Impala与Hive:大数据实时分析对比
131 浏览量
更新于2024-08-28
收藏 416KB PDF 举报
"Impala和Hive是大数据领域中两种重要的数据查询工具,它们在Hadoop生态系统中发挥着各自的作用。Impala是一个实时分析查询引擎,它直接利用Hive的元数据库,实现对Hive SQL语义的兼容。而Hive则更适合于长时间的批处理查询。两者在使用上有很多相似之处,比如都支持ODBC/JDBC驱动、SQL语法和多种文件格式。然而,Impala通过优化技术如避免MapReduce、使用LLVM、硬件指令利用、高效的IO调度和内存使用,提供更快的交互式查询性能。尽管它们在数据存储上共用HDFS,但Impala更强调实时性,而Hive则倾向于批量处理。"
在Hadoop大数据平台中,Impala和Hive的关系可以被视为互补的角色。Impala的设计目标是解决Hive在交互式查询上的性能瓶颈,它不需要像Hive那样依赖MapReduce进行计算,而是采用C++编写的分布式查询引擎,这使得查询速度显著提升。Impala的执行计划由一系列操作构成,这些操作在各个节点之间直接通信,减少了中间结果的磁盘I/O,从而提高了响应速度。
此外,Impala使用LLVM动态编译技术生成优化过的机器代码,以减少函数调用开销,进一步提升执行效率。它还利用现代处理器的硬件指令,如SSE4.2,以增强计算性能。在IO调度方面,Impala能更好地利用多磁盘环境,支持直接读取数据块和本地校验和计算,降低了延迟。
在数据存储层面,Impala和Hive都使用Hadoop的HDFS作为底层存储系统,这意味着用户可以在Hive中预处理数据,然后用Impala进行快速分析,这样结合使用,可以兼顾数据处理的灵活性和查询的高效性。
Impala和Hive虽然有重叠的功能,但它们各自针对不同的场景和需求。Hive适合于大规模数据的离线分析,而Impala则适用于需要快速响应的交互式查询。两者结合使用,可以为用户提供一个全面且高效的大数据分析解决方案。
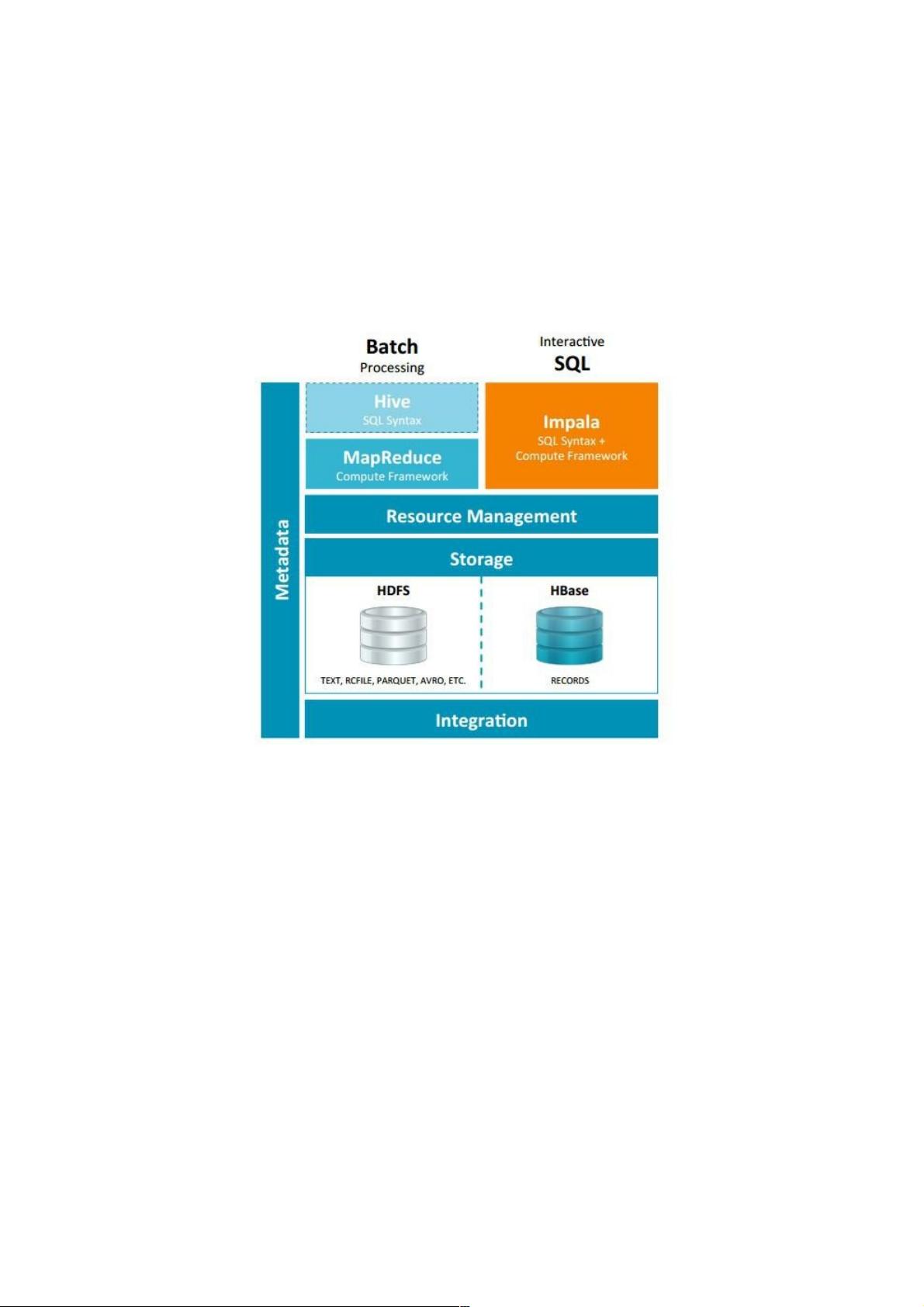
Impala和和Hive的关系(详解)的关系(详解)
Impala和Hive的关系
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的
metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
与Hive的关系
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共
同之处,如数据表元数 据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关
系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快
速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进
行快速的数据分析。
Impala相对于Hive所使用的优化技术
1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面
向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发
执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入
磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了
MapReduce启动时间。
2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
3、充分利用可用的硬件指令(SSE4.2)。
4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地
代码计算checksum。
5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
Impala与Hive的异同
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:两者使用相同的元数据。
SQL解释处理:比较相似都是通过词法分析生成执行计划。
执行计划:
Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query
下载后可阅读完整内容,剩余4页未读,立即下载
2020-08-25 上传
点击了解资源详情
2014-08-23 上传
2020-09-15 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38637878
- 粉丝: 3
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- flexloan:flexloan项目存储库
- innervate:网站innervate.in的源文件
- react-ts-eslint:使用启用了TS和ESLint的create-react-app创建的React应用
- Spider Search-crx插件
- legacy-sal:这是旧版存储库。 请在此处找到维护的sal回购:https:github.comsalopensourcesal
- py_project
- shizihebingwenti.rar_数值算法/人工智能_Visual_C++_
- Convenient Redmine-crx插件
- 【创新创业材料】农业相关可行性报告.rar
- CNN_LSTM_CTC_Tensorflow:使用Tensorflow实现的基于CNN + LSTM + CTC的OCR
- mytcg-f3-plugins:MyTCG-f3插件注册表
- Card Color Titles for Trello-crx插件
- matlab拟合差值代码-dissonant:音乐和弦不和谐模型
- CodesForPlacement
- smithchart.rar_matlab例程_matlab_
- congresstweets:国会每日Twitter输出的数据集
