大型集群快速通用数据处理架构
需积分: 10 181 浏览量
更新于2024-07-19
收藏 1.89MB PDF 举报
"《大型集群快速通用数据处理架构》是由Matei Alexandru Zaharia撰写的一篇博士论文,提交于加利福尼亚大学伯克利分校计算机科学研究生院,作为获取哲学博士学位的一部分。论文发表于2013年秋季,探讨了随着数据量激增和处理器速度停滞,如何适应分布式系统的发展趋势,以支持广泛应用的扩展需求。
在过去的几年里,计算系统的格局发生了显著变化,大量的数据源,如互联网、商业运营和科学研究设备,产生了海量且具有价值的数据流。然而,单个系统的处理能力已无法满足这些快速增长的需求。论文的焦点在于提出一种能够实现快速且普遍适用于大规模集群的数据处理架构,旨在解决数据处理效率的问题。
作者Matei Alexandru Zaharia深入研究了如何通过设计高效的并行处理模型和分布式算法来优化大数据的存储、检索和分析。该架构可能涉及Hadoop这样的分布式计算框架,它强调了数据的分片(data sharding)、容错机制(fault tolerance)以及任务调度(task scheduling)的重要性。通过使用分布式文件系统(如Hadoop Distributed File System, HDFS)来管理存储,论文可能会探讨如何实现数据的高效复制、备份和一致性保证,以及如何利用MapReduce等编程模型进行并行处理。
此外,论文可能还涵盖了如何通过负载均衡和资源管理技术来优化集群性能,确保在面对大规模数据时,系统能保持良好的响应时间和吞吐量。另外,它可能还会讨论如何集成机器学习、流处理和其他高级分析工具,以便在实时环境中处理动态变化的数据。
总而言之,这篇论文是大数据时代的一个重要贡献,它提供了对于构建和优化大规模集群数据处理系统的关键见解和技术,对IT行业的发展有着深远的影响,特别是在大数据处理、云计算和分布式计算领域。"
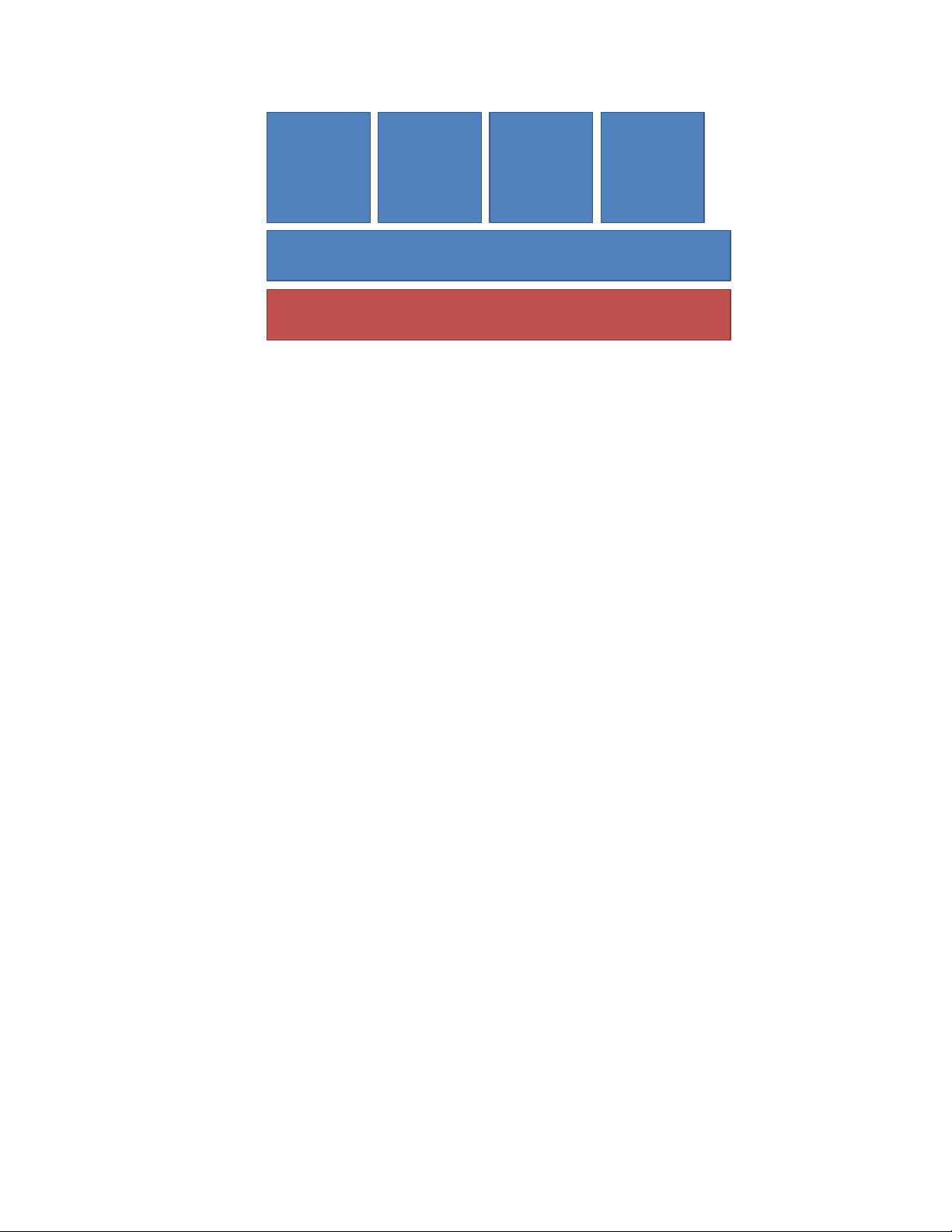
Spark (RDDs)
Spark
Streaming
(discretized
streams)
Shark
(SQL)
Bagel
(Pregel)
Fine-grained task execution model
multitenancy, data locality, elasticity
Iterative
MapReduce
…
Figure 1.1. Computing stack implemented in this dissertation. Using the Spark
implementation of RDDs, we build other processing models, such as streaming, SQL
and graph computations, all of which can be intermixed within Spark programs.
RDDs themselves execute applications as a series of fine-grained tasks, enabling
efficient resource sharing.
examples include Dremel and Impala for interactive SQL queries [
75
,
60
], Pregel for
graph processing [72], GraphLab for machine learning [71], and others.
Although specialized systems seem like a natural way to scope down the chal-
lenging problems in the distributed environment, they also come with several
drawbacks:
1. Work duplication:
Many specialized systems still need to solve the same
underlying problems, such as work distribution and fault tolerance. For
example, a distributed SQL engine or machine learning engine both need to
perform parallel aggregations. With separate systems, these problems need to
be addressed anew for each domain.
2. Composition:
It is both expensive and unwieldy to compose computations
in different systems. For “big data” applications in particular, intermediate
datasets are large and expensive to move. Current environments require
exporting data to a replicated, stable storage system to share it between
computing engines, which is often many times more expensive than the actual
computations. Therefore, pipelines composed of multiple systems are often
highly inefficient compared to a unified system.
3. Limited scope:
If an application does not fit the programming model of a
specialized system, the user must either modify it to make it fit within current
systems, or else write a new runtime system for it.
4. Resource sharing:
Dynamically sharing resources between computing en-
gines is difficult because most engines assume they own the same set of
machines for the duration of the application.
3



剩余125页未读,继续阅读
2015-01-23 上传
2018-04-03 上传
点击了解资源详情
2024-12-23 上传
基于粒子群的ieee30节点优化、配电网有功-无功优化 软件:Matlab+Matpowre 介绍:对配电网中有功-无功协调优化调度展开研究,通过对光伏电源、储能装置、无功电源和变压器分接头等设备协调
2024-12-23 上传
2024-12-23 上传
2024-12-23 上传
2024-12-23 上传
2024-12-23 上传









