IoT监控视频理解:Attention-In-Attention网络架构
49 浏览量
更新于2024-08-27
收藏 3.84MB PDF 举报
"IoT中的监视视频理解的‘Attention-In-Attention’网络"
本文是一篇关于物联网(IoT)中监控视频理解的研究论文,提出了一种名为“Attention-In-Attention”(AIA)的网络架构。在物联网环境中,监控视频的理解是一项关键任务,它涉及到大量数据的处理和分析。传统方法可能难以适应这种复杂场景,因为它们需要从视频中有效地选择并融合多样且互补的特征。
Attention-In-Attention网络是针对这一挑战设计的,其核心思想是层次化地探索和融合注意力机制。传统的注意力机制允许模型关注到输入序列中的重要部分,但AIA网络更进一步,通过内部的注意力机制来增强和细化这一过程。它在端到端的学习过程中自上而下地执行注意力的多层次融合,使得模型能够更精确地捕捉到视频中的关键信息。
AIA网络的结构由两部分组成:全局注意力层和局部注意力层。全局注意力层负责捕获视频的整体上下文信息,提供了一个宏观视角,而局部注意力层则专注于细节,挖掘特定时间片段的局部特征。这两部分相互作用,形成一个内在的注意力交互机制,从而实现对复杂视频场景的深入理解和解释。
论文中,作者将AIA网络应用于两个关键任务:多事件识别和视频字幕生成。多事件识别需要模型能够检测和理解视频中的多个并发事件,这需要对不同时间步的特征进行有效整合。而视频字幕生成则需要模型能够生成准确的文字描述,以概括视频的主要内容,这依赖于对视频内容的深刻理解。实验结果表明,AIA网络在这两个任务上的表现优于现有的其他方法,证明了其在视频理解领域的有效性。
通过AIA网络,研究人员为物联网环境下的视频监控提供了更强大的分析工具,有助于提升安全监控、行为分析以及智能城市等应用的性能。该工作为未来的视觉学习任务提供了新的研究方向,特别是在如何适应性地选择和融合特征方面,对于推动IoT中的智能视频分析技术有着重要的理论和实践价值。
2327-4662 (c) 2017 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/JIOT.2017.2779865, IEEE Internet of
Things Journal
IEEE INTERNET OF THINGS JOURNAL 3
CNN
IS
VS
...
LSTM
v
}{
i
t
}{
i
s
EAM-CNN
EAM-IS
EAM-VS
FAM
man
is
1t
h
t
h
LSTM
LSTM
playing
Multi-Space Feature Extraction Attention-In-Attention Decoding (Multi-Event Recognition/Video Captioning)
h
t
t
h
t
s
h
t
v
h
t
R
h
t
r
Softmax
Softmax
Softmax
Mean Pooling
Sigmoid
walk
turn around
eat/drink
get food/drink
use phone
write
discussion
object handover
0.31
0.22
0.55
0.54
0.59
0.27
0.72
0.65
1t
h
t
h
1t
h
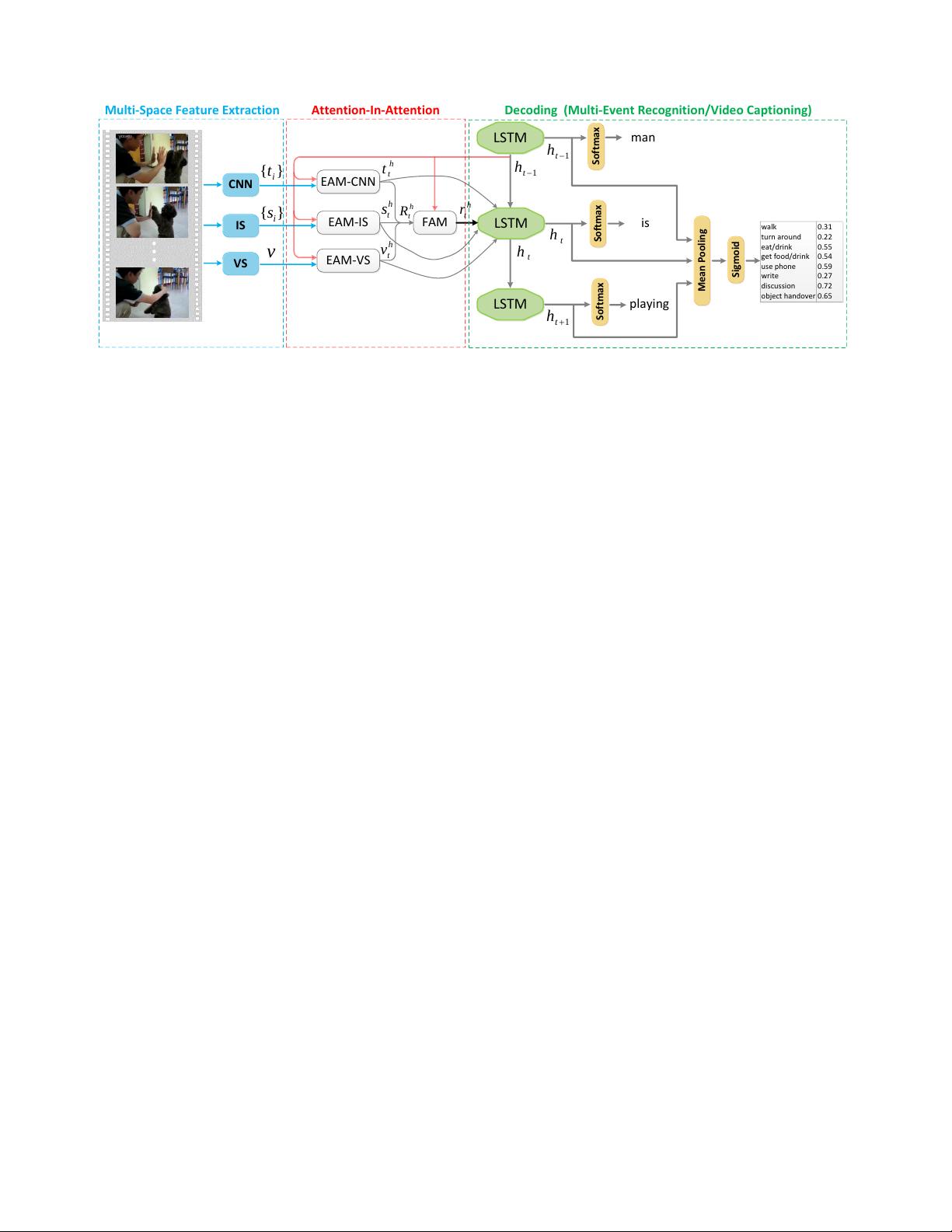
Fig. 2: Illustration of the Attention-In-Attention (AIA) framework, which consists of three components. First, in the Multi-Space Feature
Extraction component, the space-specific features are obtained by multiple off-the-shelf feature extraction methods. Second, the Attention-
In-Attention component is utilized for feature selection and fusion, which includes multiple EAMs and FAM to generate the space-specific
attentive features and further project them into a space with the identical dimension. Third, in the Decoding component, one LSTM unit is
employed to decode the fusion representation and attentive features, where the hidden state is simultaneously fed into both EAMs and FAM
for sentence-induced feature selection and fusion. Particularly, for the multi-event recognition task, we first mean pool the hidden states from
the LSTM unit and then assign a probability distribution by the sigmoid layer. For the video captioning task, the LSTM unit sequentially
generates the description by the softmax layer. The proposed framework is learned end-to-end and we can easily add extra branches for
additional features. CNN: Convolutional Neural Network; IS: Image-wise Semantic; VS: Video-wise Semantic; EAM: Encoder Attention
Module; FAM: Fusion Attention Module.
methods, sequential learning-based methods, and attention-
based methods.
The template-based methods predefine the specific grammar
rules and splits sentences into several terms (e.g., subject,
verb, object, etc.). With such sentence fragments, each term
is aligned with visual content and then the sentence is gen-
erated [18], [19]. Guadarrama et al. [18] designed semantic
hierarchies to choose an appropriate level of the specificity and
accuracy of sentence fragments. Rohrbach et al. [19] learned
to model the relationships between different components of
the input video for descriptions. The advantage of template-
based methods is that the resulting captions are more likely to
be grammatically correct. However, they highly rely on hard-
coded visual concepts and suffer from the implied limits on
the variety of the output.
The sequential learning-based methods have been widely
applied to video captioning, where an encoder maps a se-
quence of video frames to fixed-length feature vectors in the
embedding space and a decoder then generates a translated
sentence in the target language [3], [21], [22], [40]. This
problem is analogous to translate a sequence of words in the
input language to a sequence of words in the output language
in the area of machine translation. The early video captioning
method [22] extended the image caption methods by simply
pooling the features of multiple frames to form a single
representation. Venugopalan et al. [3] applied the sequence to
sequence model to transfer the temporal visual information
to natural language description and further extended it by
inputting both appearance features and optical flow. However,
this strategy can only work for short video clips, which only
contain one major event with limited visual variation, and
ignore the rich fine-grained information conveyed by the video
stream.
Recently, the attention-based methods employ soft attention
mechanism [27] to weight each temporal feature vector in
order to exploit the temporal structure and rich intermediate
description of long videos. For instance, Yao et al. [4] propose
to exploit temporal structure based on soft attention mecha-
nism, which allows to go beyond local temporal modeling
and learns to select the most relevant temporal segments for
video captioning. Ballas et al. [41] leverages convolutional
GRU-RNN to extract visual representation and generate sen-
tence based on the LSTM text-generator with soft-attention
mechanism. Yu et al. [7] further exploit temporal- and spatial-
attention mechanisms to selectively focus on visual elements
during generation.
However, seldom work has been done to hierarchically
learn and integrate the multi-space representations from visu-
al/semantic modalities in the data-driven manner. In this paper,
we explore the comprehensive video representation under the
multi-space features condition for video understanding in IoT
(Internet of Things).
III. ATTENTION-IN-ATTENTION NETWORK (AIA)
In this section, we first give an overview of the proposed
framework and the details of the computational pipeline in
Section III-A. Then, the three key components, including
multi-space feature extraction, attention-in-attention module,
and decoding module, will be detailed in Section III-B, Section
III-C and Section III-D, respectively.
A. Framework Overview
Attention-In-Attention network (AIA) can adaptively &
jointly perform the procedures of space-specific feature se-
lection and multi-space attentive feature fusion. Fig. 2 de-
picts the AIA framework for video captioning. Given several
剩余10页未读,继续阅读
2019-09-05 上传
2021-06-09 上传
2021-03-16 上传
2021-10-03 上传
2021-08-19 上传
2019-09-17 上传
2021-03-27 上传
2021-01-20 上传

weixin_38567813
- 粉丝: 4
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
