Hadoop详解:核心技术与组件解析
需积分: 10 72 浏览量
更新于2024-07-23
1
收藏 1.03MB DOC 举报
Hadoop是一个开源的大数据处理框架,由Nutch和Lucene的创始人Doug Cutting于2006年发起,得名于他的儿子模仿小象发出的音节。Hadoop最初的目标是为大规模分布式数据处理提供解决方案,其核心组件包括Hadoop Common、Hadoop Distributed File System (HDFS)、MapReduce模型,以及其他扩展组件如HBase、Hive和Cassandra。
Hadoop Common是Hadoop的基础,它包含文件系统功能以及远程过程调用(RPC)的序列化函数,这些功能对于分布式计算至关重要。HDFS是一个高吞吐量、可靠的分布式文件系统,它是Google的GFS(Google File System)的开源实现,允许数据在大量廉价硬件上进行存储和访问。
MapReduce是一种并行计算模型,它将复杂的计算任务划分为多个独立的部分,分布到集群的不同节点上执行,然后将结果合并,适用于处理海量数据。它的设计灵感来源于Google的内部技术,是Hadoop处理大数据的主要工具。
HBase是一个基于列族的分布式数据库,它是Google Bigtable的开源版,用于存储非结构化或半结构化的数据,提供了高并发的读写性能。Hive则是一个数据仓库工具,它允许用户编写SQL-like查询,以便对存储在Hadoop上的大量数据进行汇总和分析。
Cassandra是一个分布式NoSQL数据库,由Facebook开发,后来被Apache基金会接手并广泛应用在云计算环境中。Cassandra以其高可用性和分布式特性,非常适合大规模数据的存储和查询。
Hadoop的体系结构主要包括NameNode(主服务器,负责文件系统的元数据管理和数据块分配)、SecondaryNameNode(辅助节点,用于备份和监控NameNode状态)、DataNode(数据存储节点,负责存储和管理HDFS的数据块)以及TaskTracker(负责执行MapReduce任务)和JobTracker(负责任务调度和协调)。
整体来说,Hadoop通过其分布式架构,使得大规模数据的处理和存储变得可行,是现代大数据处理不可或缺的一部分。随着技术的发展,Hadoop也在不断迭代升级,如Hadoop 1.03版本,适应了云计算时代的需要。同时,Hadoop生态系统也在不断扩展,与更多工具和服务集成,共同推动大数据领域的发展。
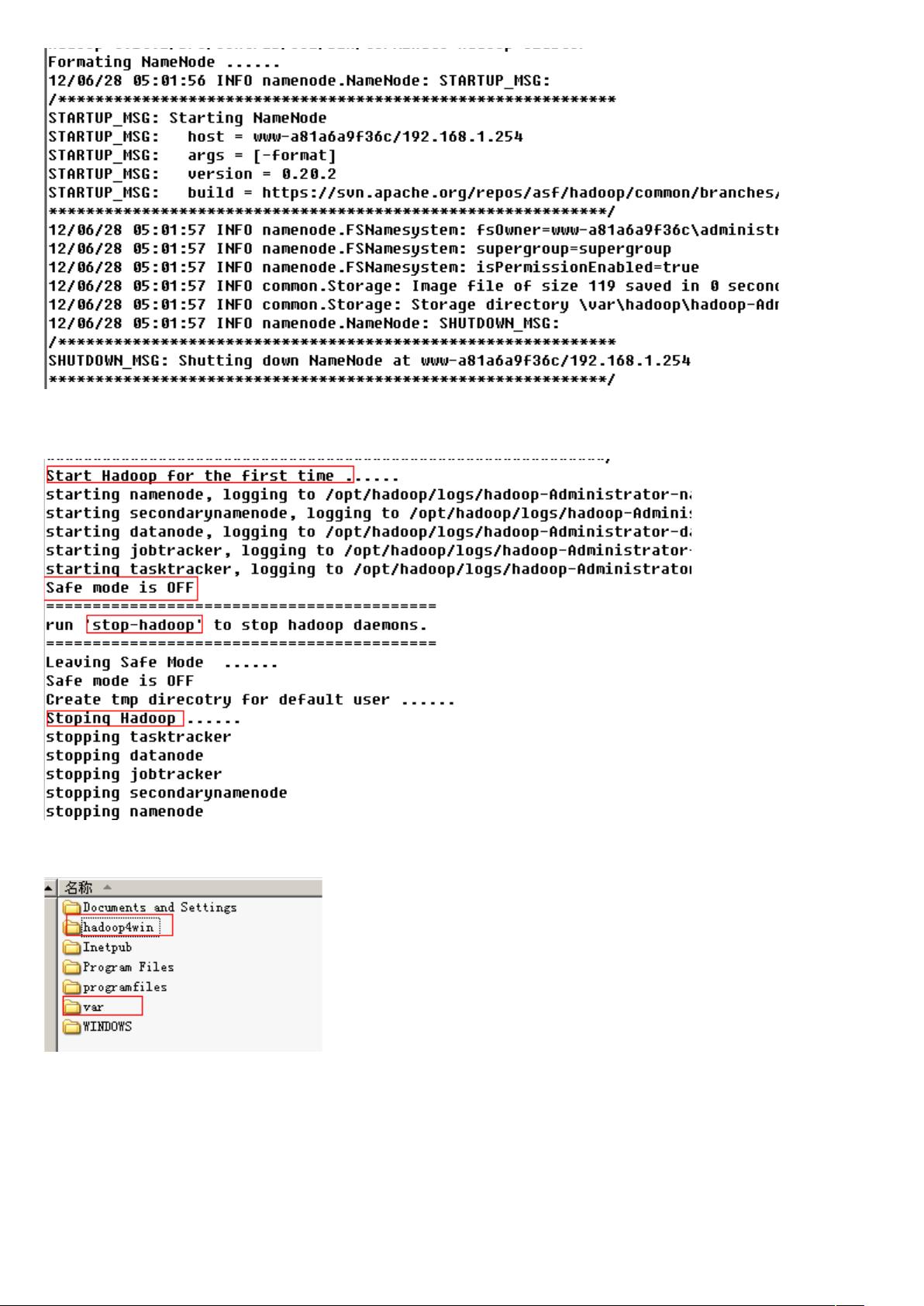
安装细节-测试启动所有节点:
注意下面的停止顺序:
Hadoop 安装完成以后的目录:
hadoop4win 是 Linux+jdk+hadoop 的安装目录。
Var 是 namenode 格式化以后生成的目录 。即 hdfs 的目录。
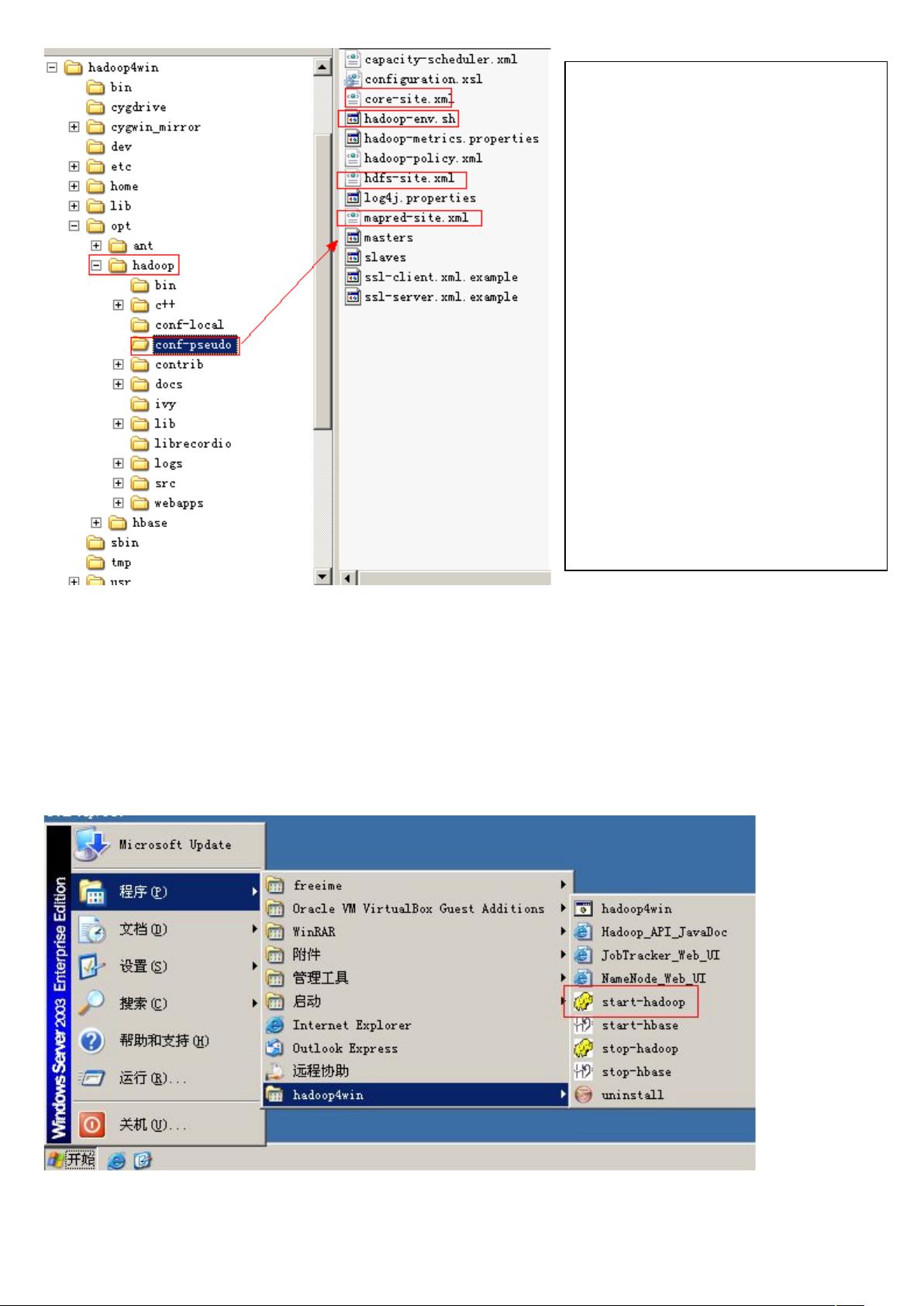
进入 hadoop4win:
剩余35页未读,继续阅读
2021-05-20 上传
2013-12-03 上传
2017-05-16 上传
2022-10-06 上传
2018-11-11 上传









