低秩矩阵分解概率模型综述
76 浏览量
更新于2024-07-15
收藏 589KB PDF 举报
"这篇论文是关于低秩矩阵分解概率模型的研究,主要探讨了低秩矩阵分解的方法,如PCA、SVD和NMF,以及近年来出现的各种概率模型。这些模型将低秩分量视为随机变量,利用概率分布和贝叶斯推断来处理噪声污染的数据。文章介绍了概率分布和共轭先验在简化推理过程中的应用,同时概述了吉布斯采样和变分贝叶斯推理这两种主要的推断方法。此外,论文还按照不同的矩阵分解公式,如PCA、矩阵分解、鲁棒PCA、NMF和张量分解,将概率低秩矩阵分解模型进行了分类和回顾。最后,作者提出了未来研究方向的讨论。"
在低秩矩阵分解中,主成分分析(PCA)、奇异值分解(SVD)和非负矩阵分解(NMF)是最常见的技术,用于获取数据矩阵的低秩近似。传统的这些方法通常假设数据受到随机噪声的干扰,因此可以利用最大似然(ML)或最大后验(MAP)估计来求解低秩成分。然而,近年来的低秩矩阵分解概率模型引入了一个新的视角,即把低秩分量视为随机变量,这样可以更好地处理不确定性并建模噪声。
在概率模型中,选择适当的概率分布至关重要。这篇论文中,作者讨论了常用的概率分布,并提及了共轭先验,它们能够简化贝叶斯推断过程,使得参数估计更加高效。贝叶斯推断的两种主要方法——吉布斯采样和变分贝叶斯推理——在处理复杂概率模型时特别有用。吉布斯采样是一种马尔科夫链蒙特卡洛方法,用于生成概率模型的样本;而变分贝叶斯推理则通过优化变分分布来近似后验概率,它在处理高维问题时更为有效。
接着,作者根据不同的矩阵分解公式,比如PCA、矩阵分解、鲁棒PCA、NMF和张量分解,将概率低秩矩阵分解模型进行分类。这些模型各有特色,适用于不同的应用场景,例如,鲁棒PCA能够抵抗异常值,NMF则假设非负性约束,增加了模型的解释性。
论文最后部分,作者讨论了未来的研究挑战和可能的方向,这可能包括更复杂的噪声模型、更有效的推断算法,以及将这些概率模型应用于新的领域,如机器学习、图像处理和大数据分析等。这样的研究对于提升矩阵分解的性能和应用范围具有重要意义。
Entropy 2017, 19, 424 6 of 33
Entropy 2017, 19, 424 6 of 32
IG( , )
μ
λ
2
1
=,=,=
2
−abp
λ
λ
μ
=2 , 0, =→ab p
β
α
1=
=
α
β
λ
Beta( , )ab
U(0,1)
1, 1==ab
St( , , )
μ
λν
1
(, )
−
μ
λ
→+∞
ν
GIG( , , )pab
~Gam( , )x
α
β
~Exp( )x
λ
1
1
~IGam( , )
x
α
β
−
1
IGam( , )
−
p
b
0→a
1
~Lap(0, )x
λ
−
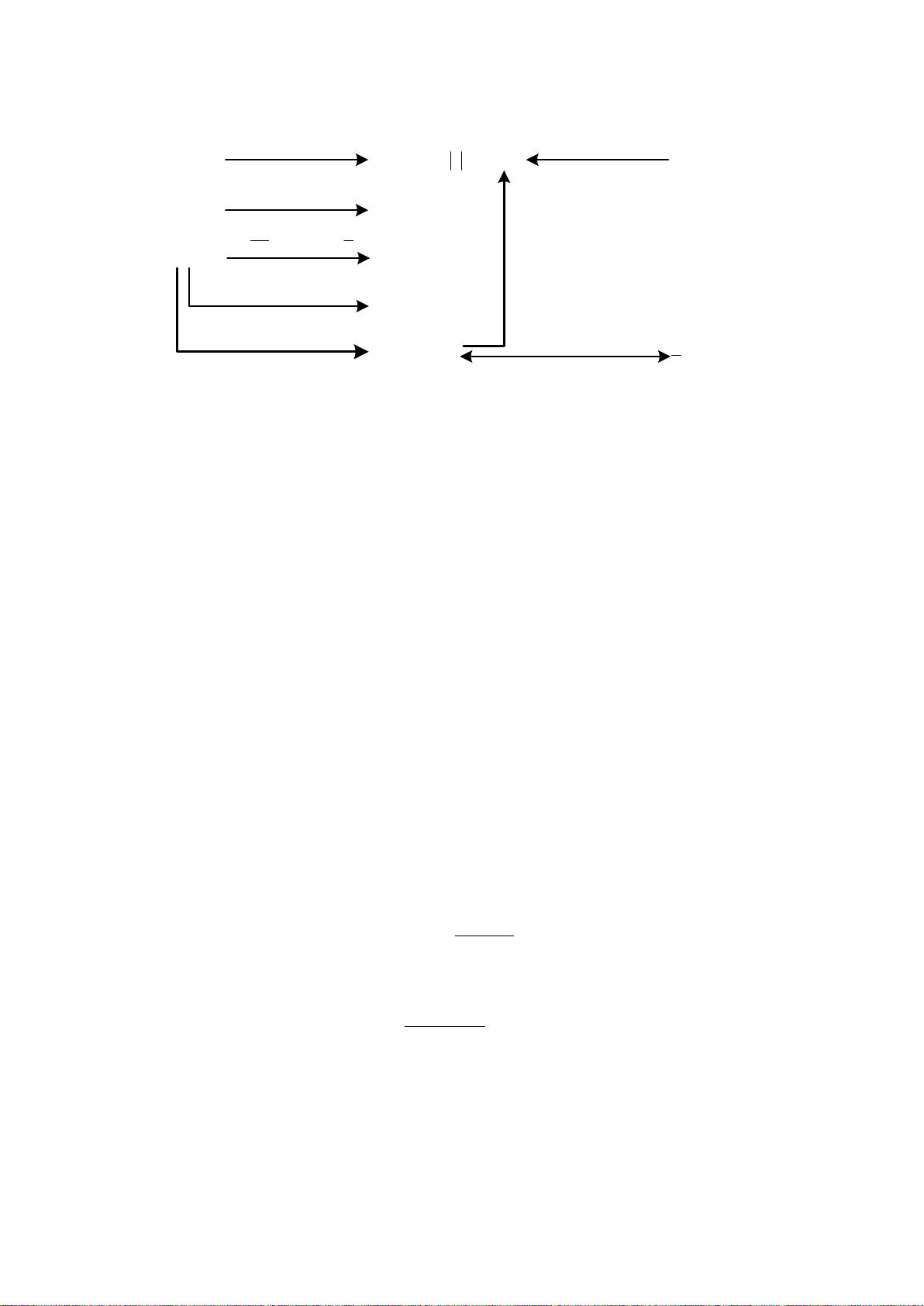
Figure 1. Relationships among several probability distributions.
2.2. Conjugate Priors
Let
x be a random vector with the parameter vector z and
{
}
12
, ,...,
N
X = xx x a collection of N
observed samples. In the presence of latent variables, they are also absorbed into
z . For given z , the
conditional probability density/mass function of
x is denoted by (|)p xz. Thus, we can construct
the likelihood function:
1
(| ) ( |) ( |).
N
i
i
LXpX p
=
==
∏
zzxz
(6)
As for variational Bayesian methods, the parameter vector
z is usually assumed to be
stochastic. Here, the prior distribution of
z is expressed as ()p z .
To simplify Bayesian analysis, we hope that the posterior distribution
(| )pXz is in the same
functional form as the prior ()p z . Under this circumstance, the prior and the posterior are called
conjugate distributions and the prior is also called a conjugate prior for the likelihood function
(| )LXz
[54,66]. In the following, we provide three most commonly-used examples of conjugate priors.
Example 3. Assume that random variable x obeys the Bernoulli distribution with parameter
μ
. We have
the likelihood function for
x
:
11
1
11
(|) Bern( |) (1 ) (1 )
NN
ii
iii i
NN
xNx
xx
i
ii
LX x
μμμμμμ
==
−
−
==
==−=−
∏∏
(7)
where the observations
{0,1}
i
x ∈ . In consideration of the form of (|)LX
μ
, we stipulate the prior
distribution of
μ
as the Beta distribution with parameters
a
and
b
:
11
()
() Beta(|,) (1 ) .
()()
ab
ab
pab
ab
μμ μμ
−−
Γ+
== −
ΓΓ
(8)
At this moment, we get the posterior distribution of
μ
via the Bayes’ rule:
()(|)
(|) ()(|).
()
ppX
pX ppX
pX
μμ
μμμ
=∝
(9)
Because
()
1
1
11
11
11
()( |) ()(| )
(1 ) 1
(1 )
N
N
i
i
i
i
NN
ii
ii
Nx
x
ab
ax bNx
ppX pL X
μμμμ
μμμ μ
μμ
=
=
==
−
−−
+− +−−
=
∝− −
∝−
(10)
Figure 1. Relationships among several probability distributions.
2.2. Conjugate Priors
Let
x
be a random vector with the parameter vector
z
and
X =
{
x
1
, x
2
, . . . , x
N
}
a collection of
N observed samples. In the presence of latent variables, they are also absorbed into
z
. For given
z
,
the conditional probability density/mass function of
x
is denoted by
p(x|z)
. Thus, we can construct
the likelihood function:
L(z|X) = p(X|z) =
N
∏
i=1
p(x
i
|z). (6)
As for variational Bayesian methods, the parameter vector
z
is usually assumed to be stochastic.
Here, the prior distribution of z is expressed as p(z).
To simplify Bayesian analysis, we hope that the posterior distribution
p(z|X)
is in the same
functional form as the prior
p(z)
. Under this circumstance, the prior and the posterior are called
conjugate distributions and the prior is also called a conjugate prior for the likelihood function
L(z|X)
[
54
,
66
]. In the following, we provide three most commonly-used examples of conjugate priors.
Example 3.
Assume that random variable
x
obeys the Bernoulli distribution with parameter
µ
. We have the
likelihood function for x:
L(µ|X) =
N
∏
i=1
Bern(x
i
|µ) =
N
∏
i=1
µ
x
i
(1 −µ)
1−x
i
= µ
∑
N
i=1
x
i
(1 −µ)
N−
∑
N
i=1
x
i
(7)
where the observations
x
i
∈
{
0, 1
}
. In consideration of the form of
L(µ|X)
, we stipulate the prior distribution
of µ as the Beta distribution with parameters a and b:
p(µ) = Beta(µ|a, b) =
Γ(a + b)
Γ(a)Γ(b)
µ
a−1
(1 −µ)
b−1
. (8)
At this moment, we get the posterior distribution of µ via the Bayes’ rule:
p(µ|X) =
p(µ)p(X|µ)
p(X)
∝ p(µ)p(X|µ). (9)
Because
p(µ)p(X|µ) = p(µ)L(µ|X)
∝ µ
a−1
(1 −µ)
b−1
µ
∑
N
i=1
x
i
(
1 − µ
)
N−
∑
N
i=1
x
i
∝ µ
a+
∑
N
i=1
x
i
−1
(1 −µ)
b+N−
∑
N
i=1
x
i
−1
(10)

剩余32页未读,继续阅读
2023-02-23 上传
2023-07-27 上传
2023-05-16 上传
2023-06-11 上传
2023-05-16 上传
2023-06-11 上传
2023-08-26 上传
2023-05-09 上传

weixin_38729108
- 粉丝: 5
- 资源: 896
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
