词嵌入详解:自然语言处理中的低维语义表示
版权申诉
108 浏览量
更新于2024-07-19
收藏 1.39MB DOCX 举报
"自然语言处理中的词嵌入技术是一个关键的研究领域,主要目的是将词语转换为低维且密集的向量表示,以便于神经网络理解和处理。本文回顾了词嵌入的基本概念,独热编码的局限性,以及经典的词嵌入方法,包括神经网络语言模型(NNLM)、RNNLM、Word2vec的skip-gram和CBOW模型。"
在自然语言处理(NLP)中,词嵌入是将词汇转换为数值向量的过程,这些向量能够捕捉到词汇的语义和语法特性。这种方法解决了深度学习模型处理文本数据时面临的挑战,即原始的文本数据难以直接输入到神经网络中。词嵌入通常具有较低的维度,相比原始的独热编码方式,它们不仅减少了计算成本,还能有效地捕获词汇之间的关系。
独热编码是最简单的词表示方式,每个词被表示为一个全零向量,仅在对应词的位置设置为1。然而,随着词汇表大小的增加,独热编码会导致高维且稀疏的向量,不利于神经网络的学习,并且不包含语义信息。因此,词嵌入的出现是为了解决这些问题,提供一种更有效、富含语义信息的表示方式。
NNLM(神经网络语言模型)是早期的词嵌入方法,它利用马尔可夫链假设来预测句子中下一个词的概率。模型通过前n-1个词的one-hot编码与查找矩阵相乘得到词嵌入,再将这些嵌入输入到softmax层预测目标词。尽管NNLM主要是为语言建模设计,但它在训练过程中产生了词嵌入,为后续研究奠定了基础。
Word2vec是后来发展起来的著名词嵌入工具,其主要改进在于利用上下文信息来预测目标词,有两种主要模型:skip-gram和CBOW。skip-gram从目标词出发预测上下文词,而CBOW则是反过来,从上下文词预测目标词。这两个模型都通过大规模数据学习词嵌入,提高了预测效率和向量的质量。
这些经典的词嵌入方法极大地推动了NLP领域的进展,为情感分析、机器翻译、问答系统等应用提供了强大的预处理手段。词嵌入的不断发展和完善,如GloVe、FastText等模型,进一步提升了对自然语言的理解和处理能力。
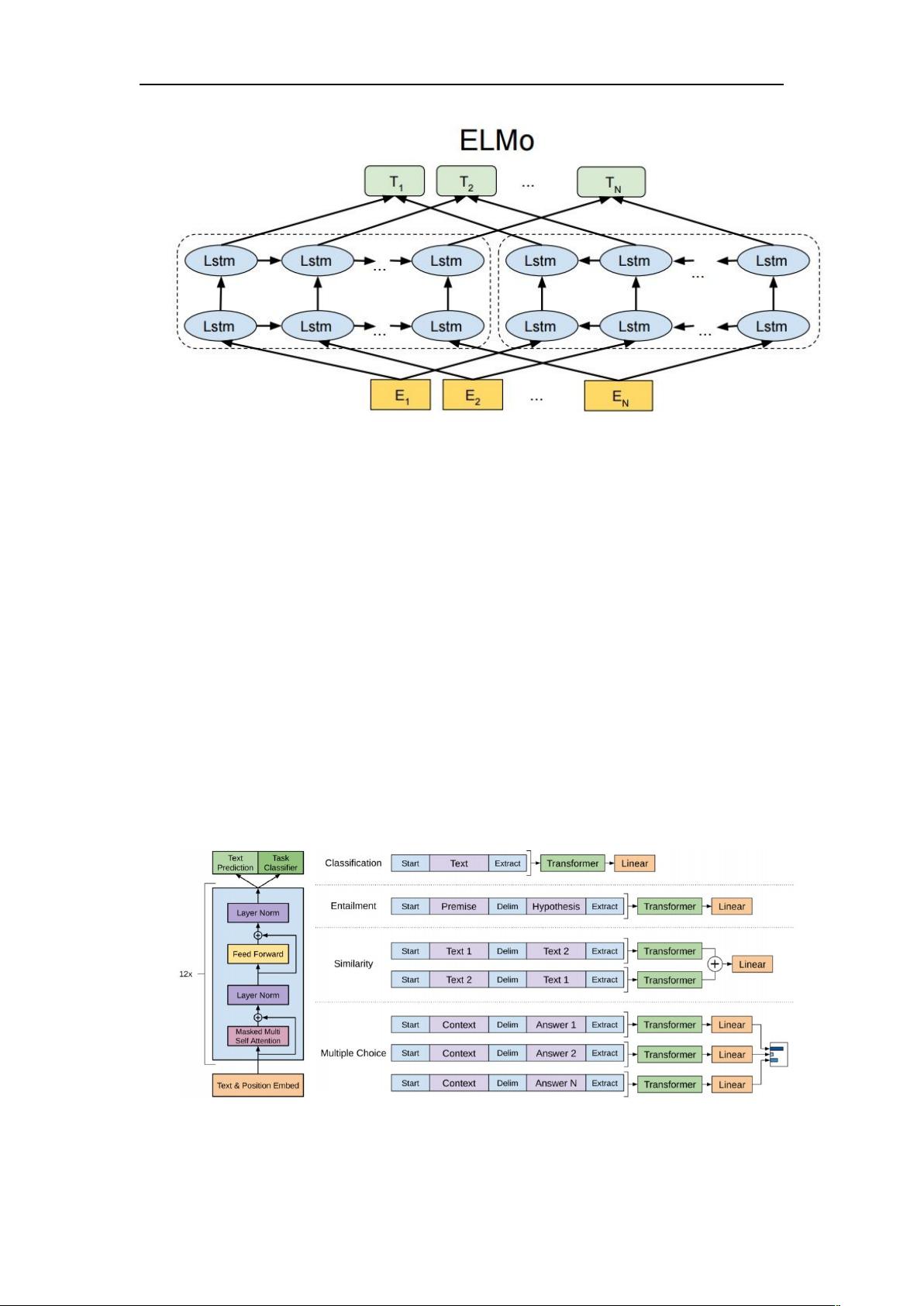
图 ':-& 架构的特征提取层
R
k
∧¿
{
x
k
LM
,
h
k, j
LM
,
´
h
k , j
LM
∣ j=1 , …, L
}
¿=
{
h
k , j
LM
∣ j=0,… , L
}
(
5
)
ELMo
k
task
=E
(
R
k
;Θ
task
)
=γ
task
∑
j=0
L
❑s
j
task
h
k , j
LM
(
6
)
-& 中的特征 提 取层是使用 一个双向 01 来实现的 ,但后来在 实践中发现 ,
结构有着更强的提取特征的能力,因此有人受到 3# 思想的启发,
提出了更强的 451(4#!$##)模型
2
。其具体结构如图 ( 所示,左端
是一个基于 的特征抽取器,在训练完成之后在其原始结构上进行改进以适合
不同的下游任务,最后对参数进行 3#;右端给出了一些实例,如何根据不同的
下游任务如分类和相似性评估对原始模型的结构和输入输出进行修正。
图 (:451 模型结构
鉴于 451 模型的输入只包含了目标词的上文,为了更广泛地利用上下文信息,研究人
剩余18页未读,继续阅读
2022-11-02 上传
2021-12-06 上传
2021-09-20 上传
2022-11-02 上传
2023-02-23 上传
2022-05-14 上传

羊城迷鹿
- 粉丝: 1185
- 资源: 388
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
