Apache Hadoop搭建教程:3种方式详解与配置步骤
版权申诉
127 浏览量
更新于2024-07-05
收藏 13.52MB PDF 举报
Apache Hadoop 是一个开源的大数据处理框架,最初由雅虎公司开发,用于处理海量数据并实现分布式计算。本文主要介绍了如何在 VMware 虚拟机环境中搭建 Apache Hadoop 的三种常见方法,包括以下关键步骤:
1. **环境准备**:
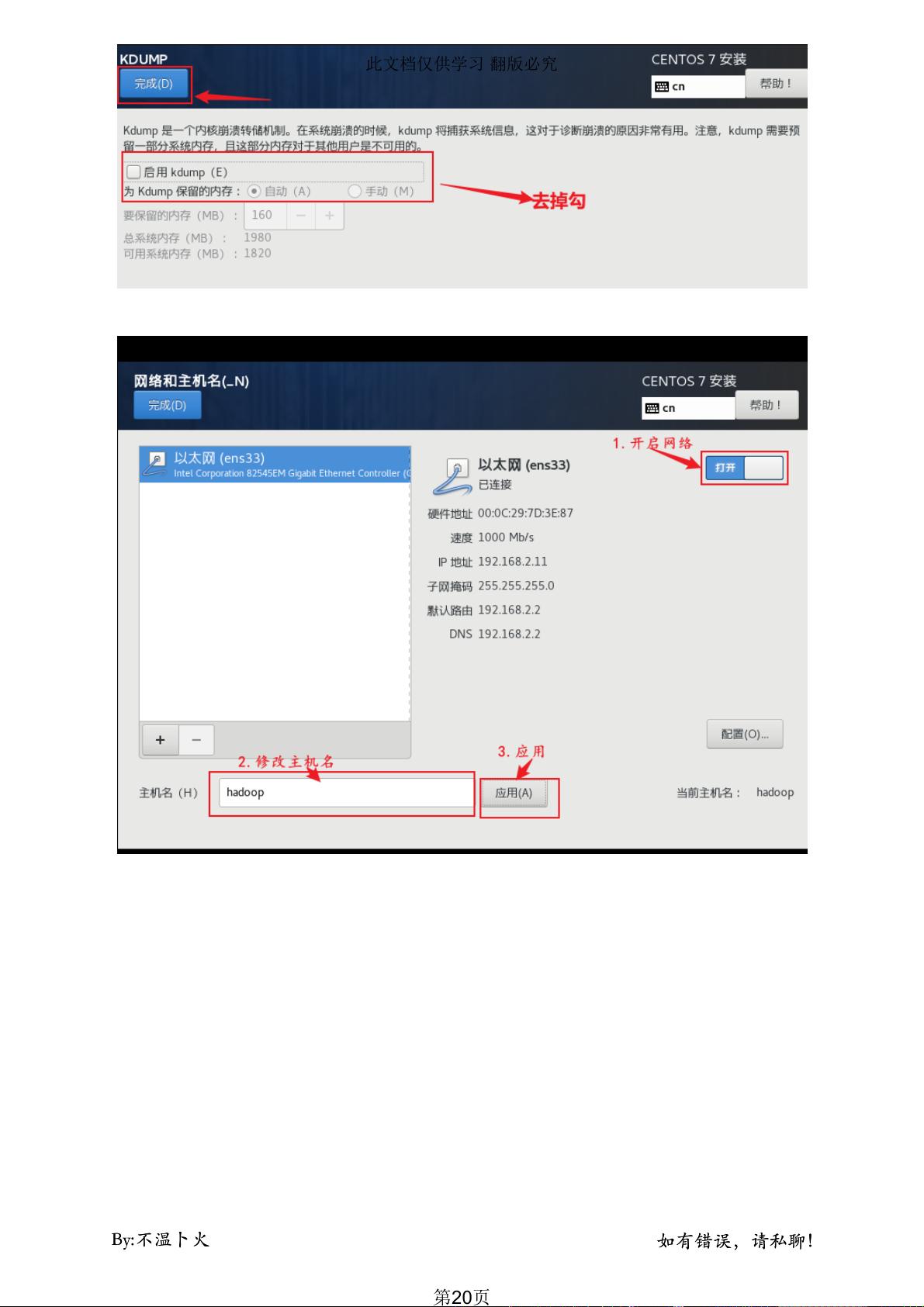
- 进入 VMware Workstation 或 Player,创建一个新的虚拟机,设置 IP 地址(如 192.168.10.10),主机名称(如 hadoop)以及硬件配置,比如分配 2GB 内存和 60GB 硬盘空间。
2. **操作系统选择与兼容性**:
- 需要考虑虚拟机的兼容性,选择合适的操作系统模板,例如 CentOS、Ubuntu 或者 Debian,根据实际项目需求来决定。
3. **配置虚拟机参数**:
- 设置 CPU 数量,遵循与物理机相同但不超过物理核心数量的原则。查看物理机 CPU 核心数,并在虚拟机中相应调整。
- 分配内存,建议至少 4GB,但避免过多以防止资源竞争。
4. **网络配置**:
- 选择 NAT 模式上网,确保虚拟机能够通过虚拟网络卡 vmnet8 与物理机通信。
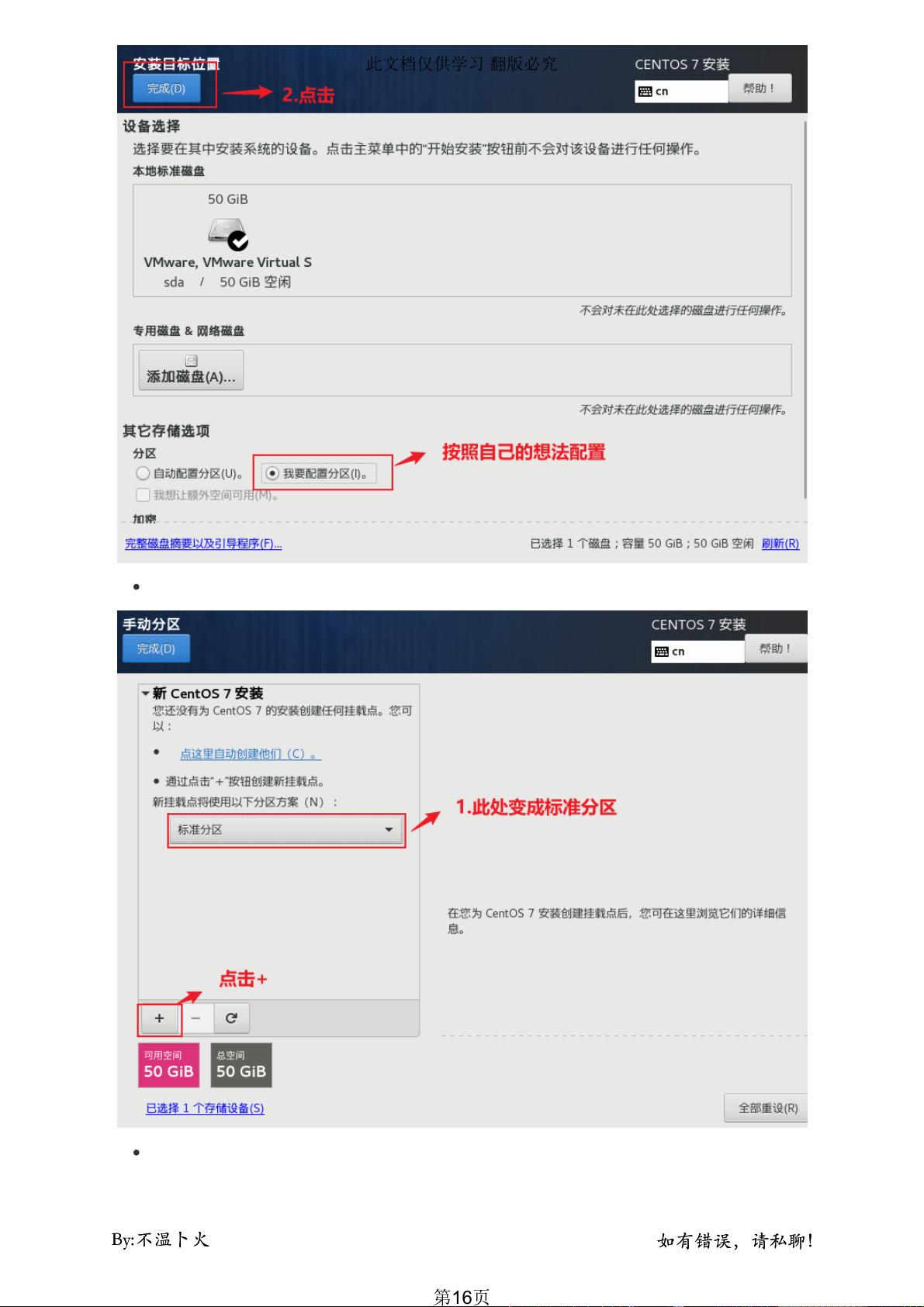
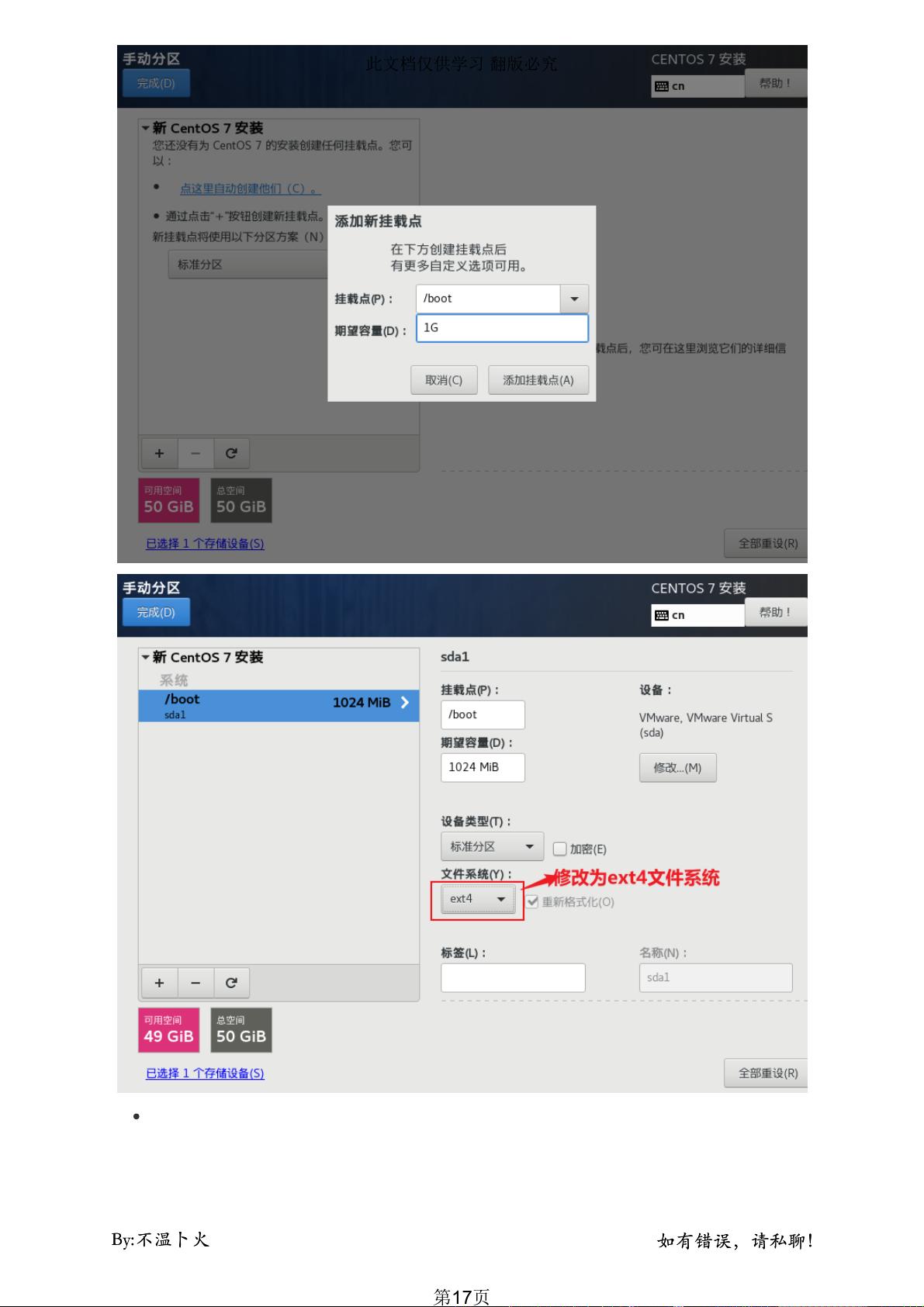
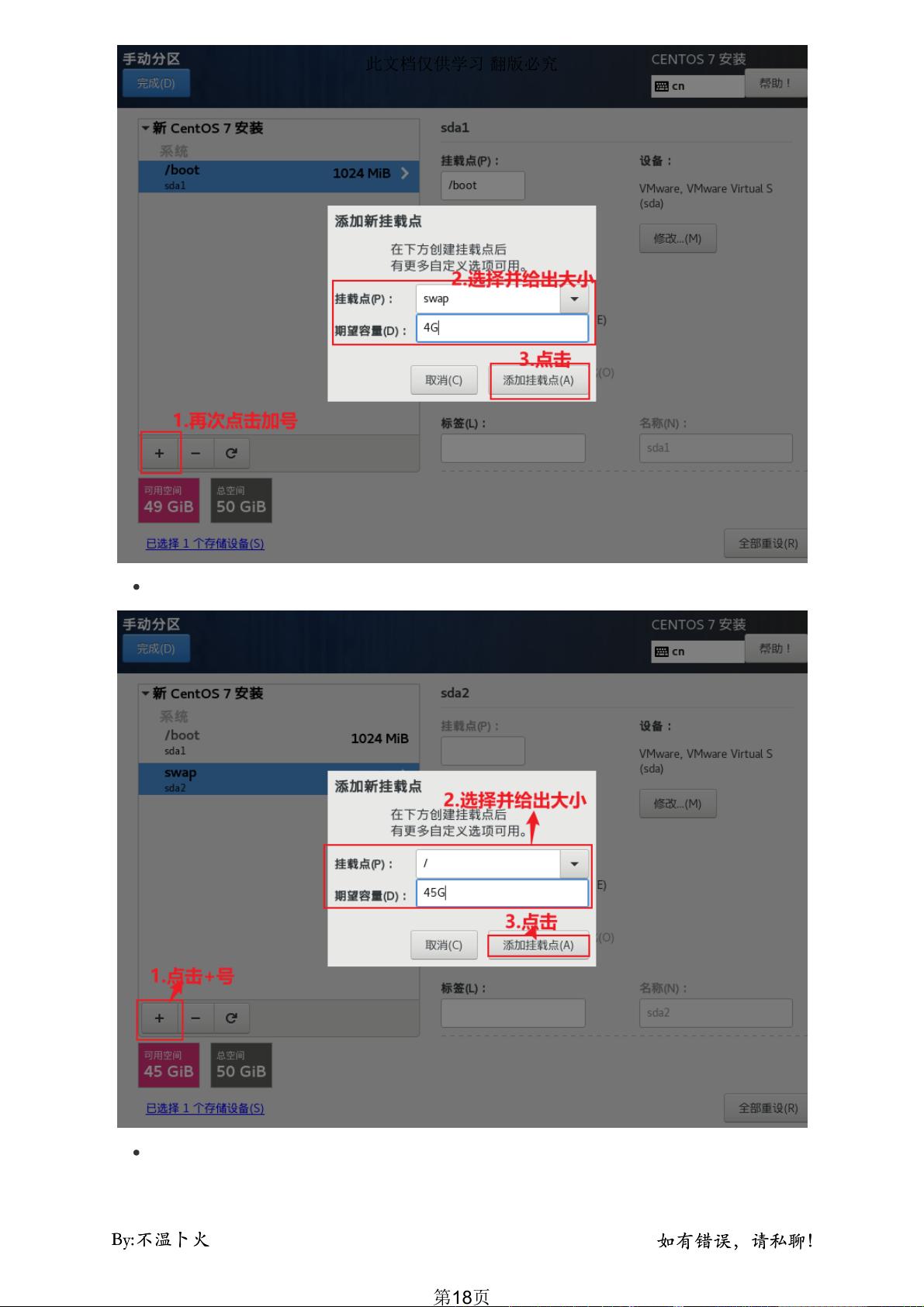
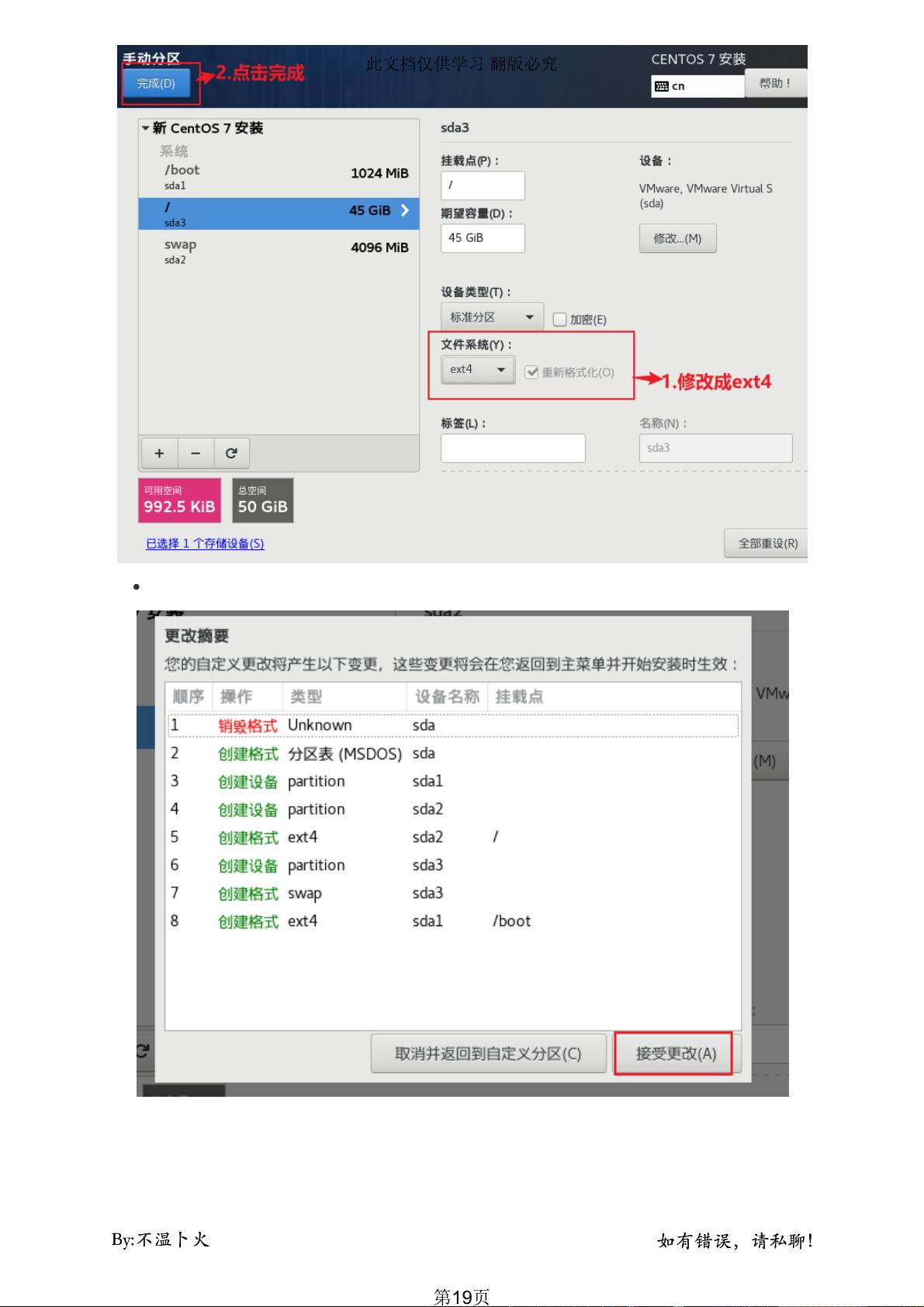
5. **文件系统与磁盘管理**:
- 选择合适的文件系统类型,如 ext4 或 XFS,并配置磁盘类型(例如 IDE、SCSI 或 SAS)和大小,这将影响数据存储性能。
6. **虚拟机文件位置**:
- 确定虚拟机文件(即 .vmx 文件)的保存路径,通常选择在物理机的特定目录下,便于管理和备份。
7. **安装模板虚拟机**:
- 安装预先准备好的 Hadoop 模板,这个过程可能包括安装基础操作系统,然后安装 Hadoop 相关软件包(如 HDFS和 MapReduce),并配置环境变量和配置文件。
8. **解决兼容性和问题**:
- 在安装过程中可能会遇到兼容性问题,如驱动冲突或软件依赖,需要及时解决以确保 Hadoop 正常运行。
本文提供了详尽的步骤指导,适用于初次接触 Hadoop 或对 VMware 环境有经验的开发者。通过这个流程,读者可以搭建出一个可用于大数据处理的 Hadoop 集群环境,为后续的数据分析和处理奠定基础。
113 浏览量
401 浏览量
301 浏览量
305 浏览量
2014-04-16 上传
2015-01-25 上传
112 浏览量
2013-09-06 上传
点击了解资源详情

_吕小布
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 数学画图教具设计文档及应用指南
- SSH与WebService整合环境配置详解
- Java线程池基础教程与实例解析
- Notepad++ 2018及老版本编译工具链完整分享
- MFC实现圆弧扫描转换的图像处理技术
- 北大Hadoop环境下的数据库多表查询设计
- PHP表格讲习班:搜索栏导航与页面重定向
- 心理学教学辅助多媒体装置设计文档
- 三国游戏自动化工具开发:易语言实战攻略
- 深入解析Foxit PDF编辑器的强大功能
- C++仿FGO战斗逻辑的实现与代码分析
- React 练习项目深入探索
- MyEclipse10完整指南:构建WebService服务端和客户端
- Tensorflow.js实现的电晕面罩检测技术
- Spring Boot工具安装使用教程
- 圆木结构设计文档:木屋墙体的应用方案
