Google PaLM 2:先进语言模型提升多语言推理与效率
Google PaLM 2技术手册是一份关于最新人工智能领域的里程碑式成果。它介绍了一种名为PaLM 2的先进语言模型,该模型在多语言处理和推理能力上超越了其前一代——PaLM(Chowdhery等人,2022年的工作)。PaLM 2的设计基础是Transformer架构,它的训练采用了类似于UL2的混合目标方法(Tay等人,2023年),这种设计旨在提高模型的泛化能力和效率。
通过深入的评估,PaLM 2在处理英语和其他多种语言任务以及推理挑战时,展现了显著的质量提升。在不同规模的下游任务中,PaLM 2不仅提供了更高质量的结果,而且在推理速度方面也更为迅速和高效。这种效率的提高使得PaLM 2在实际应用中的部署更加广泛,能以更快的速度响应,从而带来更流畅的人机交互体验。
在诸如BIG-Bench这样的高级推理基准测试中,PaLM 2的表现明显优于PaLM,证明了其在逻辑推理方面的强大实力。此外,PaLM 2在负责 AI 评估中也展现出稳定的表现,特别体现在它能够在保证推理质量的同时,对毒性进行实时控制,这一特性尤为重要,因为它无需额外的成本或对其他功能产生负面影响。
Google PaLM 2作为当前最先进的语言模型,综合了出色的多语言处理、推理能力和高效的计算性能,为人工智能领域树立了新的标杆。无论是技术上的突破还是实际应用场景的考量,PaLM 2都证明了其在推动AI技术发展和应用中的核心地位。

Table 6: BIG-Bench Hard 3-shot results. PaLM and PaLM-2 use direct prediction and chain-of-thought prompting (Wei
et al., 2022) following the experimental setting of Suzgun et al. (2022).
Task Metric
PaLM PaLM 2 Absolute Gain Percent Gain
Direct/CoT Direct/CoT Direct/CoT Direct/CoT
boolean_expressions multiple choice grade 83.2/80.0 89.6/86.8 +6.4/+6.8 +8%/+8%
causal_judgment multiple choice grade 61.0/59.4 62.0/58.8 +1.0/-0.6 +2%/-1%
date_understanding multiple choice grade 53.6/79.2 74.0/91.2 +20.4/+12.0 +38%/+15%
disambiguation_qa multiple choice grade 60.8/67.6 78.8/77.6 +18.0/+10.0 +30%/+15%
dyck_languages multiple choice grade 28.4/28.0 35.2/63.6 +6.8/+35.6 +24%/+127%
formal_fallacies_syllogism_negation multiple choice grade 53.6/51.2 64.8/57.2 +11.2/+6.0 +21%/+12%
geometric_shapes multiple choice grade 37.6/43.6 51.2/34.8 +13.6/-8.8 +36%/-20%
hyperbaton multiple choice grade 70.8/90.4 84.8/82.4 +14.0/-8.0 +20%/-9%
logical_deduction multiple choice grade 42.7/56.9 64.5/69.1 +21.8/+12.2 +51%/+21%
movie_recommendation multiple choice grade 87.2/92.0 93.6/94.4 +6.4/+2.4 +7%/+3%
multistep_arithmetic_two exact string match 1.6/19.6 0.8/75.6 -0.8/+56.0 -50%/+286%
navigate multiple choice grade 62.4/79.6 68.8/91.2 +6.4/+11.6 +10%/+15%
object_counting exact string match 51.2/83.2 56.0/91.6 +4.8/+8.4 +9%/+10%
penguins_in_a_table multiple choice grade 44.5/65.1 65.8/84.9 +21.3/+19.8 +48%/+30%
reasoning_about_colored_objects multiple choice grade 38.0/74.4 61.2/91.2 +23.2/+16.8 +61%/+23%
ruin_names multiple choice grade 76.0/61.6 90.0/83.6 +14.0/+22.0 +18%/+36%
salient_translation_error_detection multiple choice grade 48.8/54.0 66.0/61.6 +17.2/+7.6 +35%/+14%
snarks multiple choice grade 78.1/61.8 78.7/84.8 +0.6/+23.0 +1%/+37%
sports_understanding multiple choice grade 80.4/98.0 90.8/98.0 +10.4/+0.0 +13%/+0%
temporal_sequences multiple choice grade 39.6/78.8 96.4/100.0 +56.8/+21.2 +143%/+27%
tracking_shuffled_objects multiple choice grade 19.6/52.9 25.3/79.3 +5.7/+26.4 +29%/+50%
web_of_lies multiple choice grade 51.2/100.0 55.2/100.0 +4.0/+0.0 +8%/+0%
word_sorting exact string match 32.0/21.6 58.0/39.6 +26.0/+18.0 +81%/+83%
Average - 52.3/65.2 65.7/78.1 +13.4/+12.9 +26% / 20%
Table 7: Evaluation results on MATH, GSM8K, and MGSM with chain-of-thought prompting (Wei et al., 2022) /
self-consistency (Wang et al., 2023). The PaLM result on MATH is sourced from (Lewkowycz et al., 2022), while
the PaLM result on MGSM is taken from (Chung et al., 2022).
a
Minerva (Lewkowycz et al., 2022),
b
GPT-4 (OpenAI,
2023b),
c
Flan-PaLM (Chung et al., 2022).
Task SOTA PaLM Minerva GPT-4 PaLM 2 Flan-PaLM 2
MATH 50.3
a
8.8 33.6 / 50.3 42.5 34.3 / 48.8 33.2 / 45.2
GSM8K 92.0
b
56.5 / 74.4 58.8 / 78.5 92.0 80.7 / 91.0 84.7 / 92.2
MGSM 72.0
c
45.9 / 57.9 - - 72.2 / 87.0 75.9 / 85.8
15

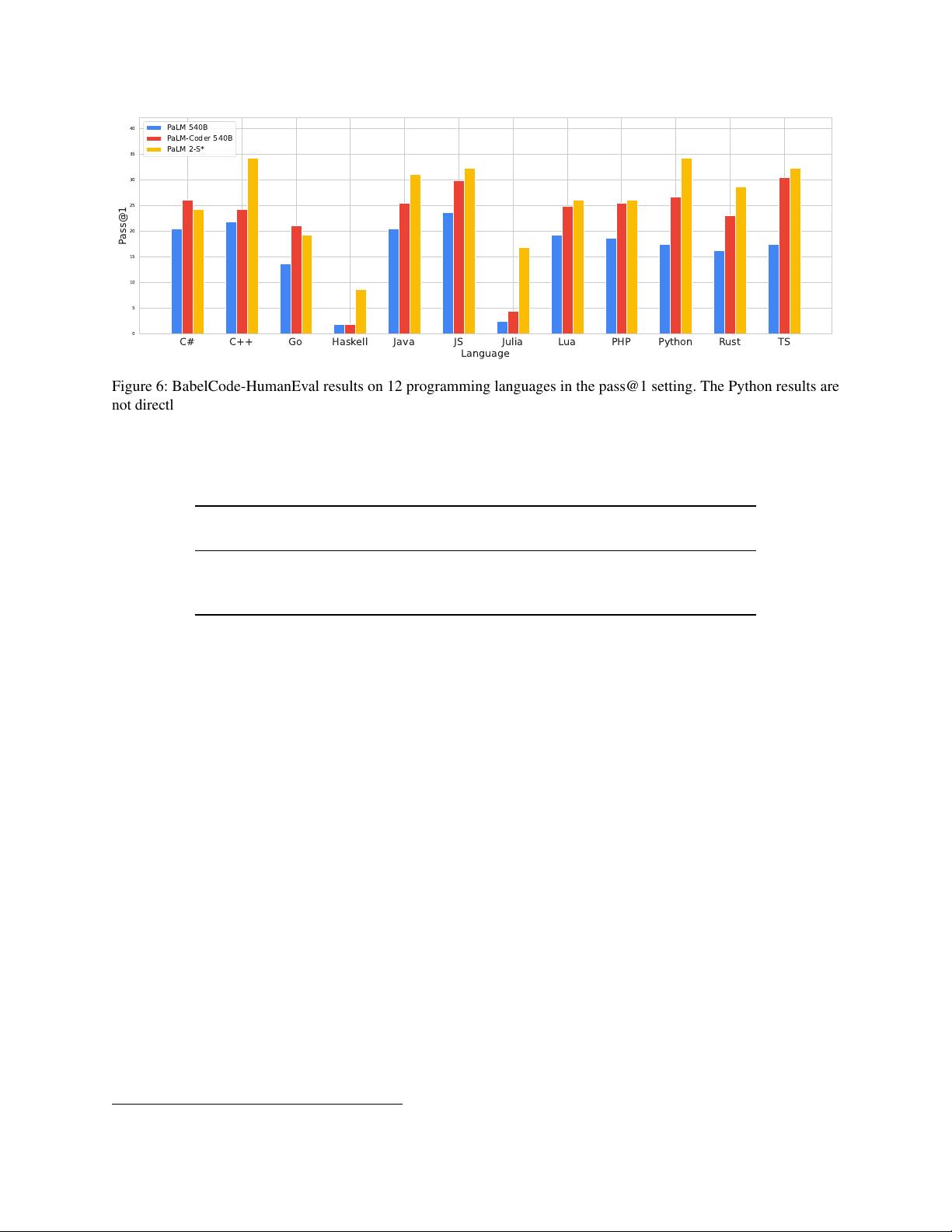


剩余91页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-11 上传
2009-07-10 上传
2023-05-19 上传
2015-08-24 上传
点击了解资源详情
2023-05-29 上传


此星光明
- 粉丝: 8w+
- 资源: 1323
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows_Server_2003_R2之文件服务器资源管理器及文件服务器管理
- 基于遗传算法度约束的最小生成树问题的研究
- 基于像素置乱的加密算法的设计
- On Secret Reconstruction in Secret Sharing Schemes
- XORs in the Air: Practical Wireless Network Coding
- Tomcat实用配置
- On Practical Design for Joint Distributed Source and Network Coding
- Efficient Broadcasting Using Network Coding
- C++中extern “C”含义深层探索.doc
- 用PLC实现道路十字路口交通灯的模糊控制
- pragmatic-ajax
- 使用JSP处理用户注册和登陆
- vi Quick Reference
- 华为交换机使用手册quidway
- 在线考试系统论文.doc在线考试系统论文.doc(1).doc
- Linux操作系统下C语言编程
