

HWU 2011 06-ch01-003-014-9780123859631 2011/9/8 19:06 Page 4 #2
4 CHAPTER 1 Large-Scale GPU Search
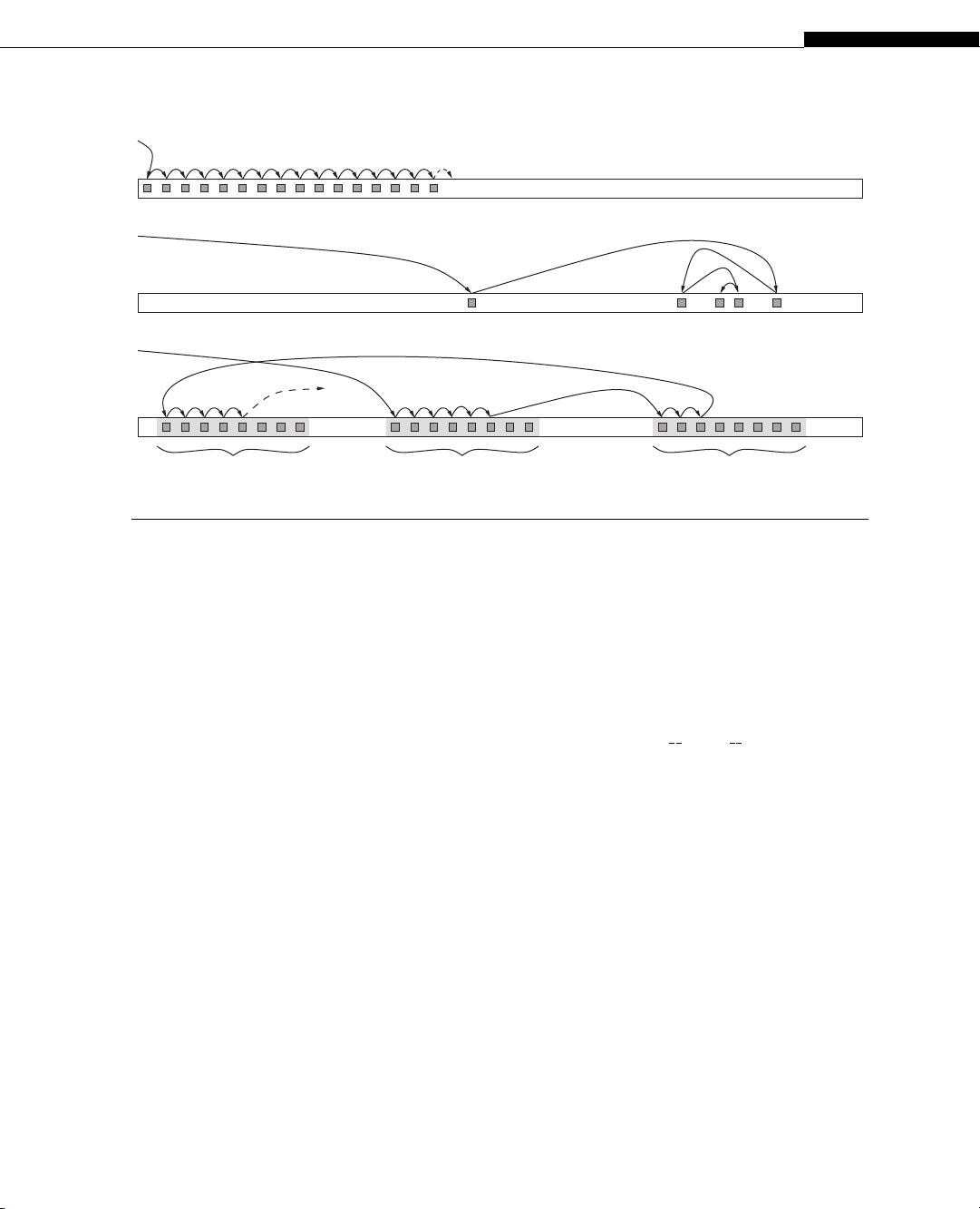
memory subsystem (see Section 1.3.2). With P-ary search we demonstrate how parallel memory access
combined with the superior synchronization capabilities of SIMD architectures like GPUs can be lever-
aged to compensate for memory latency (see the section titled “P-ary Search: Parallel Search from
Scratch”). P-ary search outperforms conventional search algorithms not only in terms of throughput
but also response time (see Section 1.4). Implemented on a GPU it can outperform a similarly priced
CPU by up to three times, and is compatible with existing index data structures like inverted lists and
B-trees. We expect the underlying concepts of P-ary search — parallel memory access and exploit-
ing efficient SIMD thread synchronization — to be applicable to an entire class of memory-bound
applications (see Section 1.5).
1.2 MEMORY PERFORMANCE
With more than six times the memory bandwidth of contemporary CPUs, GPUs are leading the trend
toward throughput computing. On the other hand, traditional search algorithms besides linear scan are
latency bound since their iterations are data dependent. However, as large database systems usually
serve many queries concurrently both metrics — latency and bandwidth — are relevant.
Memory latency is mainly a function of where the requested piece of data is located in the memory
hierarchy. Comparing CPU and GPU memory latency in terms of elapsed clock cycles shows that
global memory accesses on the GPU take approximately 1.5 times as long as main memory accesses
on the CPU, and more than twice as long in terms of absolute time (Table 1.1). Although shared
memory does not operate the same way as the L1 cache on the CPU, its latency is comparable.
Memory bandwidth, on the other hand, depends on multiple factors, such as sequential or random
access pattern, read/write ratio, word size, and concurrency [3]. The effects of word size and read/write
behavior on memory bandwidth are similar to the ones on the CPU — larger word sizes achieve
better performance than small ones, and reads are faster than writes. On the other hand, the impact
of concurrency and data access pattern require additional consideration when porting memory-bound
applications to the GPU.
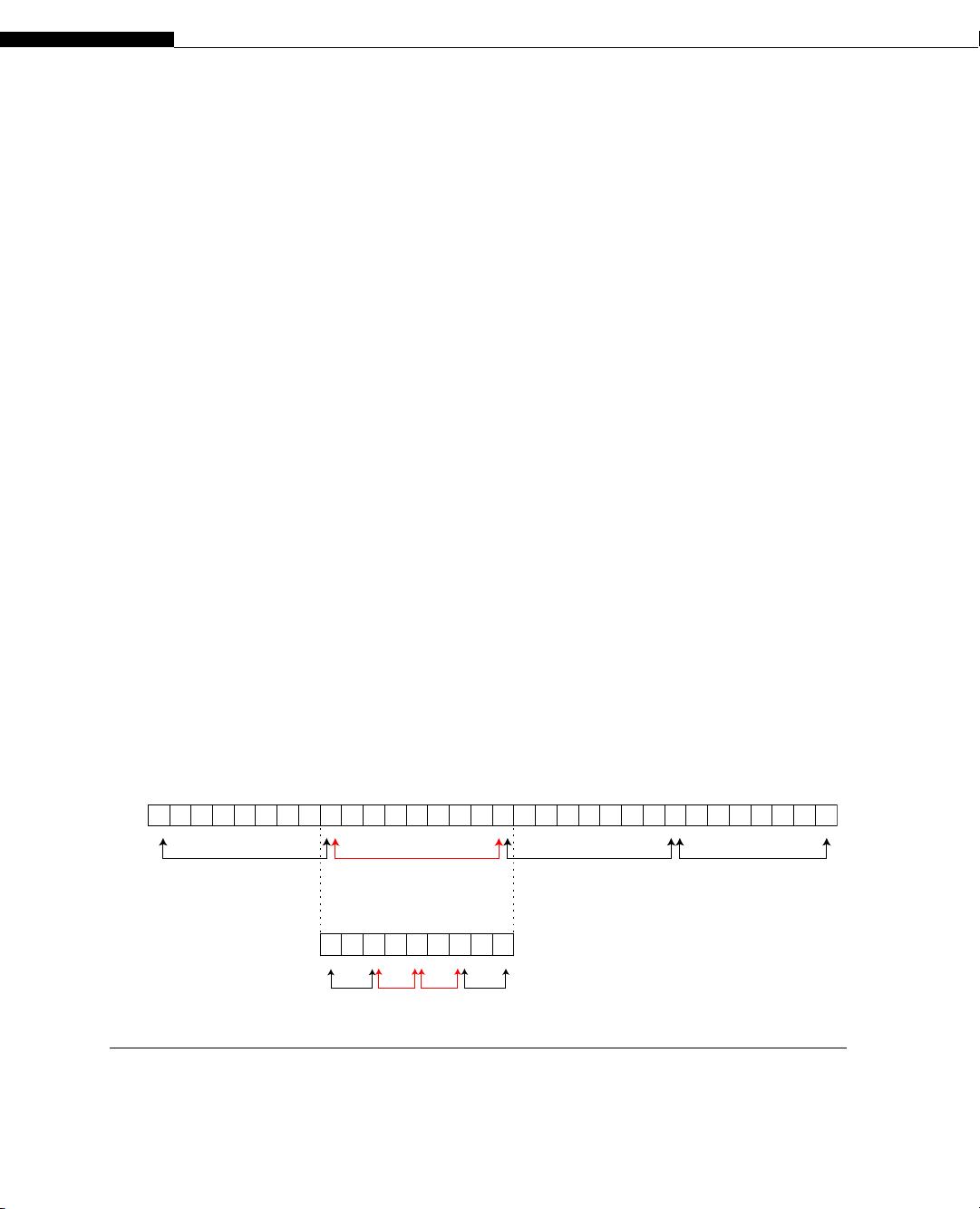
Little’s Law, a general principle for queuing systems, can be used to derive how many concurrent
memory operations are required to fully utilize memory bandwidth. It states that in a system that
processes units of work at a certain average rate W, the average amount of time L that a unit spends
inside the system is the product of W and λ, where λ is the average unit’s arrival rate: L = λW [4].
Applying Little’s Law to memory, the number of outstanding requests must match the product of
latency and bandwidth. For our GTX 285 GPU the latency is 500 clock cycles, and the peak bandwidth
Table 1.1 Cache and Memory Latency Across the Memory Hierarchy for the Processors in Our
Test System
L1/Shared Memory L2 L3 Memory
Processor [cc] [ns] [cc] [ns] [cc] [ns] [cc] [ns]
Intel Core i7 2.6 GHz 4 1.54 10 3.84 40 15.4 350 134.6
NVIDIA GTX285 1.5 GHz 4 2.66 n/a n/a n/a n/a 500 333.3


剩余533页未读,继续阅读

「已注销」
- 粉丝: 15
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


