

Table 6: BIG-Bench Hard 3-shot results. PaLM and PaLM-2 use direct prediction and chain-of-thought prompting (Wei
et al., 2022) following the experimental setting of Suzgun et al. (2022).
Task Metric
PaLM PaLM 2 Absolute Gain Percent Gain
Direct/CoT Direct/CoT Direct/CoT Direct/CoT
boolean_expressions multiple choice grade 83.2/80.0 89.6/86.8 +6.4/+6.8 +8%/+8%
causal_judgment multiple choice grade 61.0/59.4 62.0/58.8 +1.0/-0.6 +2%/-1%
date_understanding multiple choice grade 53.6/79.2 74.0/91.2 +20.4/+12.0 +38%/+15%
disambiguation_qa multiple choice grade 60.8/67.6 78.8/77.6 +18.0/+10.0 +30%/+15%
dyck_languages multiple choice grade 28.4/28.0 35.2/63.6 +6.8/+35.6 +24%/+127%
formal_fallacies_syllogism_negation multiple choice grade 53.6/51.2 64.8/57.2 +11.2/+6.0 +21%/+12%
geometric_shapes multiple choice grade 37.6/43.6 51.2/34.8 +13.6/-8.8 +36%/-20%
hyperbaton multiple choice grade 70.8/90.4 84.8/82.4 +14.0/-8.0 +20%/-9%
logical_deduction multiple choice grade 42.7/56.9 64.5/69.1 +21.8/+12.2 +51%/+21%
movie_recommendation multiple choice grade 87.2/92.0 93.6/94.4 +6.4/+2.4 +7%/+3%
multistep_arithmetic_two exact string match 1.6/19.6 0.8/75.6 -0.8/+56.0 -50%/+286%
navigate multiple choice grade 62.4/79.6 68.8/91.2 +6.4/+11.6 +10%/+15%
object_counting exact string match 51.2/83.2 56.0/91.6 +4.8/+8.4 +9%/+10%
penguins_in_a_table multiple choice grade 44.5/65.1 65.8/84.9 +21.3/+19.8 +48%/+30%
reasoning_about_colored_objects multiple choice grade 38.0/74.4 61.2/91.2 +23.2/+16.8 +61%/+23%
ruin_names multiple choice grade 76.0/61.6 90.0/83.6 +14.0/+22.0 +18%/+36%
salient_translation_error_detection multiple choice grade 48.8/54.0 66.0/61.6 +17.2/+7.6 +35%/+14%
snarks multiple choice grade 78.1/61.8 78.7/84.8 +0.6/+23.0 +1%/+37%
sports_understanding multiple choice grade 80.4/98.0 90.8/98.0 +10.4/+0.0 +13%/+0%
temporal_sequences multiple choice grade 39.6/78.8 96.4/100.0 +56.8/+21.2 +143%/+27%
tracking_shuffled_objects multiple choice grade 19.6/52.9 25.3/79.3 +5.7/+26.4 +29%/+50%
web_of_lies multiple choice grade 51.2/100.0 55.2/100.0 +4.0/+0.0 +8%/+0%
word_sorting exact string match 32.0/21.6 58.0/39.6 +26.0/+18.0 +81%/+83%
Average - 52.3/65.2 65.7/78.1 +13.4/+12.9 +26% / 20%
Table 7: Evaluation results on MATH, GSM8K, and MGSM with chain-of-thought prompting (Wei et al., 2022) /
self-consistency (Wang et al., 2023). The PaLM result on MATH is sourced from (Lewkowycz et al., 2022), while
the PaLM result on MGSM is taken from (Chung et al., 2022).
a
Minerva (Lewkowycz et al., 2022),
b
GPT-4 (OpenAI,
2023b),
c
Flan-PaLM (Chung et al., 2022).
Task SOTA PaLM Minerva GPT-4 PaLM 2 Flan-PaLM 2
MATH 50.3
a
8.8 33.6 / 50.3 42.5 34.3 / 48.8 33.2 / 45.2
GSM8K 92.0
b
56.5 / 74.4 58.8 / 78.5 92.0 80.7 / 91.0 84.7 / 92.2
MGSM 72.0
c
45.9 / 57.9 - - 72.2 / 87.0 75.9 / 85.8
15

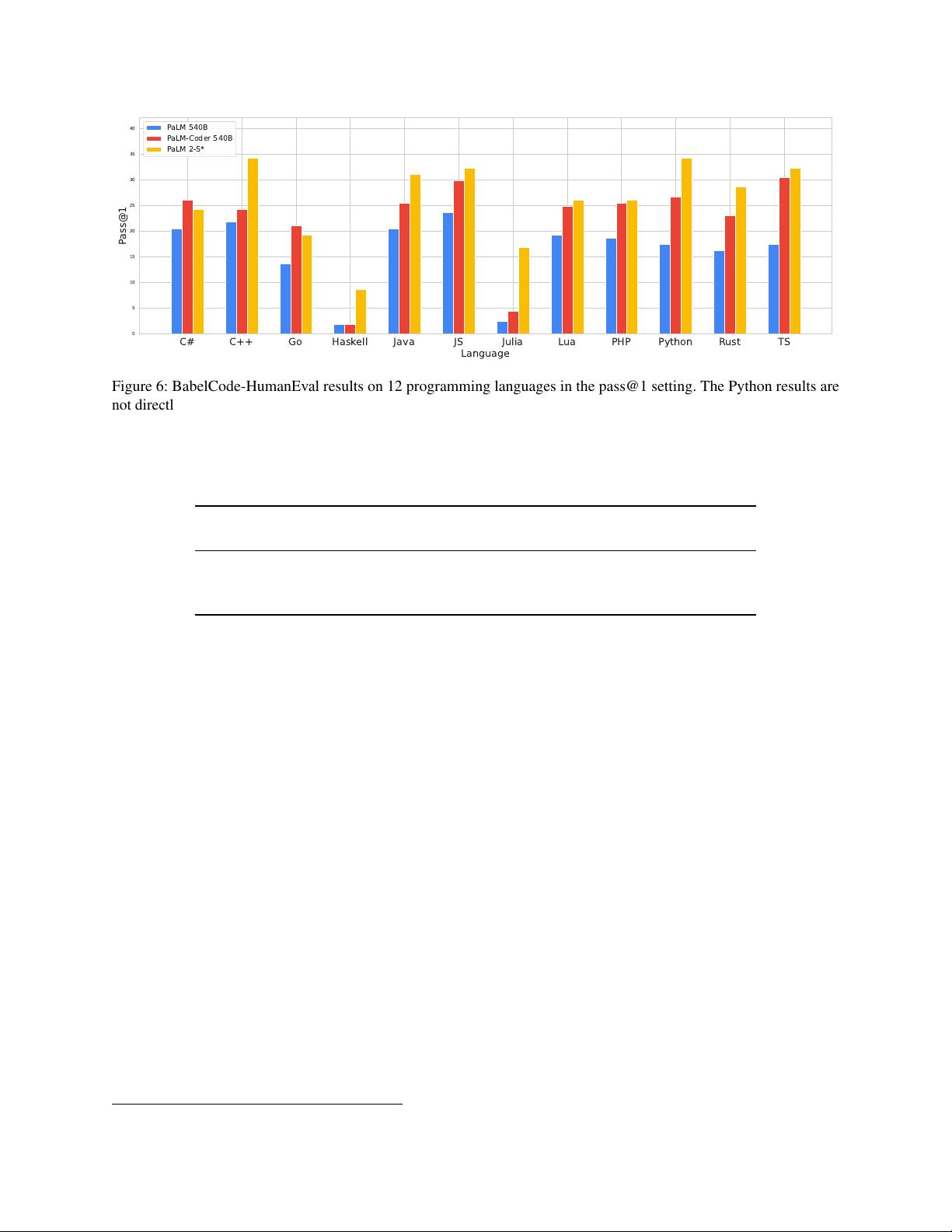


剩余91页未读,继续阅读

流水不腐程序
- 粉丝: 651
- 资源: 952
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型矿用本安直流稳压电源设计:双重保护电路
- 煤矿掘进工作面安全因素研究:结构方程模型
- 利用同位素位移探测原子内部新型力
- 钻锚机钻臂动力学仿真分析与优化
- 钻孔成像技术在巷道松动圈检测与支护设计中的应用
- 极化与非极化ep碰撞中J/ψ的Sivers与cos2φ效应:理论分析与COMPASS验证
- 新疆矿区1200m深孔钻探关键技术与实践
- 建筑行业事故预防:综合动态事故致因理论的应用
- 北斗卫星监测系统在电网塔形实时监控中的应用
- 煤层气羽状水平井数值模拟:交替隐式算法的应用
- 开放字符串T对偶与双空间坐标变换
- 煤矿瓦斯抽采半径测定新方法——瓦斯储量法
- 大倾角大采高工作面设备稳定与安全控制关键技术
- 超标违规背景下的热波动影响分析
- 中国煤矿选煤设计进展与挑战:历史、现状与未来发展
- 反演技术与RBF神经网络在移动机器人控制中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


