MapReduce公平调度器详解:多用户集群中的JobScheduling
需积分: 9 48 浏览量
更新于2024-07-17
收藏 830KB PDF 举报
MapReduce: Fair Scheduler前传是一篇由Matei Zaharia、Dhruba Borthakur、Joydeep Sen Sarma、Khaled Elmeleegy、Scott Shenker和Ion Stoica共同完成的技术报告,发表于2009年4月30日,由University of California at Berkeley的Electrical Engineering and Computer Sciences系发布,编号为UCB/EECS-2009-55。这篇论文着重探讨了在多用户MapReduce集群中的作业调度问题,这是Google分布式计算框架Hadoop的核心组件之一。
在多用户环境中,MapReduce集群需要处理来自不同用户或应用的各种任务,如何公平地分配计算资源并确保效率是关键挑战。Fair Scheduler的设计目标是为了解决这个问题,它引入了一种新的调度算法,旨在平衡资源分配,使得各个作业能够在有限的时间内得到合理的处理,同时考虑到作业的优先级、历史性能和资源需求等因素。
报告详细分析了传统MapReduce调度器存在的不足,比如可能导致某些任务长时间等待或资源浪费。作者们通过实践经验和理论分析,提出了一种动态调整策略,根据作业的历史表现和当前系统状态,实时优化任务调度决策。他们借鉴了数据库系统的相关工作,并得到了Yahoo!和Facebook等公司Hadoop团队的实际经验支持。
Fair Scheduler的特点包括:
1. **资源利用率**:通过优先级队列和资源预留机制,确保关键任务和新提交的任务能够获得所需的资源,提高整体系统利用率。
2. **公平性**:根据每个作业的运行时间、失败率和所需资源量,动态调整其优先级,避免长期排队的作业被忽视。
3. **适应性**:根据作业的实时性能数据调整调度策略,如任务分割、重试和回退,以应对不断变化的工作负载。
4. **透明性**:对用户来说,调度过程是透明的,他们无需关注底层的复杂调度逻辑,只需提交作业即可。
5. **可扩展性**:设计上考虑到了集群规模的扩展,能够有效处理大规模分布式环境下的任务调度问题。
这篇论文的研究成果不仅对Hadoop生态系统产生了深远影响,还为后续的分布式计算系统提供了宝贵的参考,特别是在资源管理和公平调度方面。对于那些从事大数据处理、云计算或分布式系统开发的工程师来说,理解并应用Fair Scheduler的原则和技术是提升系统性能和用户体验的关键。
like Torque [12], significantly degrade performance, be-
cause files in Hadoop are distributed across all nodes as
in GFS [19]. Grid schedulers like Condor [22] support lo-
cality constraints, but only at the level of geographic sites,
not of machines, because they run CPU-intensive appli-
cations rather than data-intensive workloads like MapRe-
duce. Even with a granular fair scheduler, we found that lo-
cality suffered in two situations: concurrent jobs and small
jobs. We address this problem through a technique called
delay scheduling that can double throughput.
The second aspect of MapReduce that causes problems
is the dependence between map and reduce tasks: Re-
duce tasks cannot finish until all the map tasks in their
job are done. This interdependence, not present in tradi-
tional cluster scheduling models, can lead to underutiliza-
tion and starvation: a long-running job that acquires reduce
slots on many machines will not release them until its map
phase finishes, starving other jobs while underutilizing the
reserved slots. We propose a simple technique called copy-
compute splitting to address this problem, leading in 2-10x
gains in throughput and response time. The reduce/map de-
pendence also creates other dynamics not present in other
settings: for example, even with well-behaved jobs, fair
sharing in MapReduce can take longer to finish a batch
of jobs than FIFO; this is not true environments, such as
packet scheduling, where fair sharing is work conserving.
Yet another issue is that intermediate results produced by
the map phase cannot be deleted until the job ends, con-
suming disk space. We explore these issues in Section 7.
Although we motivate our work with the Facebook case
study, the problems we address are by no means con-
strained to a data warehousing workload. Our contacts at
another major web company using Hadoop confirm that
the biggest complaint users have about the research clus-
ters there is long queueing delays. Our work is also rel-
evant to the several academic Hadoop clusters that have
been announced. One such cluster is already using our fair
scheduler on 2000 nodes. In general, effective scheduling
is more important in data-intensive cluster computing than
in other settings because the resource being shared (a clus-
ter) is very expensive and because data is hard to move (so
data consolidation provides significant value).
The rest of this paper is organized as follows. Section 2
provides background on Hadoop and problems with previ-
ous scheduling solutions for Hadoop, including a Torque-
based scheduler. Section 3 presents our fair scheduler.
Section 4 describes data locality problems and our delay
scheduling technique to address them. Section 5 describes
problems caused by reduce/map interdependence and our
copy-compute splitting technique to mitigate them. We
evaluate our algorithms in Section 6. Section 7 discusses
scheduling tradeoffs in MapReduce and general lessons for
job scheduling in cluster programming systems. We survey
related work in Section 8 and conclude in Section 9.
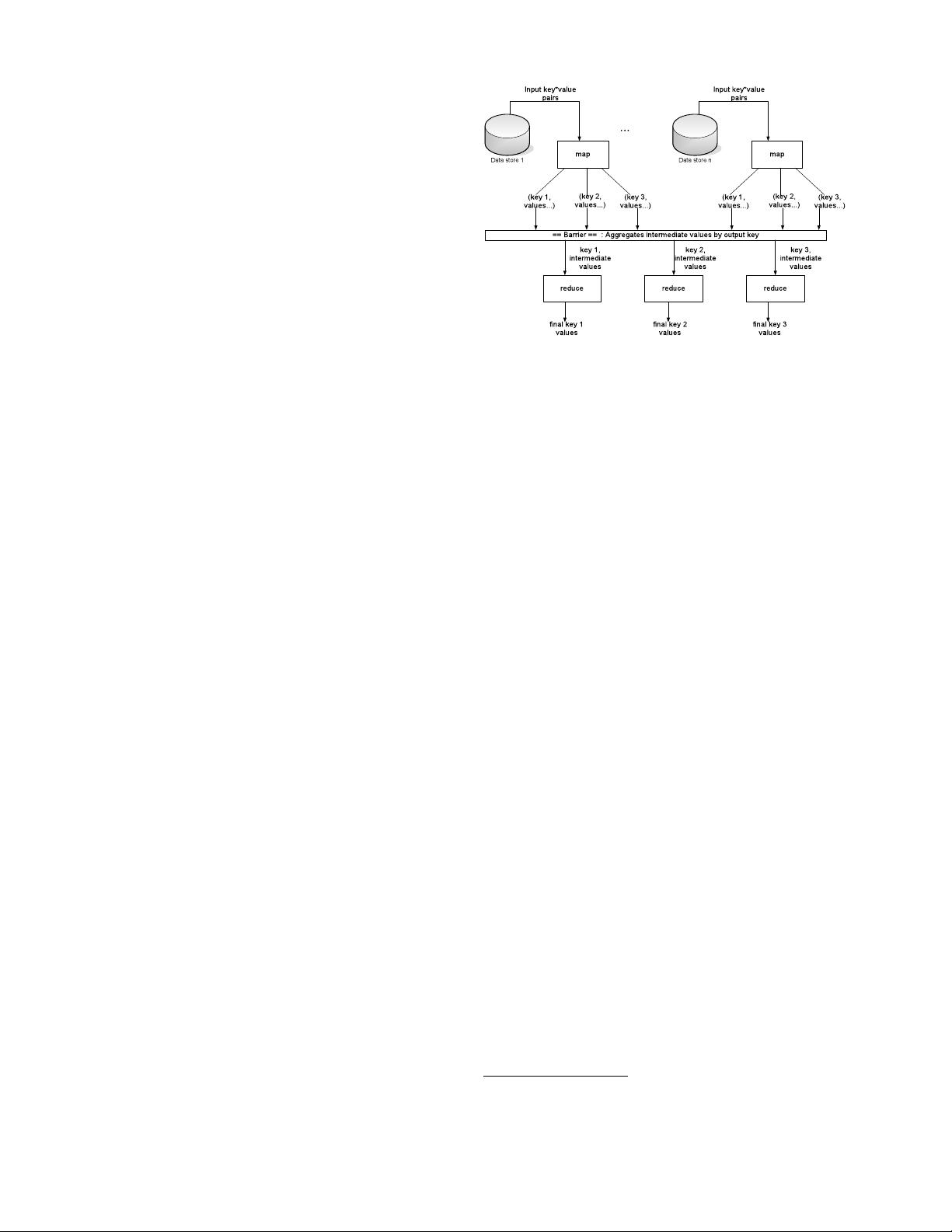
Figure 1: Data flow in MapReduce. Figure from [4].
2 Background
Hadoop’s implementation of MapReduce resembles that of
Google [16]. Hadoop runs on top of a distributed file sys-
tem, HDFS, which stores three replicas of each block like
GFS [19]. Users submit jobs consisting of a map function
and a reduce function. Hadoop breaks each job into mul-
tiple tasks. First, map tasks process each block of input
(typically 64 MB) and produce intermediate results, which
are key-value pairs. These are saved to disk. Next, re-
duce tasks fetch the list of intermediate results associated
with each key and run it through the user’s reduce func-
tion, which produces output. Each reducer is responsible
for a different portion of the key space. Figure 1 illustrates
a MapReduce computation.
Job scheduling in Hadoop is performed by a master
node, which distributes work to a number of slaves. Tasks
are assigned in response to heartbeats (status messages) re-
ceived from the slaves every few seconds. Each slave has a
fixed number of map slots and reduce slots for tasks. Typi-
cally, Hadoop tasks are single-threaded, so there is one slot
per core. Although the slot model can sometimes under-
utilize resources (e.g., when there are no reduces to run), it
makes managing memory and CPU on the slaves easy. For
example, reduces tend to use more memory than maps, so it
is useful to limit their number. Hadoop is moving towards
more dynamic load management for slaves, such as taking
into account tasks’ memory requirements [5]. In this pa-
per, we focus on scheduling problems above the slave level.
The issues we identify and the techniques we develop are
independent of slave load management mechanism.
2.1 Previous Scheduling Solutions for Hadoop
Hadoop’s built-in scheduler runs jobs in FIFO order, with
five priority levels. When a task slot becomes free, the
scheduler scans through jobs in order of priority and submit
time to find one with a task of the required type
1
. For maps,
the scheduler uses a locality optimization as in Google’s
1
With memory-aware load management [5], there is also a check that
the slave has enough memory for the task.
2
剩余17页未读,继续阅读
2017-08-19 上传
2019-03-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38669628
- 粉丝: 387
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- infinispan-cachestore-aerospike:Aerospike NoSql 的 JBoss Infinispan 缓存存储
- 一个使用C语言基于EasyX图形库编写的俄罗斯方块小游戏项目。适合C语言初学者练习,可以快速上手图形游戏编程。.zip
- 电信设备-一种灵敏反应移动训练系统.zip
- spring多模块框架-MavenMultiModel
- OpenHab-OpenWeatherMap-transform:OpenHab OpenWeatherMap 转换文件。 这类似于雅虎天气变换
- Hackerrank:解决hackerrank问题
- esuppport 3.30.02 Nulled_esuppport_CMS程序开发模板(使用说明+源代码+html).zip
- 精选_基于SPARK的分布式随机森林_源码打包
- fag-ark-reaktiv-logistikk:专业组2015建筑组3-物流服务
- B85-HD3-4590-OC.zip
- 基于ICA算法的图像融合matlab仿真+仿真录像
- [交友会员]F_Space交友程序 V3.0简体中文版_fs3-free-gbk.rar
- urban-sounds-classification:使用CNN对城市中的10种不同声音进行分类
- neev:Neev项目的黑客马拉松
- 电信设备-修改数字无线通信的归属位置寄存器系统数据库的方法.zip
- 粉色的电商类化妆品购物商城html模板.rar
