详解:Impala与Hive:实时分析与批处理查询的区别与优化
版权申诉
86 浏览量
更新于2024-09-10
收藏 416KB PDF 举报
Impala与Hive的关系深入探讨
Impala是一种建立在Hive之上的大数据实时分析查询引擎,它与Hive的主要区别在于查询性能和使用场景。Hive是一个基于Hadoop的数据仓库工具,主要设计用于长时间的批处理查询,而Impala则专注于提供更快的交互式SQL查询体验,适用于实时数据分析。
首先,Impala利用Hive的元数据库(Metastore),存储所有元数据,使得Impala能够无缝访问Hive的结构和表信息。其SQL解析能力兼容Hive的语法,执行Hive SQL语句的子集,尽管功能还在持续增强中。这使得数据分析人员能够利用Hive进行预处理,然后在Impala上进行快速的数据分析,提高了分析速度。
在技术层面,Impala避免了MapReduce在交互式查询中的性能瓶颈。它采用一种称为“查询执行计划树”的机制,而非MapReduce任务序列,这样可以减少磁盘I/O操作和启动延迟。使用LLVM编译器生成针对特定查询的运行代码,减少函数调用,提高执行效率。同时,Impala还利用现代硬件指令集(如SSE4.2)和优化的IO调度,直接从磁盘读取数据块,支持本地计算校验和,进一步提升性能。
在数据存储方面,Impala与Hive共享相同的存储数据池,这意味着它们都能处理多种数据格式,但Impala倾向于选择那些能提供更好性能的格式。此外,Impala更倾向于将中间结果保留在内存中,通过网络流式传输,而不是写入磁盘,从而最大限度地利用内存资源。
总结来说,Impala和Hive在Hadoop生态系统中有着互补的角色。Hive适合长期批处理,而Impala则是实时分析的利器。两者都支持ODBC/JDBC接口,提供SQL交互,并且共享许多底层组件。然而,Impala通过优化的执行策略和内存管理,显著提升了查询速度和响应性,使其在交互式分析场景中表现出色。理解并掌握这两者之间的差异,可以帮助数据分析师和开发者根据具体需求选择合适的工具。
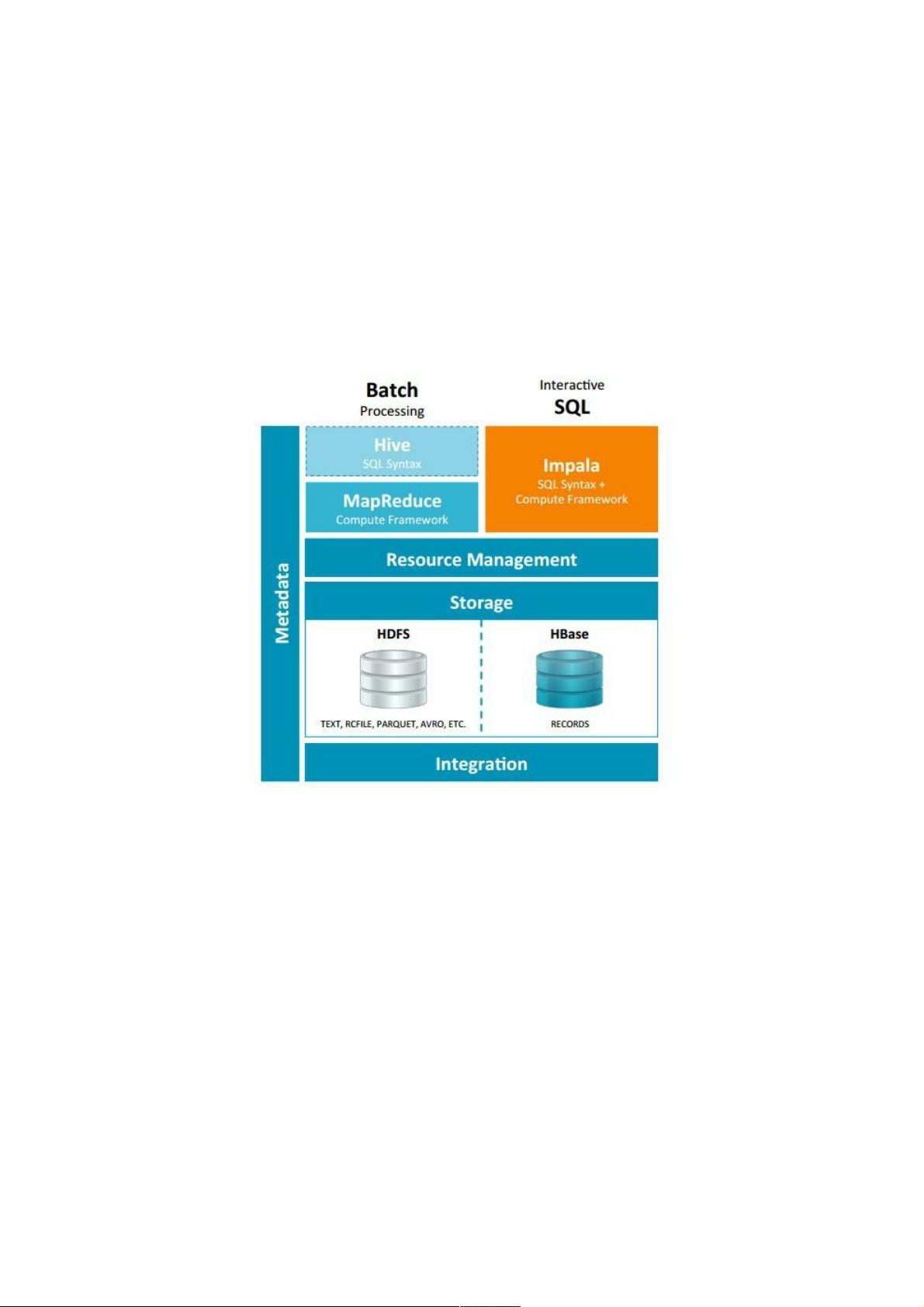
Impala和和Hive的关系(详解)的关系(详解)
Impala和Hive的关系
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的
metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
与Hive的关系
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共
同之处,如数据表元数 据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关
系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快
速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进
行快速的数据分析。
Impala相对于Hive所使用的优化技术
1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面
向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发
执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入
磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了
MapReduce启动时间。
2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
3、充分利用可用的硬件指令(SSE4.2)。
4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地
代码计算checksum。
5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
Impala与Hive的异同
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:两者使用相同的元数据。
SQL解释处理:比较相似都是通过词法分析生成执行计划。
下载后可阅读完整内容,剩余4页未读,立即下载
2017-12-10 上传
2018-09-18 上传
点击了解资源详情
2014-08-23 上传
2020-09-15 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38722164
- 粉丝: 2
- 资源: 912
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
