FP-Tree算法详解与优化
"FP-Tree算法是数据挖掘领域中用于频繁模式发现的一种高效算法,尤其适合处理大规模数据集。该算法旨在解决频繁项集挖掘中的挑战,如多次交易数据库扫描、大量候选项集以及计算支持度的繁重工作。本资料以PPT形式介绍了FP-Tree算法及其相关概念,对初学者具有一定的学习帮助。"
1. FP-growth算法
FP-growth是针对频繁模式挖掘中挑战的一种解决方案,它改进了早期的Apriori算法。Apriori算法需要多次扫描交易数据库,生成大量的候选项集,并进行支持度计数,这在处理大数据集时效率低下。
2. 频繁模式挖掘的挑战
频繁模式挖掘面临的主要挑战包括:需要多次扫描交易数据库、候选项集数量庞大,以及为这些候选集计算支持度的工作量大。这些问题导致了计算时间和存储需求的显著增加。
3. FP-Tree结构
FP-Tree是FP-growth算法的核心数据结构,它是一种倒置的前缀树。在这个树中,频繁项按照它们在事务中的出现顺序逆序存储,共享前缀的项会被压缩到同一路径上。这种结构减少了数据的存储需求,并且有助于快速查找频繁项集。
4. 使用FP-Tree挖掘频繁模式
通过构建FP-Tree,可以有效地减少对数据库的扫描次数,同时减少候选项集的生成。一旦FP-Tree建立,可以通过遍历树来挖掘频繁项集,无需再次扫描原始数据库。这种方法显著提高了算法的效率。
5. 优化Apriori算法
FP-growth算法的优化策略主要集中在减少数据库扫描次数、缩小候选项集范围以及简化支持度计数。此外,还可以利用约束条件来进一步提高效率,例如,通过应用反单调性约束(如价格总和小于5),可以在早期阶段排除不满足条件的候选集,从而降低搜索空间。
6. Apriori与约束
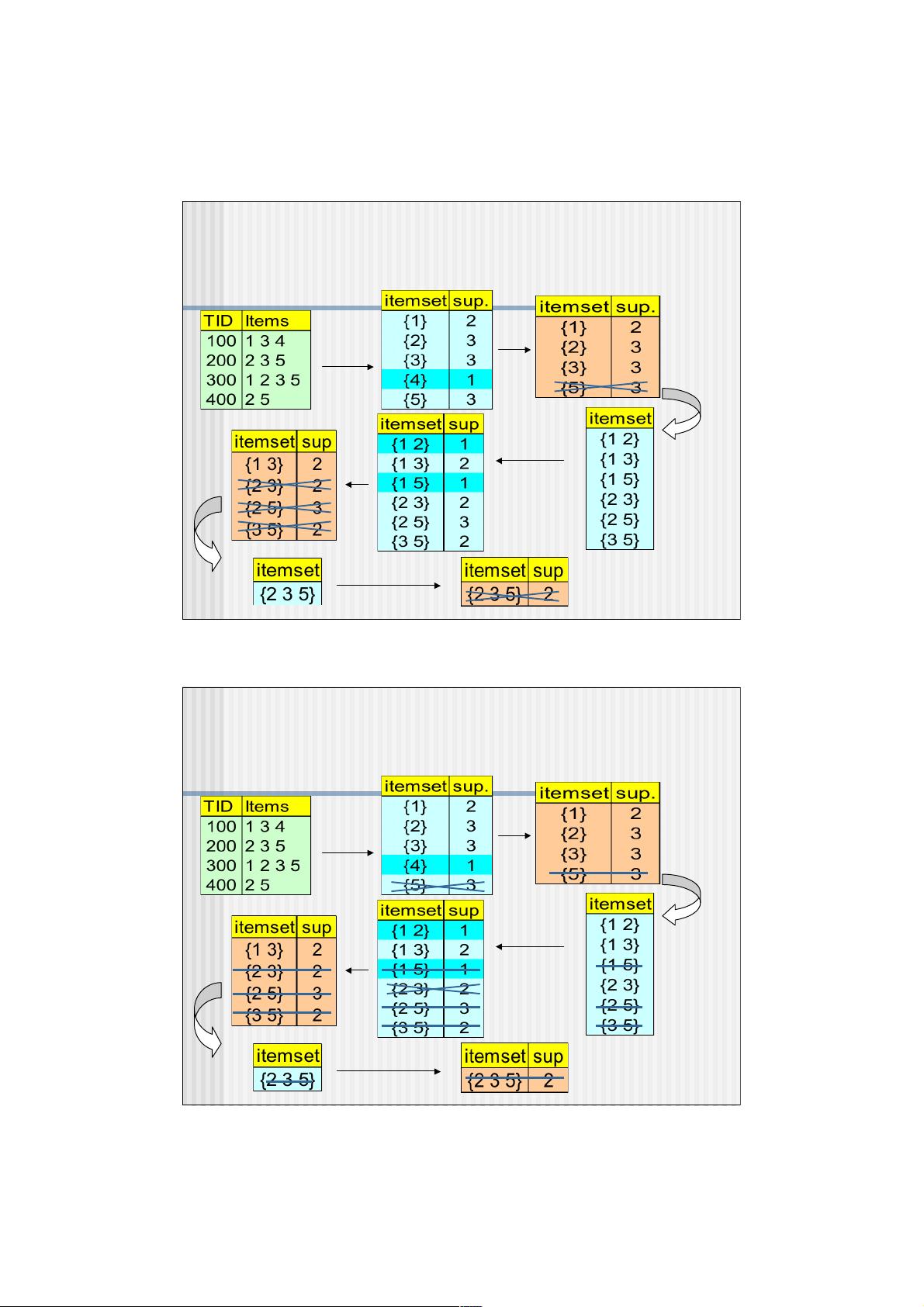
Apriori算法的一个例子是使用数据库D进行多次扫描,以发现频繁项集。当添加约束条件(如价格总和小于5)后,可以实现所谓的“Push an Anti-monotone Constraint”,这有助于提前剔除不符合条件的项集,从而在深度数据库中进行更高效的挖掘。
FP-Tree算法通过其特有的数据结构和挖掘策略,有效解决了频繁模式挖掘中的问题,提高了数据挖掘的效率。对于初学者而言,理解和掌握FP-Tree算法将有助于深入理解数据挖掘领域的核心技术。
5
Apriori + Constraint
Database D
Scan D
C
1
L
1
L
2
C
2
C
2
Scan D
C
3
L
3
Scan D
Constraint:
Sum{S.price} < 5
Push an Anti-monotone Constraint
Deep
Database D
Scan D
C
1
L
1
L
2
C
2
C
2
Scan D
C
3
L
3
Scan D
Constraint:
Sum{S.price} < 5
剩余20页未读,继续阅读
2011-09-15 上传
2022-09-14 上传
点击了解资源详情
点击了解资源详情
2023-04-20 上传
2023-04-05 上传
2021-05-22 上传









