Spark缓存与检查点详解:提升性能的关键策略
Spark是一个分布式计算框架,相比于Hadoop MapReduce,它引入了缓存(Cache)和检查点(Checkpoint)机制,以优化性能并处理复杂的逻辑执行图。这两个特性对于迭代型算法和交互式应用至关重要,因为它们能够减少重复计算的成本,提高效率。
1. **缓存机制**:
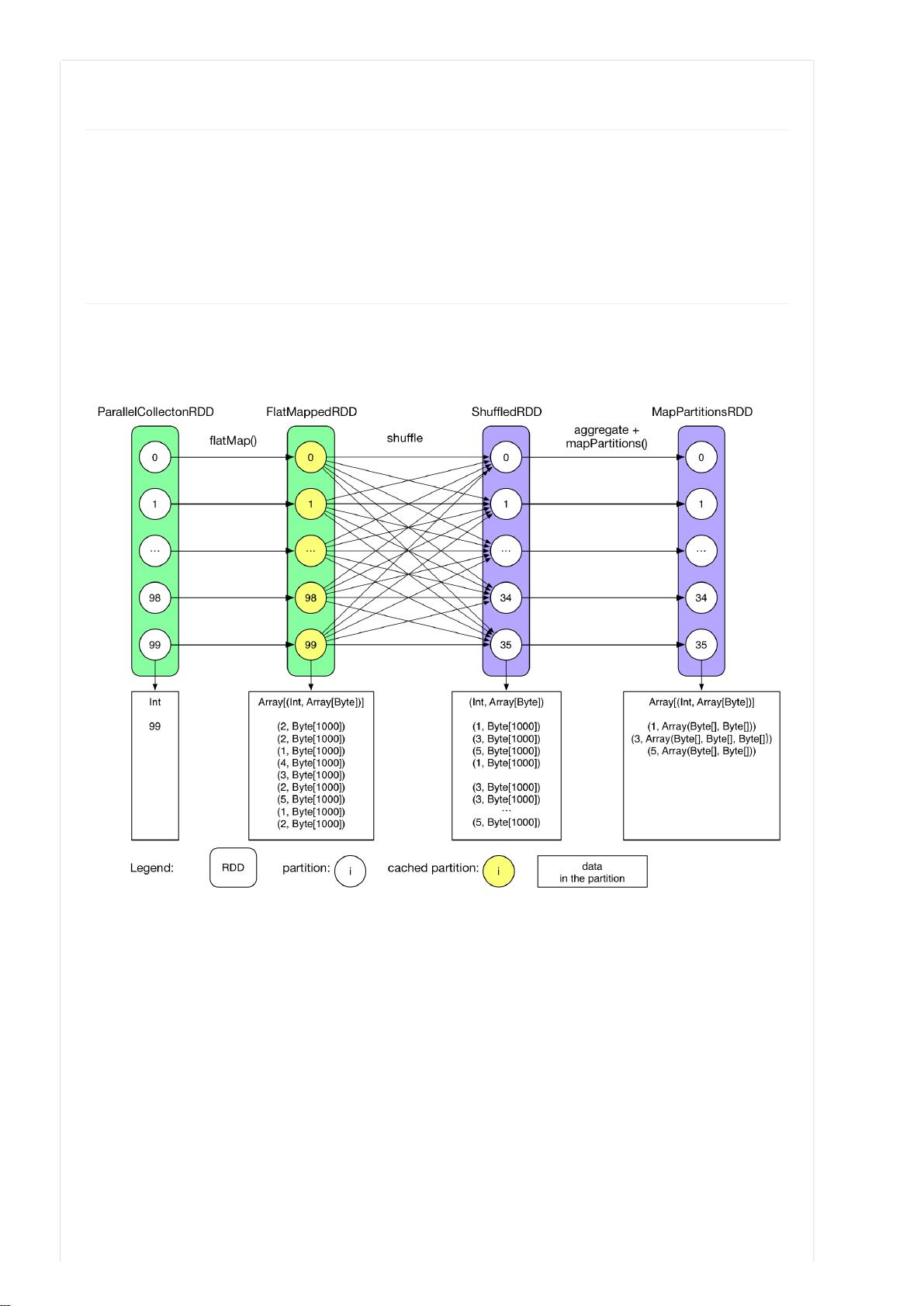
- 缓存用于存储那些在应用程序中需要反复使用的数据,特别是那些计算代价较高的RDD(弹性分布式数据集)。例如,在GroupByTest案例中,对FlatMappedRDD进行cache,使得后续Job可以直接利用已经计算好的数据,避免了重新计算整个链路带来的高成本。
- 适用于频繁使用的且数据量相对较小的RDD,如中间结果或者频繁查询的数据集。
2. **何时使用缓存**:
- 用户通常通过`rdd.cache()`方法手动标记需要缓存的RDD,但要注意,不是所有的transformation生成的RDD都可以直接缓存,例如reduceByKey()产生的ShuffledRDD和MapPartitionsRDD由于其性质,不支持直接cache,用户需根据具体需求选择合适的RDD。
3. **设置缓存过程**:
- 在driver程序中调用`rdd.cache()`后,Spark会在后台执行一个策略,如首次遇到某个分区时,会判断是否需要缓存。一旦决定缓存,记录将被保存在本地的内存store中,如果内存不足,则转存至disk store。这个过程是惰性的,即只有在第一次访问时才会触发缓存操作。
4. **检查点机制**:
- 当逻辑执行图很长,任务可能因故障中断时,检查点机制可以定期或在特定条件触发,将部分计算结果持久化,以便在发生错误时能从检查点恢复计算,而不是重新计算整个链路。这对于降低故障恢复成本至关重要。
5. **实际实现**:
- Spark的缓存和检查点实现并非简单地将数据复制,而是采用了高效的数据存储和管理策略,包括内存管理和磁盘存储。Spark会根据可用资源动态调整缓存策略,确保在内存紧张时,能优先保留最近最常使用的数据。
通过理解和掌握缓存和检查点机制,开发者可以针对Spark应用进行更细致的性能优化,确保在大数据处理场景下,Spark能够高效、可靠地执行任务。
作为区别于 Hadoop 的个重要 feature,cache 机制保证了需要访问重复数据的应(如迭代型算法和交互式应)可以
运的更快。与 Hadoop MapReduce job 不同的是 Spark 的逻辑/物理执图可能很庞,task 中 computing chain 可能
会很,计算某些 RDD 也可能会很耗时。这时,如果 task 中途运出错,那么 task 的整个 computing chain 需要重算,
代价太。因此,有必要将计算代价较的 RDD checkpoint 下,这样,当下游 RDD 计算出错时,可以直接从
checkpoint 过的 RDD 那读取数据继续算。
回到 Overview 提到的 GroupByTest 的例,对 FlatMappedRDD 进了 cache,这样 Job 1 在执时就直接从
FlatMappedRDD 开始算了。可 cache 能够让重复数据在同个 application 中的 jobs 间共享。
逻辑执图:
物理执图:
Cache和Checkpoint
Cache机制
Text
下载后可阅读完整内容,剩余6页未读,立即下载
2017-07-02 上传
2017-07-02 上传
2017-07-02 上传
2022-06-23 上传
2024-09-16 上传
2024-09-11 上传
2017-01-25 上传
2020-04-24 上传

ppulse
- 粉丝: 2
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
