哈尔滨工业大学编译原理大作业-词法分析
需积分: 0 176 浏览量
更新于2024-06-30
收藏 3.39MB DOCX 举报
"哈尔滨工业大学编译原理课程的大作业,学生张志路完成,学号1160300909,2019年5月提交。作业内容涉及设计和实现一个词法分析器,基于确定有限状态自动机(DFA)技术,能识别特定类高级语言的各类单词,包括标识符、关键字、运算符、界符、常数和注释。"
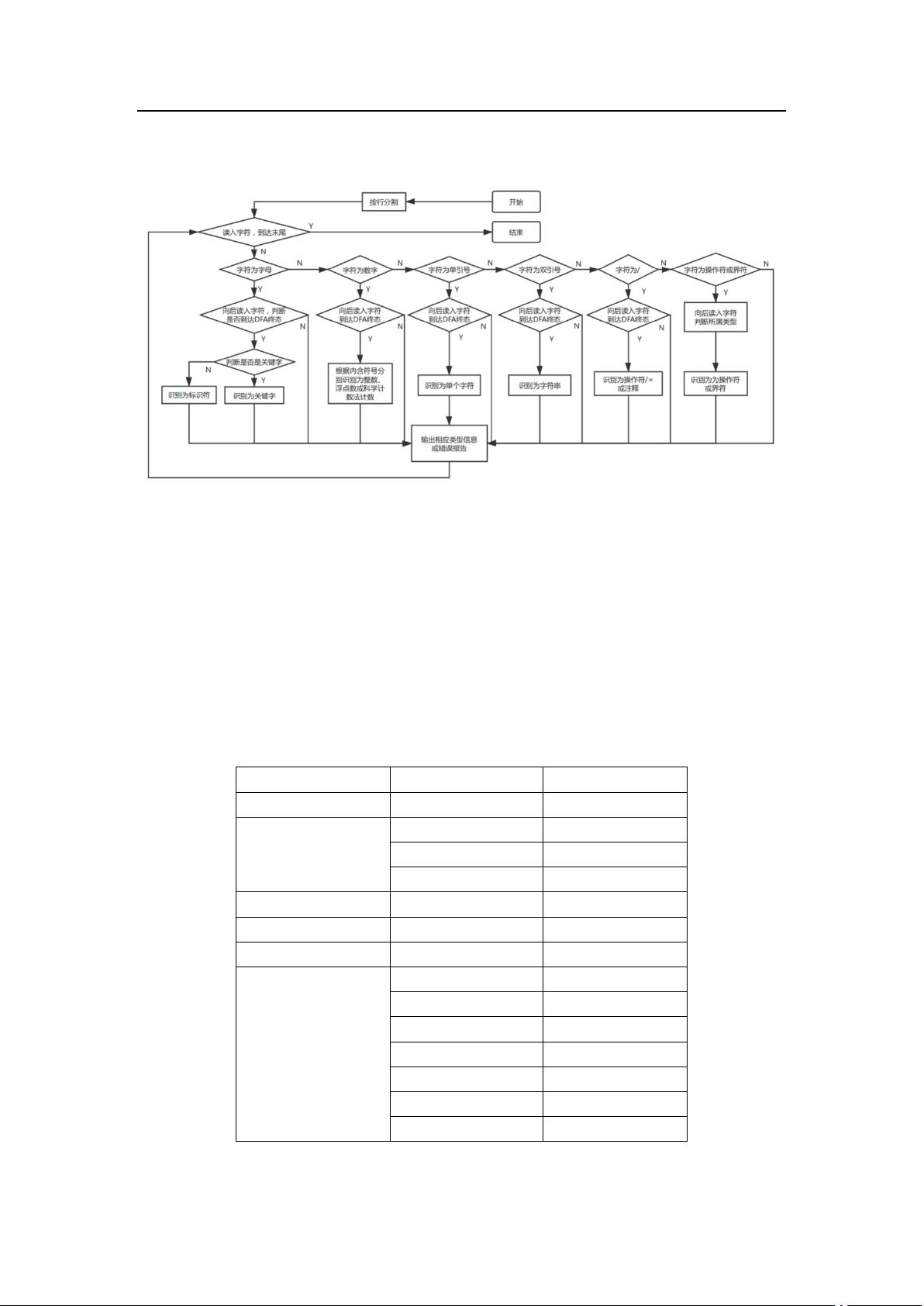
在这个大作业中,张志路主要关注的是编译原理中的核心概念——词法分析。词法分析是编译器前端的一个重要阶段,它的任务是将源代码分解成一系列有意义的、独立的单元,称为单词或token。这些token是编译器后续阶段处理的基本单位。
实验目的在于设计一个能处理以下单词类型的词法分析器:
1. **标识符**:由字母、数字和下划线组成,且必须以字母或下划线开头。例如,`myVariable123`。
2. **关键字**:包括数据类型关键字(如`int`、`float`)、控制结构关键字(如`if`、`else`、`do`、`while`)以及其他关键字(如`boolean`、`void`等)。
3. **运算符**:涵盖算术运算(如`+`、`-`、`*`、`/`)、关系运算(如`<`、`>`、`==`、`!=`)、逻辑运算(如`&&`、`||`、`!`)以及位运算(如`<<`、`>>`)等。
4. **界符**:如赋值符号`=`、分号`;`、括号`()`、`[]`、`{}`等,它们在程序中起到分隔和连接的作用。
5. **常数**:包括无符号整数和浮点数,如`123`、`3.14`。
6. **注释**:支持`/*...*/`形式的多行注释。
词法分析器的设计基于DFA技术,这是一种在计算理论中用于识别正规集的模型。DFA具有确定性,对于给定的输入串,它会进入唯一的状态序列,从而决定输入是否属于预定义的语言。
系统要求能够通过文件导入测试用例,覆盖所有列出的单词类型,并能正确处理拼写错误。输出应包括符号表和token序列,以便于理解和调试。
此外,张志路的程序还扩展了功能,可以识别单个字符(`char`)和字符串(`String`)。这表明词法分析器不仅处理基本的编程元素,还能处理更复杂的文本结构。
词法分析的规则通常以正则表达式的形式给出。例如,标识符的规则是`letter_(letter_|digit)*`,表示以字母或下划线开头,后跟零个或多个字母或数字。关键字、运算符、界符、常数和注释的规则也按照类似的方式定义。
这个大作业不仅检验了学生对编译原理的理解,还考察了其实现复杂语言处理工具的能力,是计算机科学教育中的一个重要实践环节。
编译原理 大作业
12
3.2.3 程序核心部分的程序流程图
4 词法分析系统实现及结果分析
4.1 系统实现过程中遇到的问题
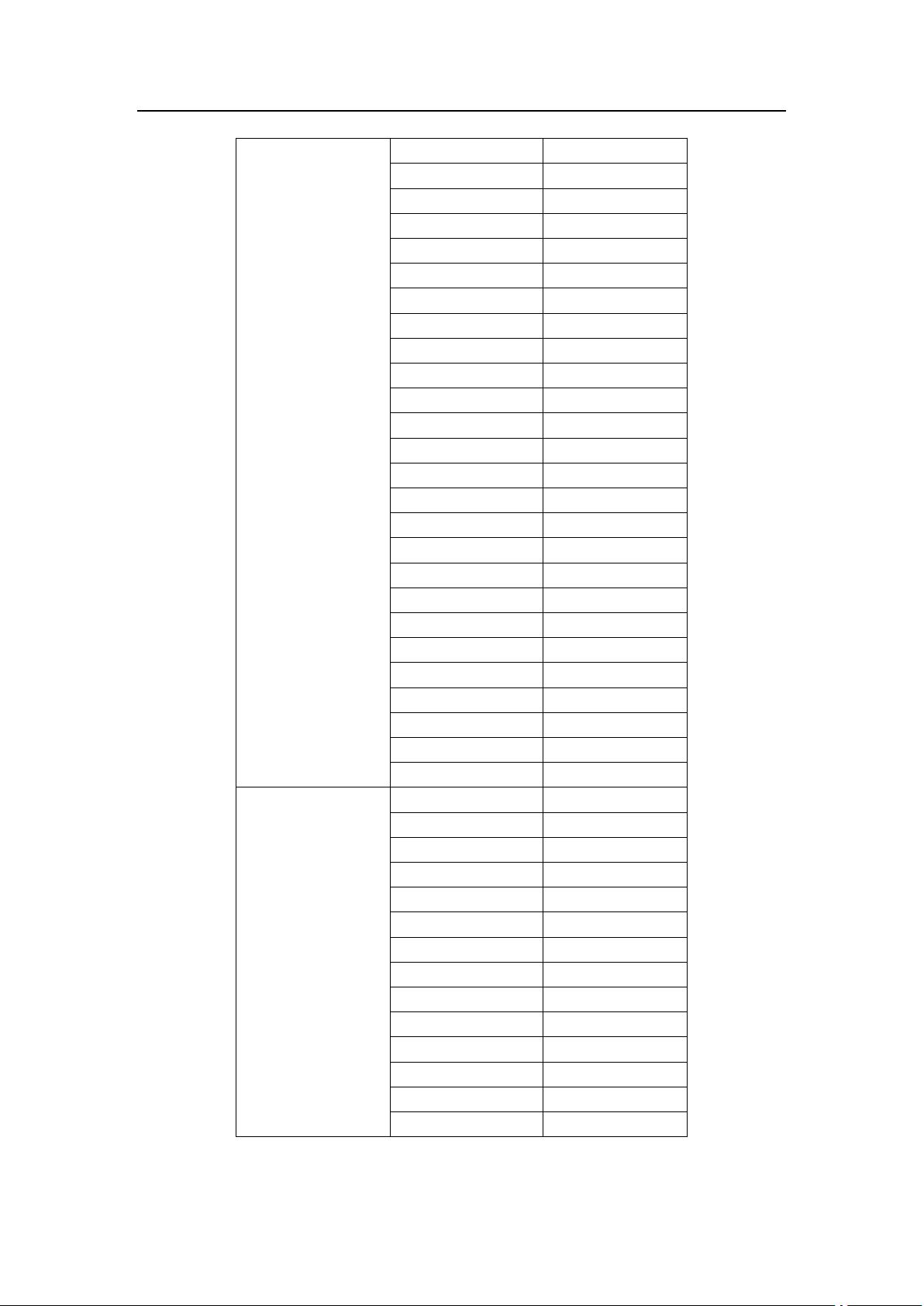
(1) 种别码编码问题
编码的清晰与否将会直接影响后续程序的实现,经过权衡,本系统对标识符
关键字、无符号数、注释等大类编码为 1~7;关键字一字一码,以 101 开头;运
算符一符一码,以 201 开头;界符一符一码,以 301 开头。之所以编码不连续是
为了方便后续对其进行扩展。
具体编码如下。
单词类型
具体类型
种别码
标识符
—
1
整型常量
2
浮点型常量
3
无符号数
科学计数法
4
字符常量
—
5
字符串常量
—
6
注释
—
7
auto
101
double
102
int
103
struct
104
break
105
else
106
long
107

剩余66页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-04 上传
2022-08-04 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-08 上传

曹多鱼
- 粉丝: 29
- 资源: 314
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
