MPMFFT集成模型:提升人脸表情识别精度的数据挖掘方法
46 浏览量
更新于2024-06-17
收藏 2MB PDF 举报
"这篇学术论文发表在沙特国王大学学报,主要探讨了基于MPMFFT(Multiple Pattern Multiple Features based Feature Transformation)的人脸表情分类技术。MPMFFT是一种数据挖掘模型,用于提取和转化人脸信息,以提高表情识别的准确性。模型通过捕捉面部纹理、几何、数学和结构特征,构建了包含132个特征的数据集。在这个过程中,使用了DCA(Dendritic Cell Algorithm)来选择具有区分性的特征,并通过DBT(Dempster Belief Theory)进行特征权重分配。最终,结合贝叶斯网络进行概率处理,以实现更精确的表情分类。实验在JAFFE、CMU和CK数据集上进行,与决策树、SVM和KNN等传统方法进行了比较,结果显示MPMFFT模型提升了不同表情的识别精度。"
文章的背景指出,面部表情是人类情感、意图和反应的重要视觉表现,被广泛应用于生物识别系统中。研究的目标是开发一种高效的数据挖掘模型,能够准确地识别人脸表情,尤其在无意识或不便直接交流的场景下,如课堂监控或病人护理。
MPMFFT模型的核心在于其特征提取和转换过程。它不仅关注整个面部区域,还聚焦于特定的表情敏感区域,通过三个局部区域提取模型获取特征。然后,DCA用于生成特征模式,挑选出有助于区分表情的安全和危险特征。接着,DBT对这些特征进行加权,根据它们与特定表情类别的关联性。最后,经过贝叶斯网络的处理,利用概率模型实现更精确的分类。
实验部分,该模型在三个标准人脸表情数据库上验证了性能,即JAFFE、CMU和CK数据集。通过与决策树、支持向量机(SVM)和K近邻(KNN)等机器学习方法的比较,MPMFFT模型在表情识别的准确性上表现出优势,证实了其在人脸识别领域的有效性和创新性。
这篇论文提供了一种基于MPMFFT的集成概率模型,用于提升人脸表情分类的效率和准确度,对于理解和开发表情识别技术具有重要价值。
K. Juneja
/
Journal of King Saud University
621
死亡信号和安全信号这种危险理论直接负责这些生成的信号的分类。对
于分析,使用树突细胞(DC)( Singh等人,2013; Kumari等人,
2012 a,b)被形成为应用信号样本的特性、其行为和环境。利用具有
后约束的碰撞观测值识别异常信号约束。基于距离度量的分析在这里被
应用于对警报或危险信号进行分类。在了解基于应用的实现之前,必须
了解这些细胞如何在人体中起作用以保护免受危险信号的影响。
人体器官是以细胞因子为通讯通道的组织细胞的集合。这种化学形
式也会根据其表征影响组织。化学品的完整效果也取决于周围的液体。
每种细胞还通过其评估状态和细胞死亡类型来描述,这影响程序化细胞
因子表征。存在于细胞核中的物质是碎片化的,并以秘密细胞的形式控
制消化酶。细胞内部的物质维持细胞的完整性和生命。这种整体活动和
环境影响可能对免疫系统有害。细胞理论即将识别这些综合的危险约束
和安全约束,从而可以应用预防措施。树突状细胞(DC)是白细胞,
在组织中充当巨噬细胞并充当抗原的转运体。根据作用和行为,抗原以
三种形式存在。未成熟DC是实际上从周围流体收集碎片和约束的初始
成熟状态。它作为一个复杂的分子和抗原受体。细胞形式中的不同信号
组合可导致细胞的部分或完全成熟
如果T细胞周围的细胞因子没有被激活,那么抗原和表达增加。如果
这种DC暴露于多个信号,则其被转换为成熟DC。进行细胞调节剂和反
应评价以获得成熟DC。如果环境条件不同并且不能产生足够的抗原并
且不能以均匀的方式提供与细胞因子的整合,则细胞转化为半成熟
DC。半成熟DC的影响是抑制性的,而成熟DC的影响是激活的。
现在,由于体内会产生一些信号,因此将其分类为
PAMP(P)、
安全信号(S)或危险信号(D)。 不同的权重向量
、互连约束和小区
通信共同识别信号类型并进行相对分类。成熟的细胞通常与危险信号
有关,
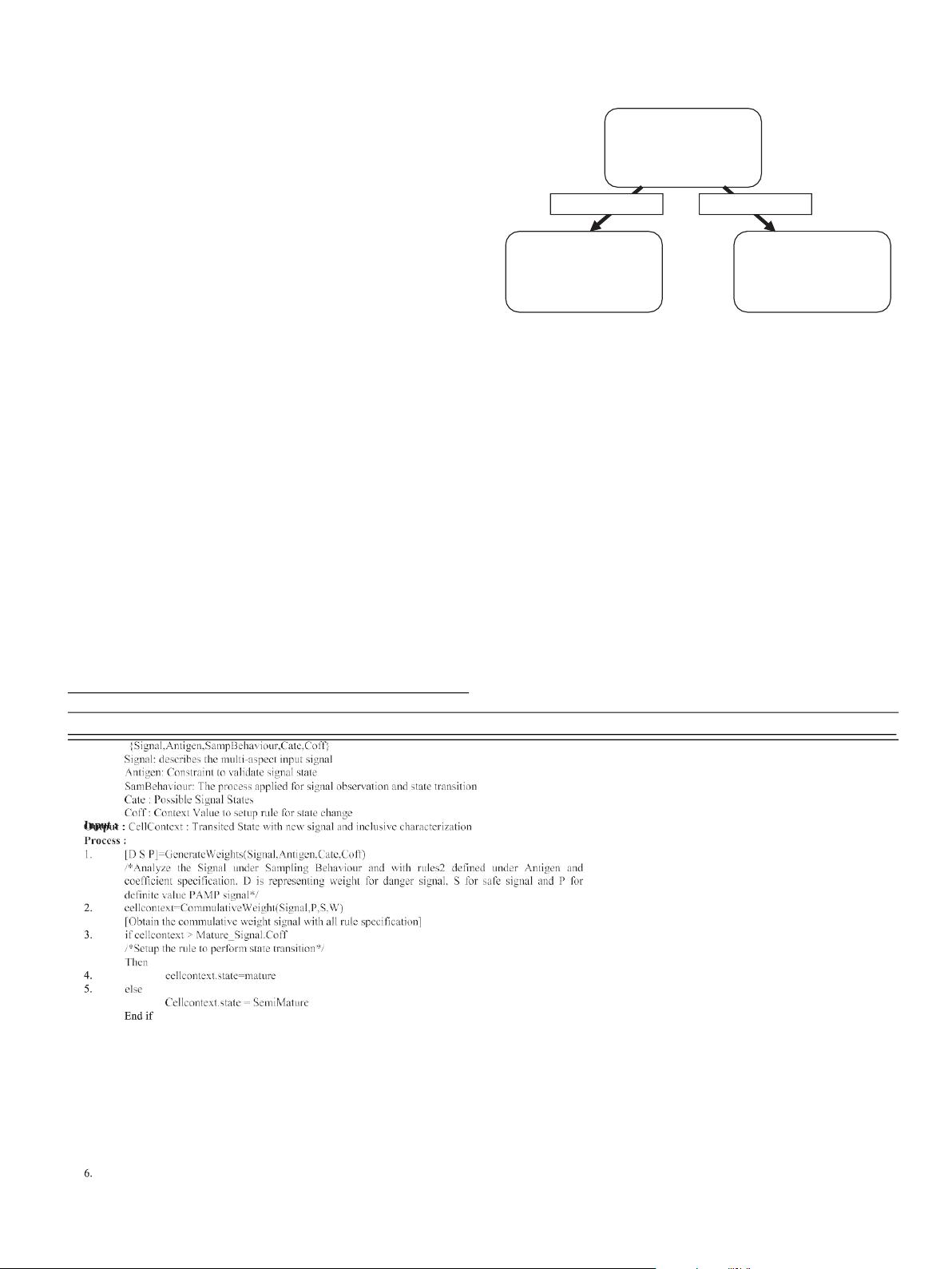
未成熟状态
输入信号::
::对照抗原::
::Chararacliteral
半未成熟状态
::抗原耐受性::
::过渡行为::
::成本评估::
::耐受电导率::
成熟状态
::抗原耐受性::
::过渡行为::
::成本评估::
::无功电导::
危险信号
安全型信号
图
1.
一、
DCA
的抽象过程模型
半成熟细胞整合有安全信号。本文以图像特征的数值信息为约束条
件,对安全与危险信号形式进行识别。本文应用属性协调来决定细胞
的世代,确定成熟和半成熟的细胞形态,最后识别危险和安全信号形
态。
该DCA算法的算法公式与复杂的免疫学行为相结合。每个工作阶段
都以受控的方式进行处理,其特性规范包括信号结构规范、信号表征、
处理和分类。条件解释和评估是基于数据集,所需的分类和潜在的类映
射。DCA工艺的加工性能如图所示。1 .一、
训练数据的早期推导被认为处于不成熟状态。这种状态具有输入信
号、基于规则的抗原和特定的行为问题。这种未成熟状态过渡到半成熟
或成熟状态。规则被应用于识别被转换的状态。输入信号中安全信号和
危险信号的包容性决定了转换过程。基于上下文的抗原过程与模式观察
被应用于该信号内容验证。对信号进行了怀疑-信念规则处理,实现了对
合成状态的识别.通过状态识别,还可以在抗原存在性、耐受性或反应性
工作行为以及成本评估方面获得其表征。算法1以广义形式描述DCA的
过程方面。
算法
1
:
DCA
的处理行为
剩余15页未读,继续阅读
2024-06-11 上传
2023-11-18 上传
2023-05-31 上传
2023-06-26 上传
2023-02-16 上传
2023-03-27 上传
2023-07-13 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
