提升无锁同步速度:内存回收对性能的影响研究
20 浏览量
更新于2024-08-25
收藏 483KB PDF 举报
本文档深入探讨了"Making Lockless Synchronization Fast - Performance Implications of Memory Reclamation"的主题,由Thomas E. Hart、Paul E. McKenney和Angela Demke Brown共同撰写,他们分别来自加拿大多伦多大学和美国IBM Beaverton的计算机科学部门以及Linux技术中心。在现代多处理器系统中,开发高性能并发应用仍然是一项挑战。许多程序员为了提高性能而避免使用锁,转而选择无阻塞同步来防止死锁、优先级反转和 convoying(一种并发执行时的资源争夺现象)。
关键问题在于,这些无锁数据结构设计通常依赖于内存回收机制,当数据节点不再被使用时,需要自动释放内存。然而,现有的内存回收方案的性能评估并不全面。论文作者们首次对三种近期的内存回收策略进行了公平且全面的对比:基于静止状态的回收、基于周期的回收(epoch-based reclamation)和基于危险指针的回收。他们采用了一种灵活的微基准测试工具来进行研究。
研究结果显示,没有一种全局适用的内存回收方法能在所有情况下都提供最佳性能。每种策略都有其优势和局限性,具体取决于应用程序的特性和多处理器系统的特性。静态回收可能导致延迟,因为必须等待所有活动线程进入静止状态;基于周期的回收可能在减少上下文切换的同时增加内存碎片;而危险指针则依赖于精确的指针更新,错误处理可能导致性能下降。
因此,为了优化锁无关的同步算法性能,开发者需要根据具体场景选择合适的内存回收策略,并可能需要对现有方案进行微调或自定义实现。理解并权衡这些不同的内存管理策略对于编写高效并发代码至关重要,尤其是在追求极致性能的多线程环境中。同时,这篇论文也为未来内存回收算法的设计和优化提供了有价值的研究基础。
Making Lockless Synchronization Fast:
Performance Implications of Memory Reclamation
Thomas E. Hart
1∗
, Paul E. McKenney
2
, and Angela Demke Brown
1
1
University of Toronto
2
IBM Beaverton
Dept. of Computer Science Linux Technology Center
Toronto, ON M5S 2E4 CAN Beaverton, OR 97006 USA
{tomhart, demke}@cs.toronto.edu paulmck@us.ibm.com
Abstract
Achieving high performance for concurrent app lications
on modern multiprocesso rs remains challenging. Many pro-
grammers av oid locking to improve performance, while o th-
ers replace locks with non-blocking synchronization to pro-
tect against deadlock, priority inversion, and convoying. In
both cases, dynamic data structures that avoid locking, re-
quire a memory reclamation scheme that reclaims nodes
once they are no longer in use.
The performance of existing memory reclamation
schemes has not been thoroughly evaluate d. We conduct
the first fair and comprehen sive comparison of three recent
schemes—quiescent-state-based r e c l a m a t i o n, epoch-based
reclamation, and hazard-pointer-based reclamation—using
a flexible microbenchmark. Our results show that there is
no globally optimal scheme. When evaluating lockless syn-
chronization, programmers and algorithm designers should
thus carefully consider the data structure, the workload,
and the execution environ ment, each of which can dramati-
cally affect memory reclamat i o n performance.
1 Introduction
As multiprocessors become mainstrea m , multithreaded
applications will become more common, increa sing the
need for efficient coordination of concurrent accesses to
shared data struc tures. Traditional locking requires expen-
sive atomic operations, such as com pare-and-swap (CAS),
even when locks are uncontended. For example, acquiring
and releasing an uncontended spinlock req uires over 400
cycles on an IBM
R
!
POWER
TM
CPU. Therefore, many re-
searchers recommend avoiding lock ing [2, 7, 22]. Some
systems, such as Linux
TM
, use c oncurrently-read able syn-
chronization, which uses locks for updates but not for read s.
∗
Supported by an NSERC Canada Graduate Scholarship.
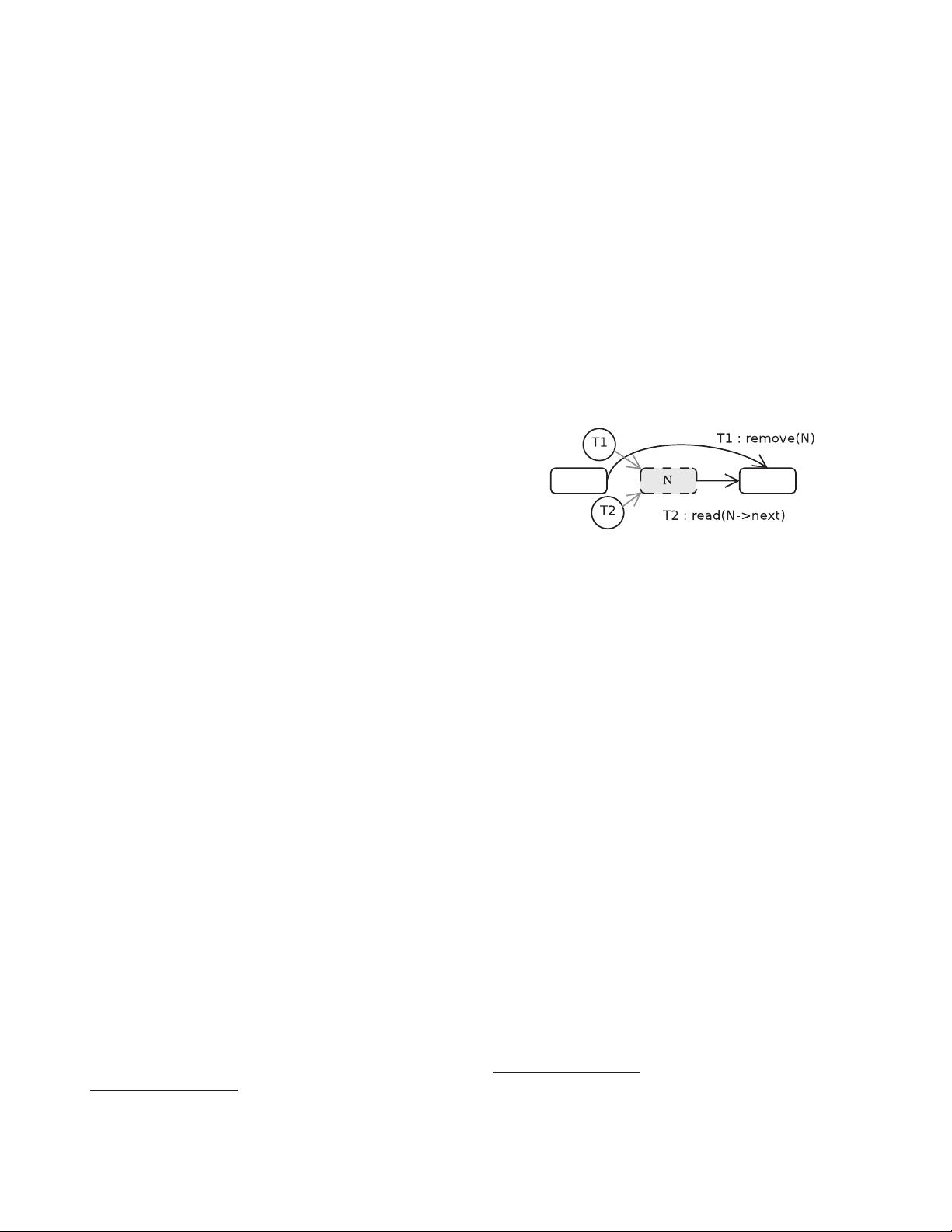
Figure 1. Read/reclaim race.
Locking is also susceptible to priority inversion, convoying,
deadlock , and blocking due to thread failure [3, 10], leading
researchers to pursue non-blocking (or lock-free) synchro-
nization [6, 12, 13, 1 4, 16, 29]. In some cases, lock-free
approaches can bring perform ance benefits [25]. For clar-
ity, we describe all strategies that avoid locks as lockless.
A major challenge for lockless synchroniz ation is han-
dling the read/reclaim races that arise in dynamic data
structures. Fig ure 1 illustrates the problem: thread T1 re-
moves node N fro m a list while thread T2 is referencin g it.
N ’s memory must be rec laimed to allow reuse, lest memory
exhaustion block all threads, but such reuse is unsafe while
T2 continues referencing N . For lan guages like C, where
memory m ust be explicitly recl a i m e d (e.g. via free()),
program mers must combine a memory reclamation scheme
with their lockl e ss d a t a structures to resolve these r ac es .
1
Several such reclamation schemes have been proposed.
Programmers need to understand the semantics and the
performance imp lications of ea ch scheme, since the over-
head of inefficien t recla mation can be worse than that of
locking. For example, reference counting [ 5, 29] has high
overhead in the base case and scales po orly with data-
structure size. Thi s is unacce ptable when performance is
the motivation for lock less synchronization. Unf ortunately,
there is no single optimal scheme and existing work is rela-
tively silent on factors affecting reclamat i on performance.
1
Reclamation is subsumed into automatic garbage collectors in envi-
ronments that provide them, such as Java
TM
.
1-4244-0054-6/06/$20.00 ©2006 IEEE
下载后可阅读完整内容,剩余9页未读,立即下载
2022-09-24 上传
2021-05-16 上传
2021-04-14 上传
2022-09-14 上传
2019-09-03 上传
2022-03-18 上传
2021-04-02 上传
2021-01-28 上传
2018-10-15 上传

weixin_38654915
- 粉丝: 7
- 资源: 995
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
