超学习:依赖性解析与顺序模式挖掘在超义模式中的应用
163 浏览量
更新于2024-06-18
收藏 2.67MB PDF 举报
"哈马德·伊萨·阿拉·阿尔丁的硕士论文主要探讨了依赖性解析和顺序模式挖掘在超义模式表示和学习中的应用。这篇论文属于人工智能领域,特别是在计算机科学的子领域,由作者于2020年在南布列塔尼大学提交,并于2021年在Vannes进行了答辩。论文的研究工作在IRISA研究单位进行,指导教师包括Giuseppe Berio教授和Mohamed Dbouk教授,评审团成员包括Matthieu Roche、Nada Matta、Fabrice Guillet等人。"
详细说明:
这篇论文的核心是将依赖性解析和顺序模式挖掘技术结合,以解决超义模式的表示和学习问题。依赖性解析是一种自然语言处理技术,主要用于理解句子中词语之间的结构关系,它可以帮助识别出词汇的语法功能和句法结构,这对于理解文本的意义至关重要。在本研究中,依赖性解析可能被用来提取和分析语料库中的词汇关系,以发现超义(更一般的概念)和下义(更具体的概念)之间的层次结构。
另一方面,顺序模式挖掘是数据挖掘的一个分支,专注于发现序列数据中的频繁模式,如时间序列或事件序列。在本论文的上下文中,顺序模式可能被用来分析文本中的事件顺序,以揭示超义模式在时间或逻辑上的演变规律。
作者通过这些技术的结合,旨在改进超义模式的表示方式,使其更加精确和有效。这可能涉及到构建新的模型或算法,以便更好地捕获词汇间的层级关系,并利用这些关系进行概念的学习和推理。此外,论文还可能探讨了如何利用这些方法提高自然语言理解和处理任务的性能,例如信息检索、文本分类或语义解析。
这篇论文的贡献不仅在于提出了一种新颖的方法,还在于实际应用这些技术来解决现实世界的问题。通过实验和案例研究,作者可能展示了他们的方法在改善超义模式表示和学习方面的效果,以及如何促进人工智能系统理解复杂语义结构的能力。
哈马德·伊萨·阿拉·阿尔丁的硕士论文是自然语言处理和数据挖掘领域的一次重要尝试,旨在通过依赖性解析和顺序模式挖掘的融合,推动超义模式表示和学习的理论与实践发展。这一研究对于后续的自然语言处理研究和相关应用具有重要的参考价值。
对基于依赖性解析和顺序模式挖掘的
Hypernym
模式表示和学习的贡献
Hamad Issa Alaa Aldine 2020
简介
本体的手动构建是一项艰巨而乏味的任务,需要该领域的知识工程师和专家。因
此,人类语言文本(为某些目的而写或专门作为本体要求文档而写)可以被认为是构
建本体所需的主要知识来源。自然语言处理、机器学习、深度学习和数据挖掘的显著
进步为从文本中进行本体学习开辟了道路,使这种工作方式成为热门和有前途的,并
为手动任务提供了有效的支持。
术语本体学习指的是本体的自动或半自动开发--即使完全自动化可能永远不可能。
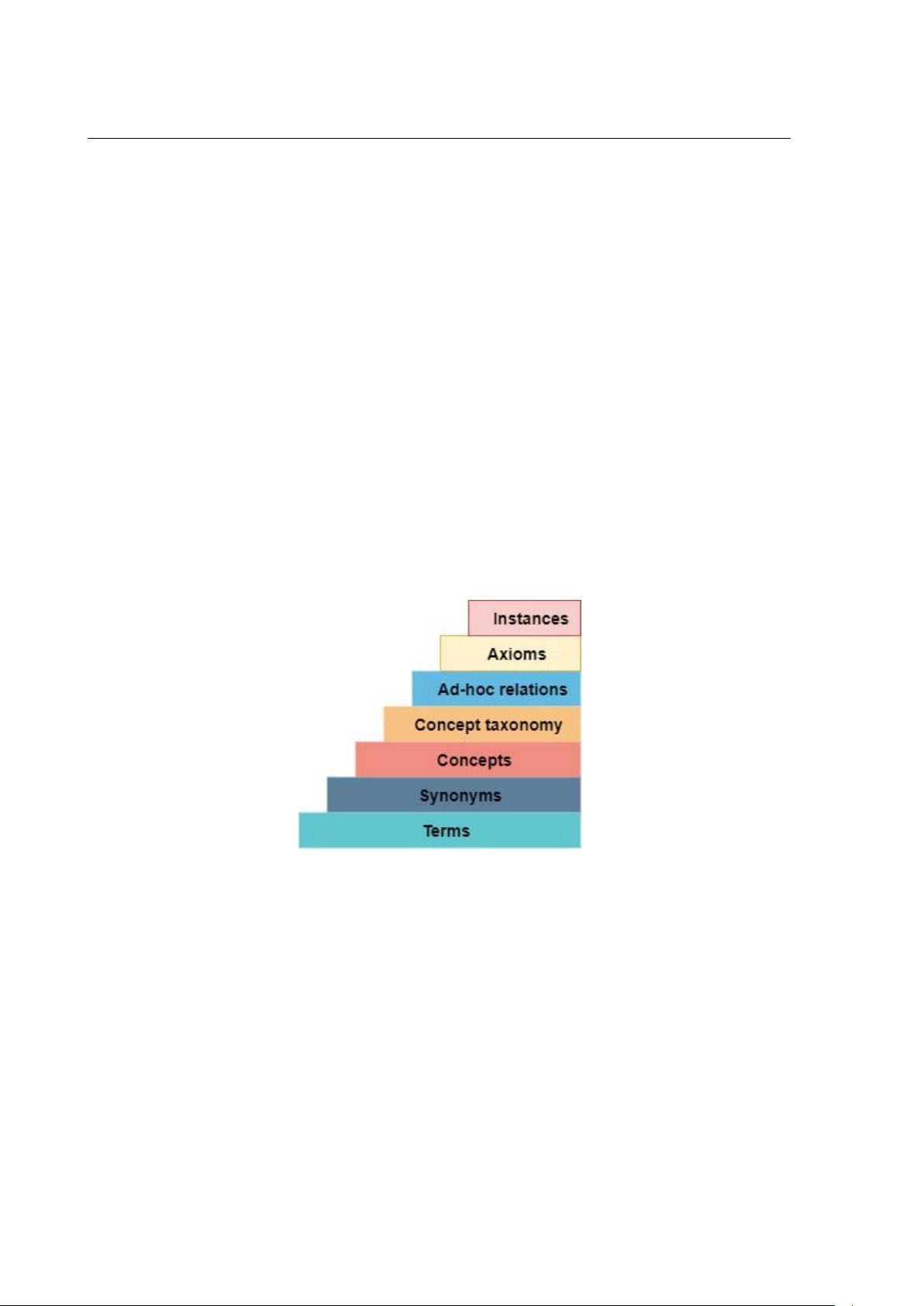
Buitelaar和。al [16]认为,本体学习过程是由图1所示的类-科学本体层蛋糕之后的越来
越复杂的子任务组成的。因此,该过程从文本中提取相关术语开始。同义词术语聚集
在同义词集中。为具有唯一含义的每个
synset
选择一个标签。此标签将是表示此
synset
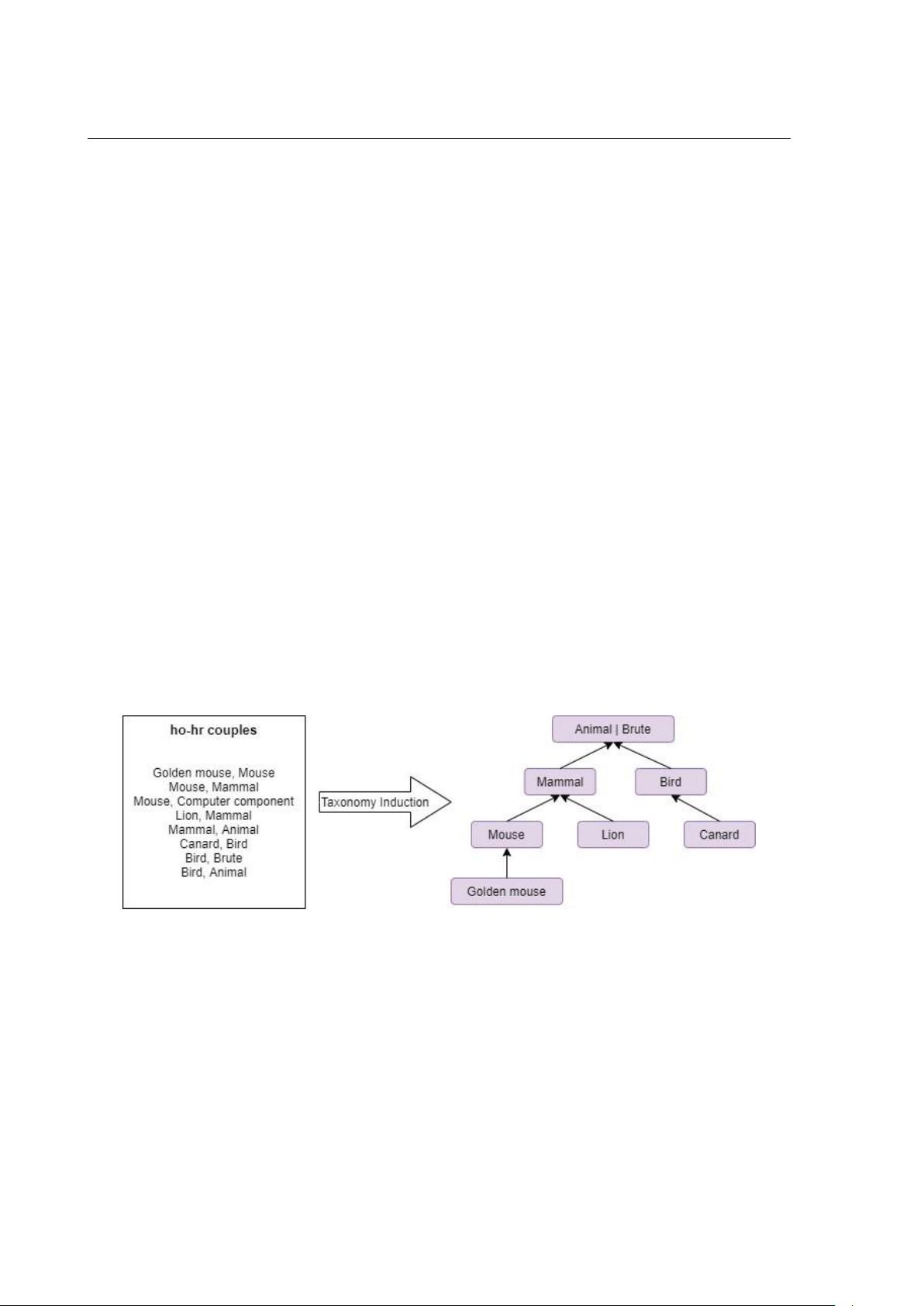
的概念术语。概念税-构建本体,使其成为对本体推理的最小支持。这一步是通过识别
概念之间的分类关系来完成的。它通常包括超名关系提取和分类关系归纳。确定了概
念之间的特殊(非分类)关系。提取了包括概念、分类学和非分类学关系在内的公
理,以使所表示的知识边缘更加精确。在群体本体中,提取概念和关系的实例。
图1:来自文本资源的本体开发层蛋糕
图
2
提供了本体学习过程的明确视图,用提出并用于完成本体学习的各种子任务的七
种技术来修饰
[7
,
104
,
13]
。 这些技术分为三大类,即基于语言的统计
-
14
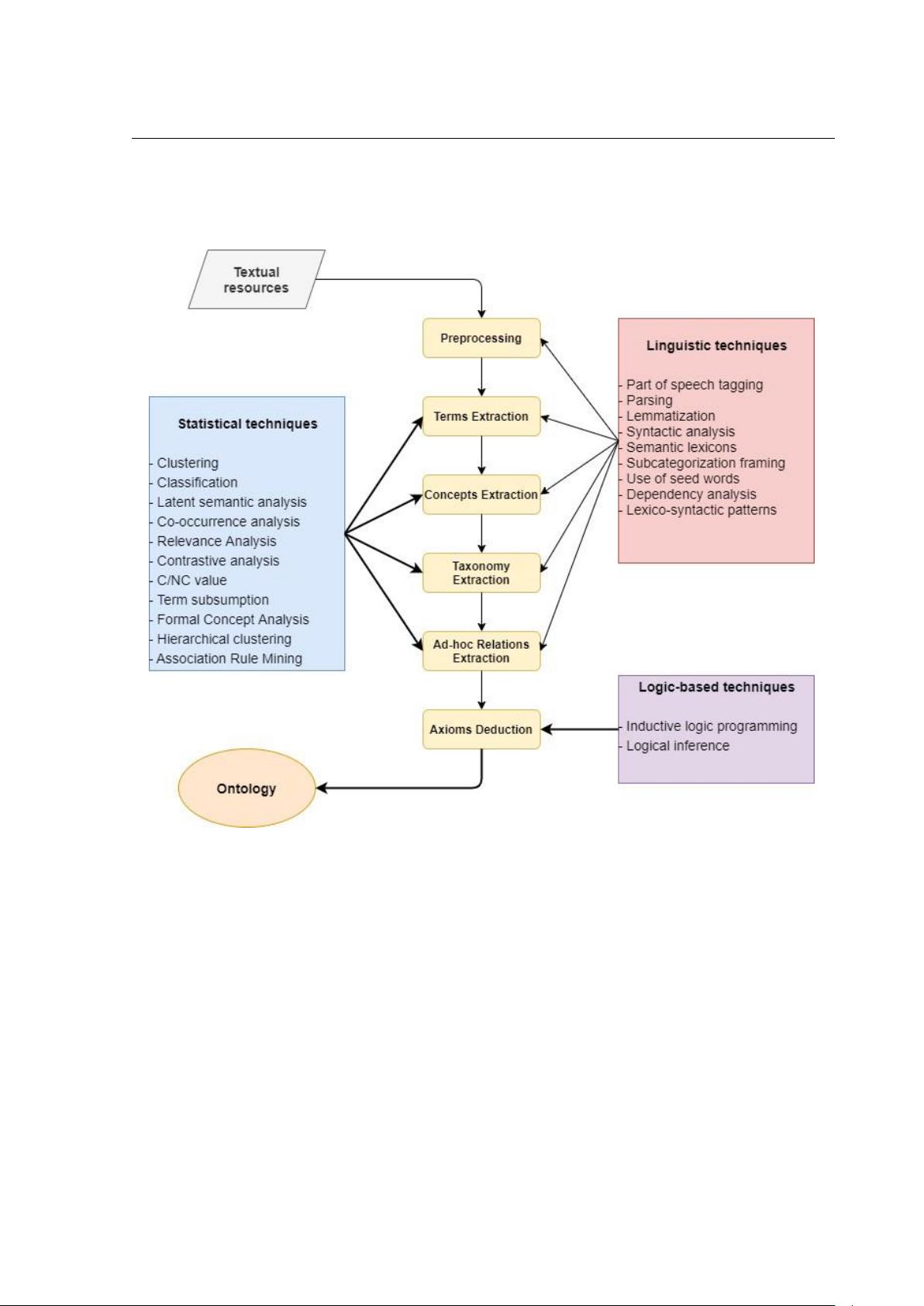


剩余165页未读,继续阅读
2021-04-01 上传
2020-05-25 上传
2020-05-21 上传
2021-07-08 上传
2021-03-09 上传
2021-06-01 上传
2021-04-14 上传
点击了解资源详情

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
