端到端几何推理:发现3D关键点的新方法
需积分: 15 127 浏览量
更新于2024-09-07
收藏 1.65MB PDF 举报
"《端到端几何推理:发现隐性3D关键点》
本文介绍了一种由Google AI的Supasorn Suwajanakorn等人提出的创新方法——KeypointNet,这是一项针对关键点检测的全新框架,特别关注于3D关键点的学习和探测。在计算机视觉领域,关键点检测是众多任务的核心,如人脸识别、动作识别和自动驾驶等,因为它能够提取出图像中的关键特征点,有助于理解物体的位置、形状和运动。
KeypointNet采用端到端(end-to-end)学习的方式,通过几何推理来寻找最适合下游任务的3D关键点。不同于传统的依赖于大量标注数据的方法,KeypointNet能够在没有预设关键点标注的情况下自我学习和优化关键点集,这对于实际应用中的数据稀缺情况具有显著优势。其核心目标是设计一个可微分的目标函数,用于寻找两个物体视图之间相对姿态的最佳关键点组合,确保在不同视角和对象实例间保持几何和语义的一致性。
实验主要集中在3D姿态估计上,通过与使用相同神经网络架构但完全监督的学习模型进行比较,结果显示KeypointNet在无标注关键点的条件下,性能超越了标准的全监督方法。这表明该框架不仅能够在任务执行上达到或超过已知标准,而且具有更高的灵活性和适应性。
具体来说,KeypointNet在ShapeNet数据集中,如汽车、椅子和飞机类别上展示了它发现的3D关键点。这些关键点对于理解这些物体的三维结构至关重要,它们能够提供丰富的信息,支持诸如物体识别、匹配和重构等高级计算机视觉任务。可视化结果可以在keypointnet.github.io上查看,进一步证实了该模型的强大功能和实用性。
总结来说,KeypointNet的提出代表了一种突破性的技术,它通过端到端的几何推理,实现了3D关键点的自主学习和高效检测,为未来的计算机视觉研究和实际应用开辟了新的可能性。这种无监督学习方法的优势在于它的泛化能力和对数据需求的降低,有望推动关键点检测领域的进步,并促进更广泛的3D计算机视觉任务的发展。"
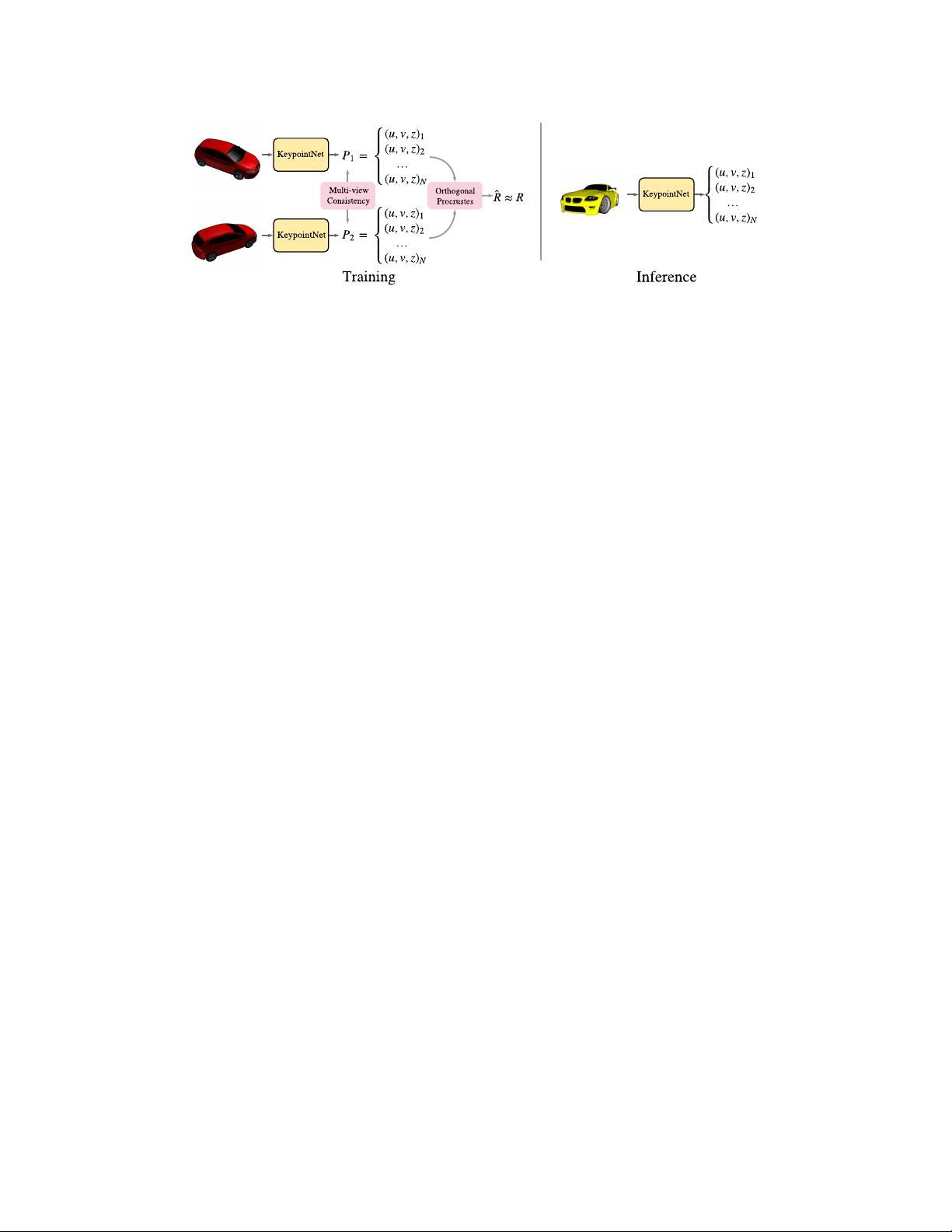
Figure 1: During training, two views of the same object are given as input to the KeypointNet. The
known rigid transformation
(R, t)
between the two views is provided as a supervisory signal. We
optimize an ordered list of 3D keypoints that are consistent in both views and enable recovery of the
transformation. During inference, KeypointNet extracts 3D keypoints from an individual input image.
by a predefined 3D descriptor. Zhou et al. [
61
] use view-consistency as a supervisory signal to predict
3D keypoints, although only on depth maps. Similarly, Su et al. [
43
] leverage synthetically rendered
models to estimate object viewpoint by matching them to real-world image via CNN viewpoint
embedding.
3 End-to-end Optimization of 3D Keypoints
Given a single image of a known object category, our model predicts an ordered list of 3D keypoints,
defined as pixel coordinates and associated depth values. Such keypoints are required to be geometri-
cally and semantically consistent across different viewing angles and instances of an object category
(e.g., see Figure 4). Our KeypointNet has
N
heads that extract
N
keypoints, and the same head tends
to extract 3D points with the same semantic interpretation. These keypoints will serve as a building
block for feature representations based on a sparse set of points, useful for geometric reasoning and
pose-aware or pose-invariant object recognition (e.g., [38]).
In contrast to approaches that learn a supervised mapping from images to a list of annotated keypoint
positions, we do not define the keypoint positions a priori. Instead, we jointly optimize keypoints
with respect to a downstream task. We focus on the task of relative pose estimation at training
time, where given two views of the same object with a known rigid transformation
T
, we aim to
predict optimal lists of 3D keypoints,
P
1
and
P
2
in the two views that best match one view to the
other (Figure 1). We formulate an objective function
O(P
1
, P
2
)
, based on which one can optimize
a parametric mapping from an image to a list of keypoints. Our objective consists of two primary
components:
•
A multi-view consistency loss that measures the discrepancy between the two sets of points
under the ground truth transformation.
•
A relative pose estimation loss, which penalizes the angular difference between the ground
truth rotation R vs. the rotation
ˆ
R recovered from P
1
and P
2
using orthogonal procrustes.
We demonstrate that these two terms allow the model to discover important keypoints, some of which
correspond to semantically meaningful locations that humans would naturally select for different
object classes. Note that we do not directly optimize for keypoints that are semantically meaningful,
as those may be sub-optimal for downstream tasks or simply hard to detect. In what follows, we first
explain our objective function and then describe the neural architecture of KeypointNet.
Notation.
Each training tuple comprises a pair of images
(I, I
0
)
of the same object from differ-
ent viewpoints, along with their relative rigid transformation
T ∈ SE(3)
, which transforms the
underlying 3D shape from I to I
0
. T has the following matrix form:
T =
R
3×3
t
3×1
0 1
, (1)
where
R
and
t
represent a 3D rotation and translation respectively. We learn a function
f
θ
(I)
,
parametrized by
θ
, that maps a 2D image
I
to a list of 3D points
P = (p
1
, . . . , p
N
)
where
p
i
≡
(u
i
, v
i
, z
i
), by optimizing an objective function of the form O(f
θ
(I), f
θ
(I
0
)).
3
剩余12页未读,继续阅读
2021-05-14 上传
2018-01-28 上传
2021-05-28 上传
2021-05-28 上传
2018-01-28 上传
2021-02-11 上传
2021-02-08 上传
2018-04-19 上传

huyiqun6
- 粉丝: 1
- 资源: 40
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
