ALBERT瘦身策略:高效语言理解模型
52 浏览量
更新于2024-08-29
收藏 2.15MB PDF 举报
在第四节中,我们将深入探讨ALBERT,一种针对自然语言理解(NLU)设计的轻量级BERT模型。ALBERT旨在解决BERT模型参数过多的问题,这使得BERT的训练时间和资源成本过高,可能影响模型性能。BERT最初的成功依赖于其全面的网络结构和预训练策略,特别是两种任务——Next Sentence Prediction (NSP) 和 Masked Language Model (MLM)。
回顾BERT,它借鉴了计算机视觉领域中网络深度和宽度增长带来的性能提升,但在NLP中,将模型变得更深更大并不一定意味着效果更好。为了减小BERT的规模,ALBERT提出以下优化策略:
1. **降低模型参数**:
- ALBERT通过减少Transformer处理模块中的参数,这主要集中在自注意力机制中的矩阵乘法部分,通过共享参数、子词嵌入和更高效的注意力机制来降低计算复杂度。这使得模型可以在保持或增强性能的同时显著减少参数数量。
2. **改进NSP任务为SOP**:
- ALBERT将Next Sentence Prediction (NSP) 这一任务替换为Sentence Order Prediction (SOP),这减少了模型对无监督学习任务的依赖,使模型更专注于文本理解和语义表示,从而达到减小模型规模的目的。
3. **移除Dropout**:
- ALBERT摒弃了Dropout这一正则化技术,因为它发现Dropout在预训练阶段可能会干扰上下文信息的传递,从而影响模型的性能。通过其他方式如更有效的模型架构来代替Dropout。
4. **增加训练数据**:
- 提供更多的训练数据有助于模型更好地学习语言模式,ALBERT通过增加训练数据来进一步优化模型,即使在参数减少的情况下也能提升性能。
通过这些优化策略,ALBERT在保持甚至超过BERT在关键评估基准如GLUE和RACE上的表现,实现了轻量化的同时保持了高效率和效果。这展示了在NLP领域中,合理的模型设计和优化策略对于提升模型性能的重要性。ALBERT不仅是一个小型化的BERT,更是一个在资源有限情况下仍能展现出强大性能的实用模型,对于实际应用中的NLP任务有着重要的价值。
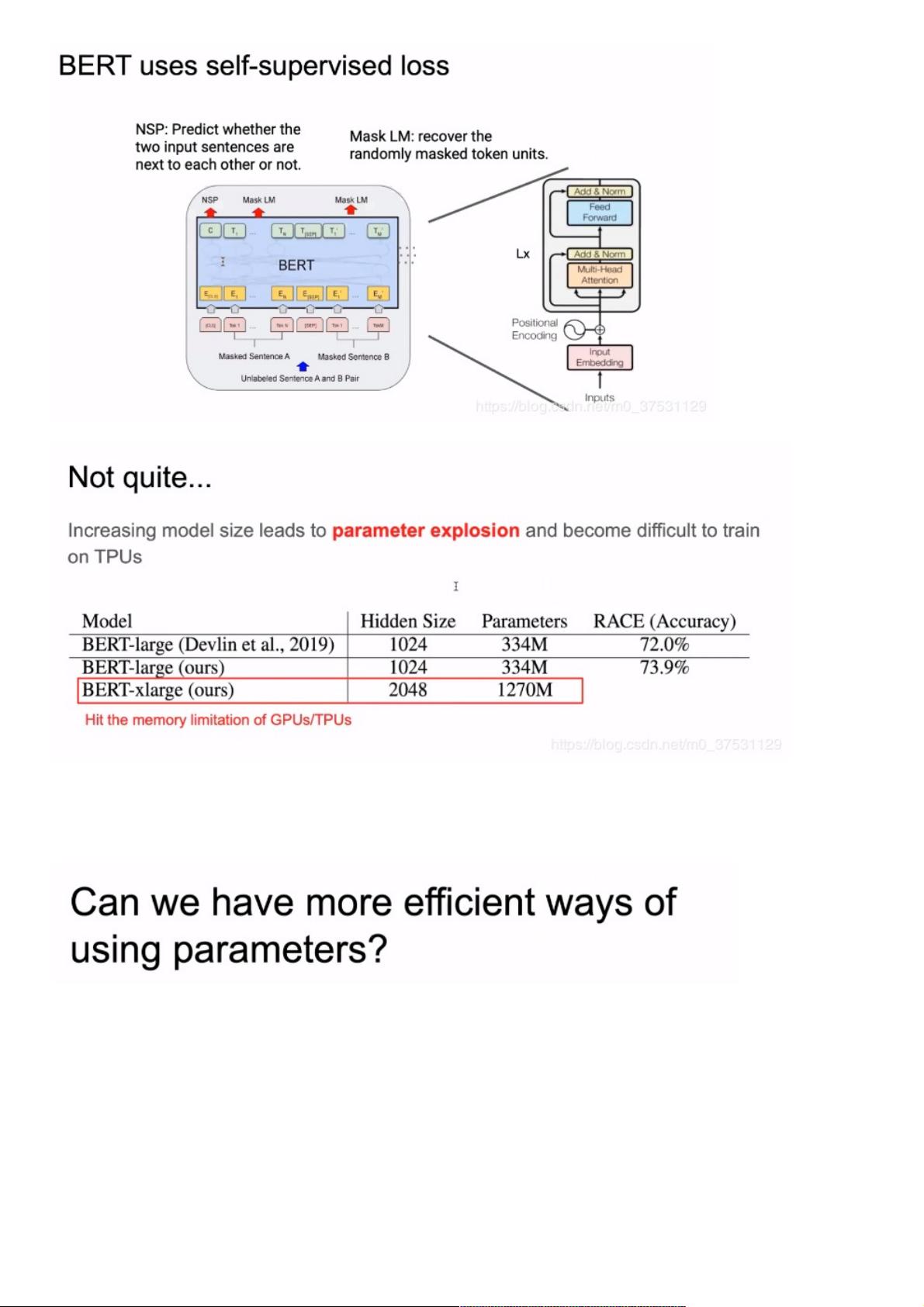
我们看一下BERT,bert里面是结合2个任务 一个是NSP一个是MLM
首先,我们恢复了BERT-Large的结果,并有了一些提升(73.9%)
然后,把宽度变成2倍之后,参数达到了1270M, 很快内存就不够了。
那么,我们能否在减少参数的情况下提高效果?
1. 降低模型参数降低模型参数,加宽加深模型加宽加深模型
剩余12页未读,继续阅读
2020-12-21 上传
2022-04-21 上传
2023-06-07 上传
2023-05-01 上传
2024-04-12 上传
2023-05-13 上传
2023-05-20 上传
2023-05-02 上传

weixin_38559646
- 粉丝: 5
- 资源: 953
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
