Linux环境下搭建Hadoop完全分布式集群详解
需积分: 10 56 浏览量
更新于2024-07-17
收藏 1.28MB DOCX 举报
"在Linux操作系统环境下,使用三台虚拟机搭建完全分布式模式的Hadoop集群,主要涉及Hadoop的安装和配置。实验环境包括一个主节点master2(IP:192.168.0.121)和两个从节点slave21(IP:192.168.0.122)和slave22(IP:192.168.0.127),所有操作默认在master2节点上执行。"
在搭建Hadoop集群之前,首先需要准备必要的实验环境。这包括确保所有虚拟机已经启动并运行,并且主目录设置为"/home/hadoop"。为了便于文件传输,需要创建一个名为"software"的目录来存放Hadoop和Java的安装包。通过SSH客户端软件,如SSHSecureFileTransferClient,可以将本地的Hadoop和Java安装文件(例如hadoop-2.7.1.tar.gz和jdk-8u60-linux-x64.tar.gz)上传到虚拟机的"software"目录。
连接本地主机和虚拟机时,需要提供虚拟机的IP地址(即主节点的IP)、用户名(这里是"hadoop")以及密码。连接成功后,可以看到虚拟机的文件系统,可以将所需软件文件移动到对应目录。接着,需要解压这两个文件,使用命令如"tar -zxvf hadoop-2.7.1.tar.gz"和"tar -zxvf jdk-8u60-linux-x64.tar.gz"。
解压完成后,要配置环境变量,以便系统能够识别Hadoop和Java。这通常涉及到修改用户环境变量配置文件,如".bashrc"或".bash_profile"。在文件末尾添加如下内容:
```bash
export JAVA_HOME=/path/to/jdk/folder
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/path/to/hadoop/folder
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
```
请将`/path/to/jdk/folder`和`/path/to/hadoop/folder`替换为实际的解压目录。
配置完成后,使用"source .bashrc"(或".bash_profile")使更改生效。接下来,需要配置Hadoop的配置文件,主要包括`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`。这些配置文件通常位于`$HADOOP_HOME/etc/hadoop`目录下。
在`core-site.xml`中,设置Hadoop的临时目录和名称节点的地址,例如:
```xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master2:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
```
在`hdfs-site.xml`中,配置数据节点和名称节点的副本数以及DFS的相关参数,例如:
```xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
```
在`mapred-site.xml`中,配置MapReduce框架的相关参数,例如:
```xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
```
在`yarn-site.xml`中,配置YARN资源管理器和NodeManager的相关参数,例如:
```xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>
```
配置完成后,需要在所有节点上格式化名称节点,启动Hadoop服务。在master2节点上执行初始化HDFS的命令:
```bash
$hadoop namenode -format
```
然后启动Hadoop守护进程:
```bash
$sudo -u hdfs hdfs dfsadmin -safemode leave
$sudo -u hdfs hdfs namenode
$sudo -u yarn yarn resourcemanager
$sudo -u mapred mapred jobtracker
$sudo -u hdfs hadoop datanode
$sudo -u yarn hadoop nodemanager
```
在其他从节点上启动datanode和nodemanager服务。
最后,可以通过Hadoop提供的命令验证集群是否正常运行,例如检查HDFS的健康状况:
```bash
$hadoop dfsadmin -report
```
和YARN的资源管理器状态:
```bash
$yarn node -list
```
如果所有步骤都正确执行,那么你就成功地在Linux环境中搭建了一个完全分布式的Hadoop集群。这个集群可用于大数据处理任务,如MapReduce作业的执行。
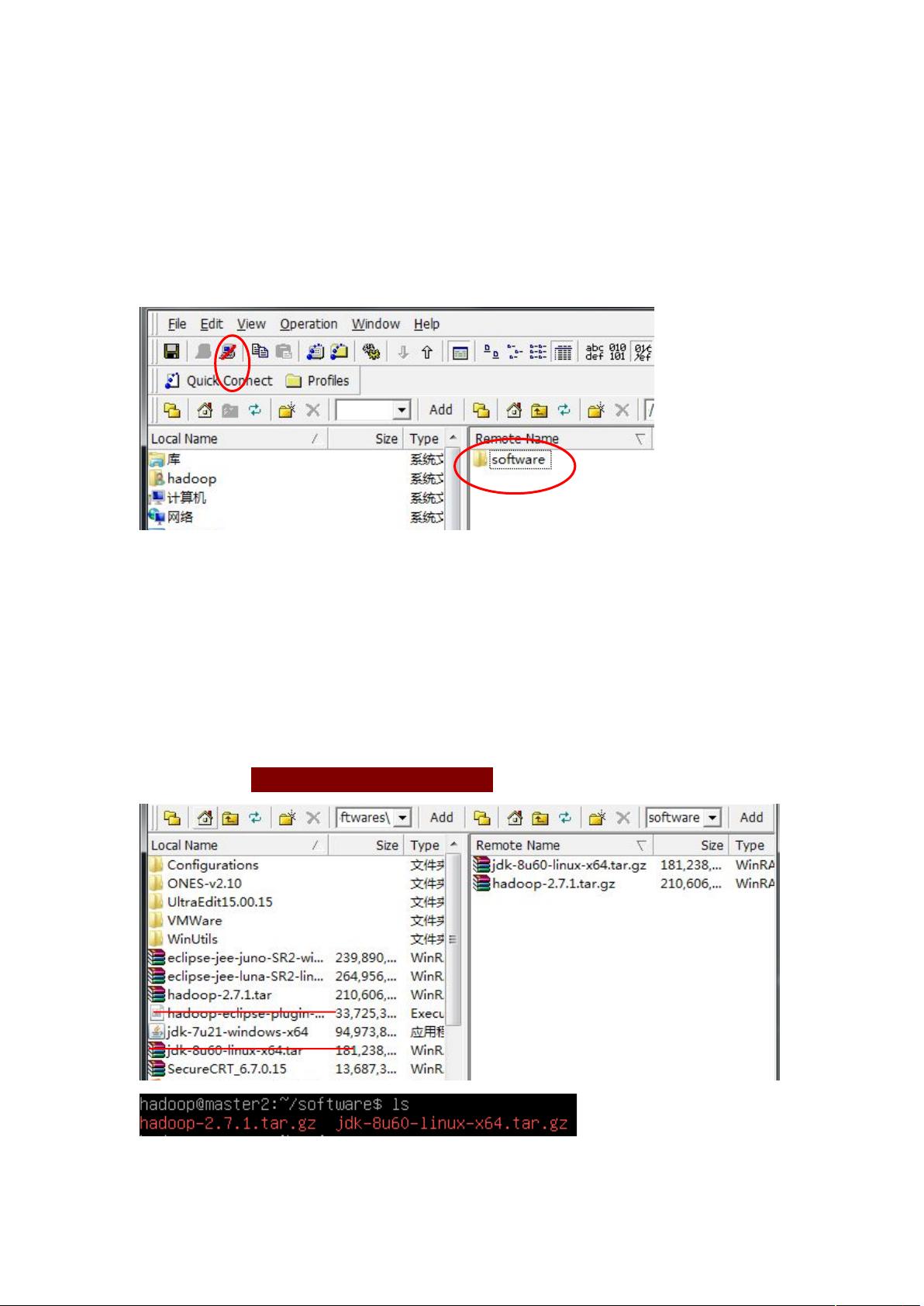
七、 查看是否成功连接
可以看到界面的两个变化:一是电脑图标切换成下图,二是【 Remote
Name】部分显示了已创建过得 software 文件夹。此时说明连接成功。
八、 整理成功拷贝的软件
将磁盘中存储的 hadoop-2.7.1.tar.gz 和 jdk-8U60-linux-x64.tar.gz(根
据实际文件名而定)拖动移至 software 文件夹下。可键入“ls software”命令查
看是否存在,橙色字体表示是一个压缩文件。

剩余36页未读,继续阅读
2018-09-12 上传
2019-04-07 上传
点击了解资源详情
点击了解资源详情
2023-06-03 上传
2024-11-11 上传
2013-04-09 上传
2023-12-23 上传
2021-01-07 上传

VX_15126603515
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
