Hive:Facebook开源的数据仓库工具详解
Hive技术调研深入探讨了Facebook在2008年开源的Apache Hive项目,这是一个专为大数据处理设计的数据仓库工具,旨在简化在Hadoop生态系统中进行结构化数据管理。Hive的核心价值在于其将复杂的Hadoop MapReduce编程模型封装成了类SQL的接口,降低了数据分析师和业务用户的学习曲线。
1. **Hive基本概念**
- Hive是Hadoop生态系统的基石,作为数据仓库工具,它将数据文件组织成数据库表的形式,允许用户使用标准SQL查询进行操作。这种设计使得非技术人员也能方便地进行数据处理和分析,无需深入了解底层的MapReduce编程。
- Hive的架构包括用户接口(如HiveShell、Web接口、JDBC/ODBC客户端),Thrift服务器用于客户端连接,元数据存储(如MySQL或Derby),解析器负责SQL查询的语法分析、编译和优化,以及查询计划生成,而Hadoop则作为底层计算引擎,负责处理MapReduce任务。
2. **Hive任务流程**
- Hive的工作流程涉及用户输入SQL查询,解析器将查询转化为可执行的MapReduce计划。这个过程包括解析阶段、编译阶段、优化阶段和计划生成。生成的计划被保存在HDFS中,分为持久版本和缓存版本,后者在任务完成后会被清除。
- 每个查询计划由根任务和子任务组成,可能包含多个MapReduce任务和非MapReduce任务,这些任务按照计划中的逻辑顺序执行,最终汇总结果。例如,一个查询可能首先进行数据读取、数据预处理、聚合计算,然后将结果写回存储。
Hive的优势在于它提供了高度抽象的SQL接口,使得数据分析人员能够高效地进行数据查询和报表生成,同时利用Hadoop的分布式计算能力处理大规模数据。然而,它的局限性在于对于复杂查询的性能可能不如直接使用MapReduce,因为SQL解析和优化过程可能会引入额外的开销。因此,Hive常用于数据仓库场景,而对实时数据处理或高性能查询的需求,则可能需要考虑更优化的解决方案,如Spark SQL或Tez等。
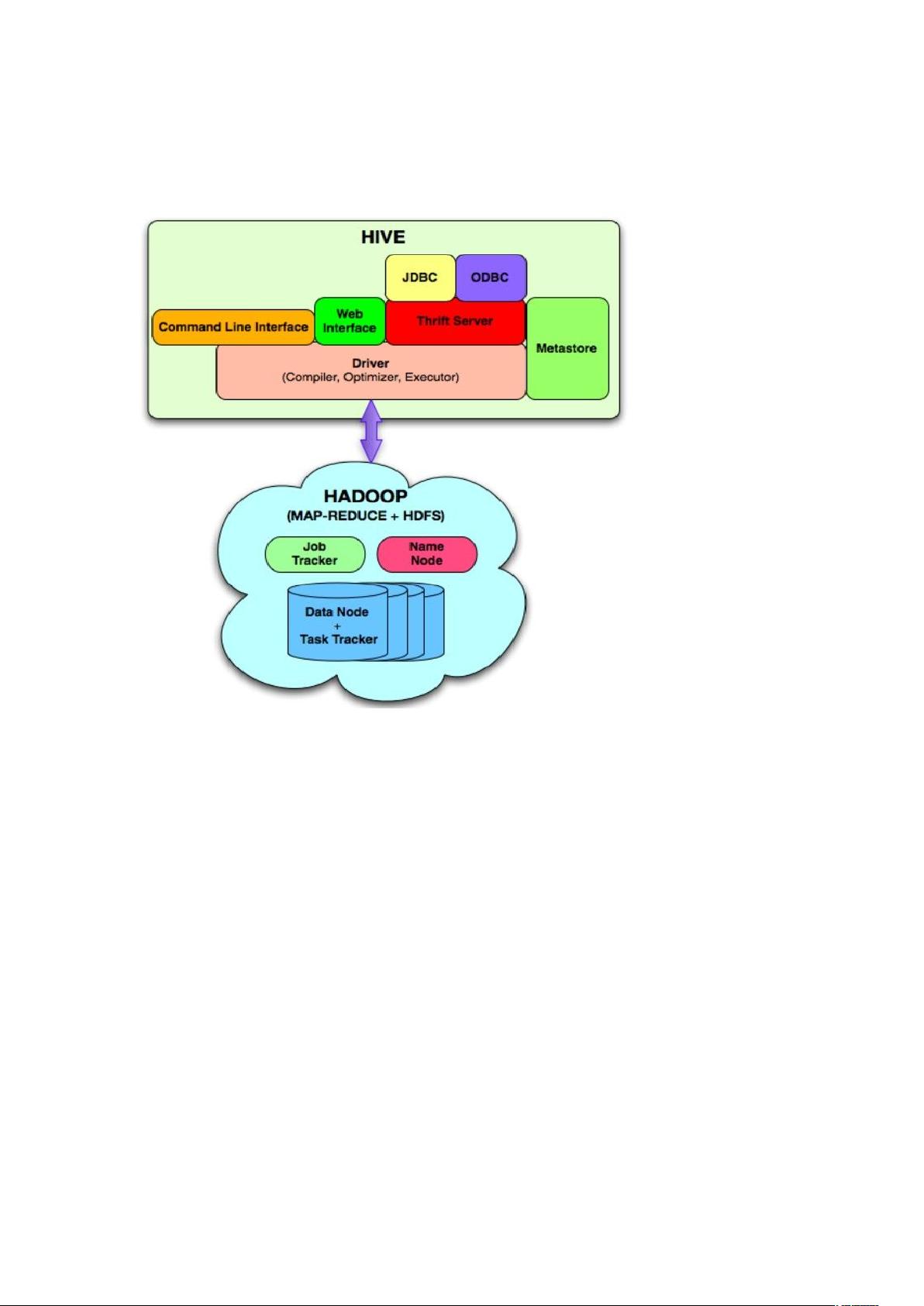
1.2.Hive 基本架构
Hive 包括如下相关组件:
1、用户接口
包括 Hive shell,Web 接口,JDBC 客户端,ODBC 客户端。
2、Thri 服务器
当 Hive 以服务器模式运行时,可以作为 Thri$ 服务器,供客户端连接。
3、元数据
通常存储在关系数据库如 Mysql、Derby 中。
剩余14页未读,继续阅读
2022-03-29 上传
2021-03-03 上传
2022-09-26 上传
2023-05-26 上传
2023-05-25 上传
2023-05-25 上传
2023-02-07 上传
2024-07-10 上传
2023-06-28 上传

zx4866123
- 粉丝: 1
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
