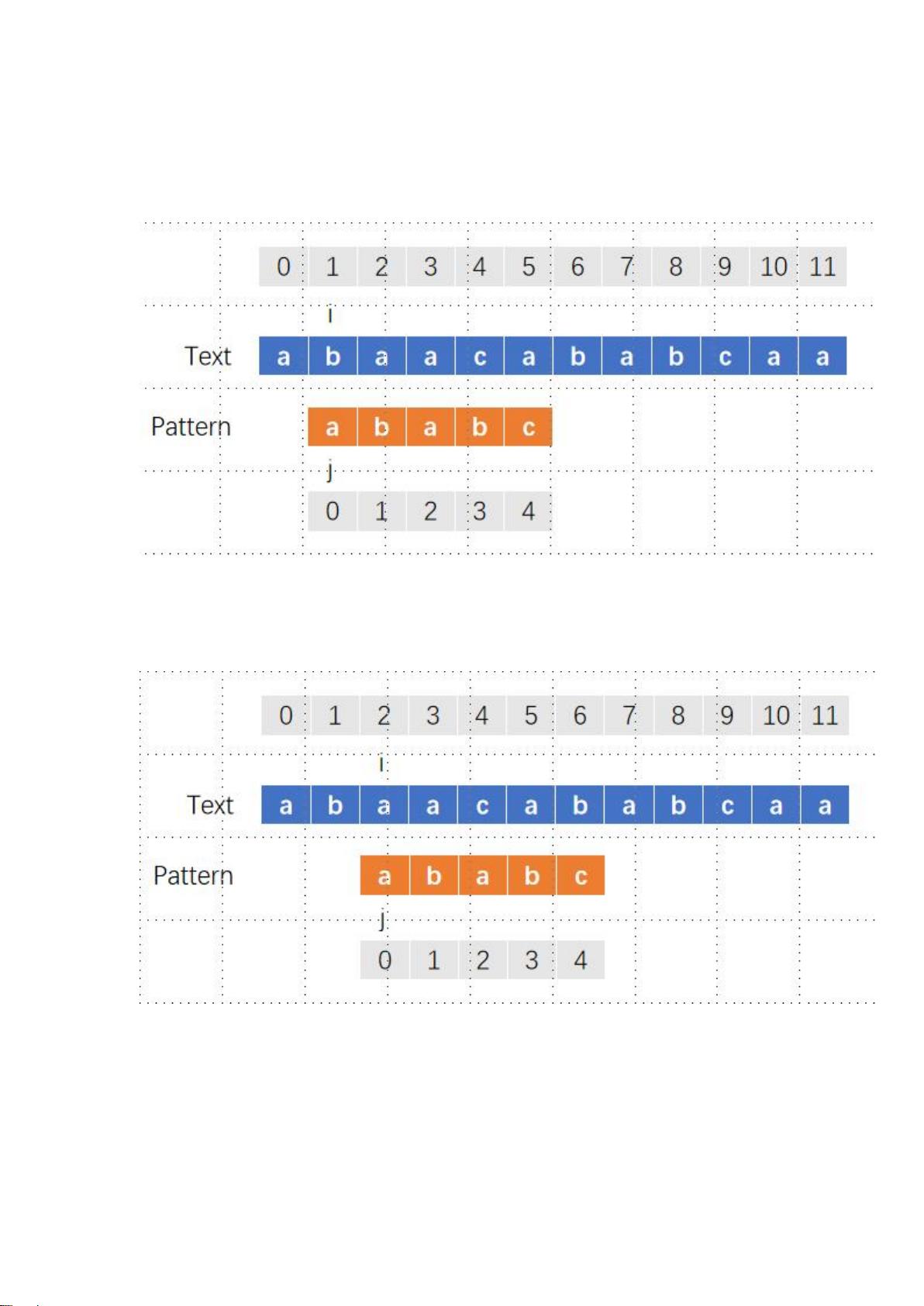
此时 i 和 j 不匹配了,需要对 i 和 j 进行回退,i 回退到了它最开始的
下一位置,即位置 1,而 j 回退到位置 0
此时 i 和 j 仍然不匹配,i 继续向右移动一格,即位置 2,j 依然保持
位置 0
如此反复,每当不匹配时,i 都会回到开始匹配的位置同时移动一格,
而 j 回到位置 0,当匹配时,i 和 j 同时向右移动,直到 j 到达子字符
串的末尾。
剩余14页未读,继续阅读
2023-04-01 上传
2024-04-13 上传
2023-03-31 上传
2024-07-29 上传
2023-09-08 上传
2023-09-17 上传

xiaoshun007~
- 粉丝: 3947
- 资源: 3118
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
