K-Nearest Neighbor(KNN)算法详解与Python实现
需积分: 0 132 浏览量
更新于2024-08-04
收藏 299KB DOCX 举报
"KNN分类1"
K-Nearest Neighbor(KNN)是最邻近分类算法,它在机器学习领域中扮演着重要的角色,尤其在分类问题中。KNN算法属于基于实例的学习和懒惰学习类别。在懒惰学习中,模型不会在训练阶段进行复杂的模型构建,而是等到预测阶段,利用训练数据集的信息来做出决策。
KNN算法的核心思想是:对于一个未知类别的样本,通过计算其与其他已知类别样本的距离,找到最近的k个邻居,然后依据这些邻居的类别进行多数表决,决定未知样本的类别。这里的k是一个预设的整数值,通常选择一个小的奇数以避免平局。
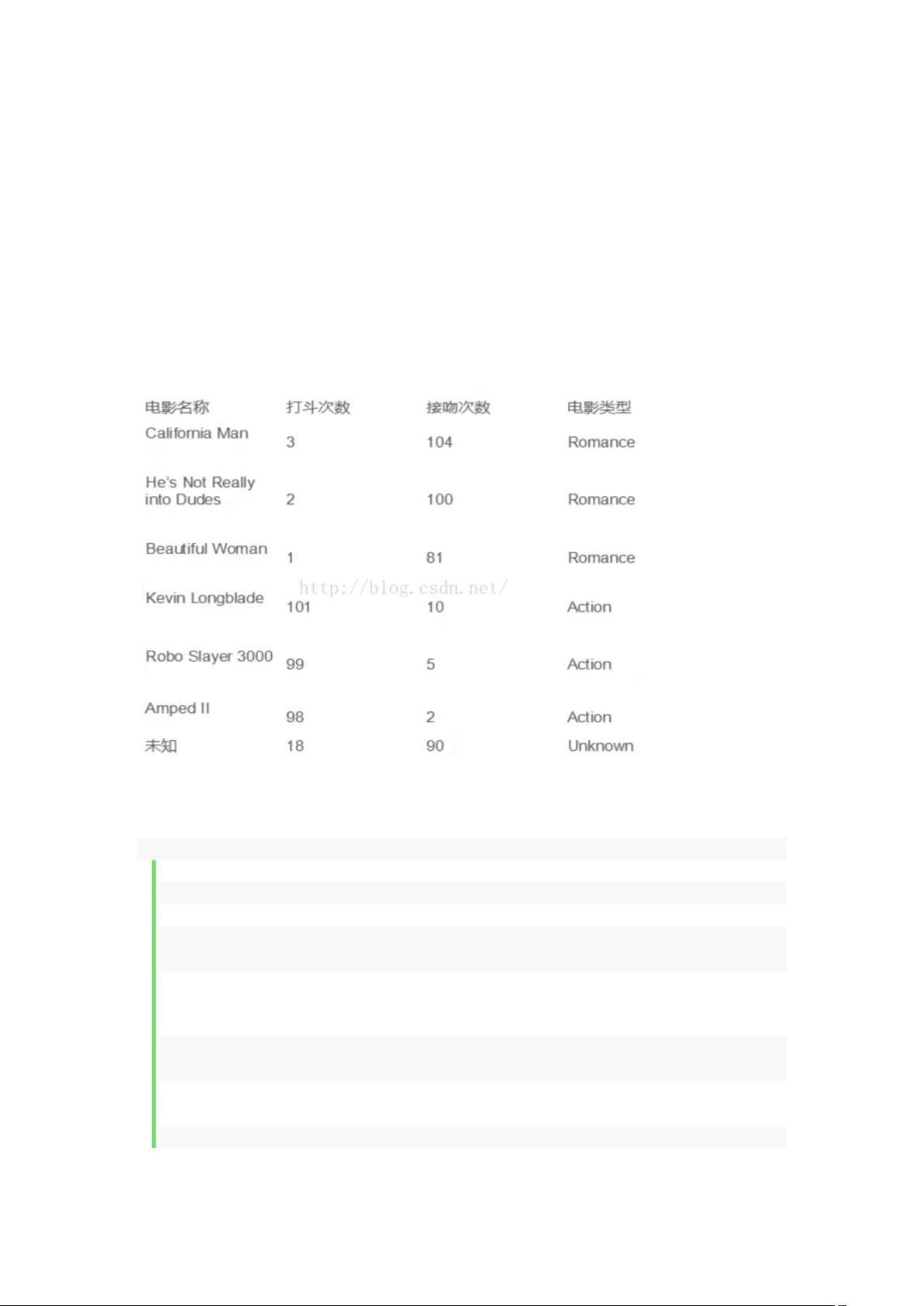
在提供的代码示例中,使用了Python的科学计算库NumPy和机器学习库Scikit-learn来实现KNN算法。首先,创建了一个KNeighborsClassifier对象,接着定义了电影数据集,包括打斗次数和接吻次数,以及对应的类别标签(Romance或Action)。然后,使用fit方法将数据和标签输入模型进行训练。最后,使用predict方法对新的电影数据(18, 90)进行预测。
在原理分析部分,数据被转化为二维坐标系中的点,通过欧几里得距离(Euclidean distance)计算未知样本与已知样本之间的距离。欧几里得距离公式为E(x,y) = sqrt((x2 - x1)^2 + (y2 - y1)^2)。对于更高维度的数据,可以使用更复杂的距离度量,如曼哈顿距离(Manhattan distance)或余弦相似度(cosine similarity)。
在实际应用中,如果k个最近邻中有多个类别,KNN算法会采用多数投票原则,即将出现次数最多的类别作为预测结果。例如,如果有3个最近邻,分别是类别A、B和C,但A出现了两次,那么未知样本会被分类为A。
KNN算法的优点在于简单易懂,且对于未知样本的预测不需要进行额外的计算。然而,它也有一些缺点,比如计算量大,尤其是当数据集非常大时;另外,它对异常值敏感,一个异常的近邻可能会影响预测结果;并且,K的选择对结果有很大影响,需要通过交叉验证等方法来确定最优的k值。
KNN是一种基础但实用的分类算法,广泛应用于各种领域,如推荐系统、图像识别等。尽管它有一些局限性,但在适当的场景下,通过调整参数和优化距离度量,KNN可以实现相当不错的分类效果。
K-Nearest Neighbor 最邻近分类算法:
简称 KNN,最简单的机器学习算法之一,核心思想俗称“随大流”。是一种分类算法,基
于实例的学习(instance-based learning)和懒惰学习(lazy learning)。懒惰学习:指
的是在训练是仅仅是保存样本集的信息,直到测试样本到达是才进行分类决策。核心想法:
在距离空间里,如果一个样本的最接近的 k 个邻居里,绝大多数属于某个类别,则该样本也
属于这个类别。
范例:假设,我们有这样一组电影数据:
Python 实现方式:
[python] view plain copy
1. import numpy as np
2. from sklearn import neighbors
3.
4. knn = neighbors.KNeighborsClassifier() #取得 knn 分类器
5. data = np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]]) #
data 对应着打斗次数和接吻次数
6. labels = np.array([1,1,1,2,2,2]) #labels 则是对应 Romance 和 Action
7. knn.fit(data,labels) #导入数据进行训练
8. print(knn.predict([18,90]))
需要加载 numpy,sklearn 包,这两个都是机器学习或数据挖掘常用的包。
下载后可阅读完整内容,剩余3页未读,立即下载
2021-09-11 上传
2022-06-01 上传
论文
论文
论文
论文
论文
2023-04-11 上传
2023-08-09 上传

天使的梦魇
- 粉丝: 36
- 资源: 321
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
