深度学习驱动的单幅图像超分辨率技术进展
版权申诉
174 浏览量
更新于2024-06-27
收藏 3.98MB DOCX 举报
"基于深度学习的单幅图片超分辨率重构技术的研究进展,涵盖了从早期理论提出到深度学习应用的历程,以及单幅图片超分辨率的不同方法分类和模型介绍。"
图像超分辨率重构(Image Super-Resolution, SR)是图像处理领域中的一个重要课题,其目的是在不改变图像内容的前提下,通过算法提升低分辨率图像的质量,增加像素密度和细节信息。这项技术尤其关键,因为高分辨率图像可以提供更好的视觉体验,并有利于深入分析和利用图像中的信息。然而,受限于硬件设备的局限,例如信号传输带宽和成像传感器的性能,直接提高成像设备的分辨率既耗时又昂贵。
自20世纪60年代Harris和Goodman首次提出超分辨率的概念以来,该领域的研究经历了多个阶段。早期,由于缺乏有效的实现方法,超分辨率重构主要停留在理论层面。直到1984年,Tsai等人利用傅里叶变换处理多幅低分辨率图像,实现了超分辨率重构的实践应用。随后,随着计算能力的提升和技术的发展,图像超分辨率重构进入了快速发展期。
2014年,Dong等人提出了 SRCNN(Super-Resolution Convolutional Neural Network),将深度学习技术引入单幅图片超分辨率重构领域,极大地推动了该领域的进步。深度学习方法通过训练神经网络来学习低分辨率和高分辨率图像之间的映射关系,能够生成更加逼真的高分辨率图像,显著提升了超分辨率重构的效果。
单幅图片超分辨率重构(Single Image Super-Resolution, SISR)主要区别于多幅图片超分辨率,后者依赖于多帧图像的协同信息来提升分辨率。SISR则仅依靠单一图像进行处理,更具挑战性。在处理方法上,SISR可以分为频域法和空域法。空域法中,包括基于插值的方法,如最近邻插值和双线性插值;基于重构的方法,如基于稀疏表示的重构;以及基于学习的方法,如深度学习模型,如SRCNN、VDSR(Very Deep Super-Resolution)、ESPCN(Efficient Sub-Pixel Convolutional Neural Network)等。
这些深度学习模型通常由卷积层、激活函数、池化层等组成,通过端到端的训练,学习从低分辨率图像到高分辨率图像的非线性映射。例如,SRCNN采用了三层卷积网络,VDSR则有20个卷积层,大大增加了网络的深度,以捕获更复杂的图像特征。ESPCN则引入了子像素卷积层,直接生成高分辨率图像,提高了计算效率。
尽管深度学习在单幅图片超分辨率重构上取得了显著成果,但仍存在挑战,如模型复杂度、计算资源需求、训练数据的质量和多样性等。未来的研究方向可能包括开发更轻量级的网络架构,优化训练策略,以及结合其他技术如先验知识、多模态信息等,以进一步提升超分辨率重构的性能和实用性。

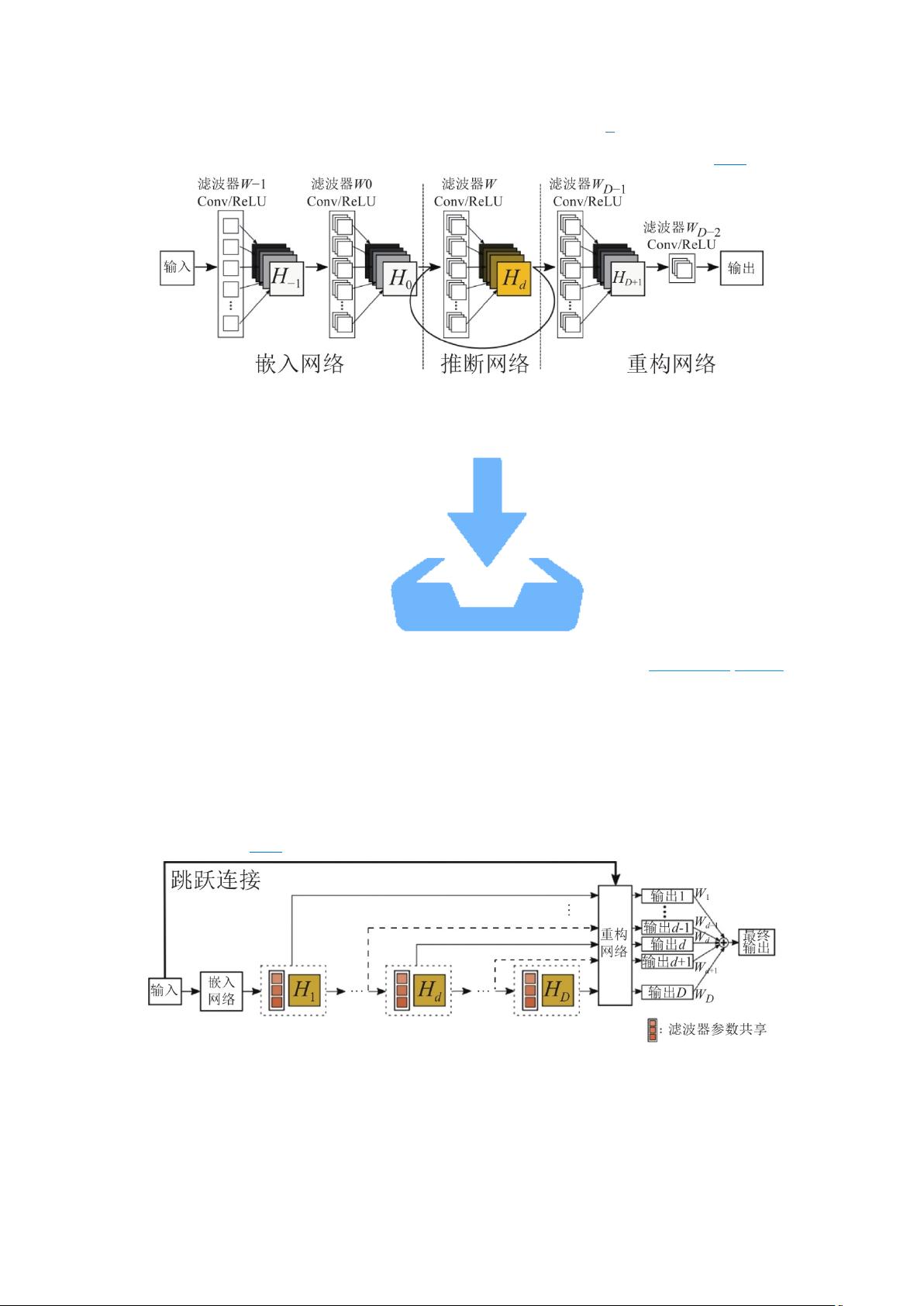
图 5 VDSR 网络模型图
Fig. 5 The network structure of VDSR
下载: 全尺寸图片 幻灯片
输入插值后的低分辨率图像, 网络学习其与高分辨率图像之间的残差, 最后在重建层
加入一个跳跃连接, 利用低分辨率图片与残差重构出高分辨率图片.
VDSR 模型引入残差学习的思想主要有两方面原因: 首先, 网络加深存在梯度消失/爆
炸的问题, 而学习残差可以减轻深度网络训练中此类问题带来的影响; 更重要地, 低分辨率
图像与高分辨率图像之间具有大量相似的低频信息, 而网络学习残差能够避免重复学习低
频信息, 只学习高频细节信息, 从而降低了计算成本, 加快了收敛速度, 节省了运算时间.
然而 VDSR 模型仅在整个网络中加入一个跳跃连接, 并没有很有效地减轻梯度消失的
问题, 因此在训练过程中, 使用较高的学习率加快学习速度使网络尽可能收敛, 然后采用自
适应梯度裁剪策略解决梯度消失/爆炸问题.
VDSR 模型是图像超分辨率领域首个深层网络, 通过采用多层小卷积核, 既能够减少
参数量, 又能够加深网络, 增加感受野, 学习更好的特征. 它的重构效果优于 SRCNN 模型,
证明了随着网络加深, 模型具有更好的表达能力, 与深层次网络在图像其他领域的应用结论
一致.
2.2.2 DRCN 模型
剩余44页未读,继续阅读
2021-10-01 上传
2021-10-25 上传
2022-06-15 上传

罗伯特之技术屋
- 粉丝: 4459
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
