PostgreSQL递归查询实战:优化大型调查应用
"本文主要介绍了如何在PostgreSQL数据库中实现递归查询,特别是在处理层级数据如调查中的问题和分类时的应用。文章通过一个调查应用的例子,展示了如何利用递归查询优化深度优先遍历大型数据结构的性能问题。"
在数据库查询中,递归查询是一种非常有用的技术,尤其在处理具有层级关系的数据时。例如,在上述描述的调查应用中,问题和分类形成了一个树形结构,每个问题或分类可能有自己的顺序,并且可以有子问题或子分类。这种情况下,传统的深度优先遍历方法(如使用JOIN和嵌套循环)可能会在面对大量数据和深层结构时变得低效。
PostgreSQL 8.4版本开始引入了Common Table Expressions (CTE) 的递归功能,使得在SQL中实现递归查询成为可能。在CTE中,递归部分由两部分组成:基础查询(非递归部分)和递归查询。
1. **非递归部分**:这是递归查询的起点,定义了初始的行集。在调查应用的例子中,这包括没有父分类(category_id为空)的问题,即根节点。基础查询的SQL语句可能如下:
```sql
WITH RECURSIVE survey_tree AS (
SELECT id, content, order_number, 'question' AS type, category_id
FROM questions
WHERE survey_id = 2 AND category_id IS NULL
)
```
2. **递归部分**:定义了如何基于当前的行集生成新的行。在调查应用中,递归部分将获取每个问题或分类的子问题或子分类,直到遍历完所有相关记录。递归查询可能如下:
```sql
UNION ALL
SELECT child.id, child.content, child.order_number, 'question' AS type, child.category_id
FROM questions AS child
JOIN survey_tree AS parent ON child.category_id = parent.id
WHERE child.survey_id = 2
```
结合这两部分,`WITH RECURSIVE`查询将返回一个完整的问题和分类树,按照它们的`order_number`字段排序。这种方法不仅能够有效地处理大规模的层级数据,而且可以根据需求进行定制,比如添加过滤条件或者排序方式。
递归查询的优点在于它能够简化处理层级数据的逻辑,避免了多次JOIN操作,从而提高了查询性能。然而,需要注意的是,递归查询可能会消耗大量内存,如果层级太深或者数据量过大,可能导致栈溢出。因此,在实际使用中,需要合理限制递归深度,并对数据结构进行优化,比如设置合理的索引,以确保查询效率。
总结来说,PostgreSQL的递归查询功能为处理层级数据提供了一种强大的工具,尤其是在需要遍历整个树形结构或深度优先遍历时。通过理解如何构建和优化递归CTE,开发者可以更高效地处理复杂的数据库查询场景。
在在PostgreSQL中实现递归查询的教程中实现递归查询的教程
主要介绍了在PostgreSQL中实现递归查询的教程,包括在递归查询内排序等方法的介绍,需要的朋友可以参考下
介绍介绍
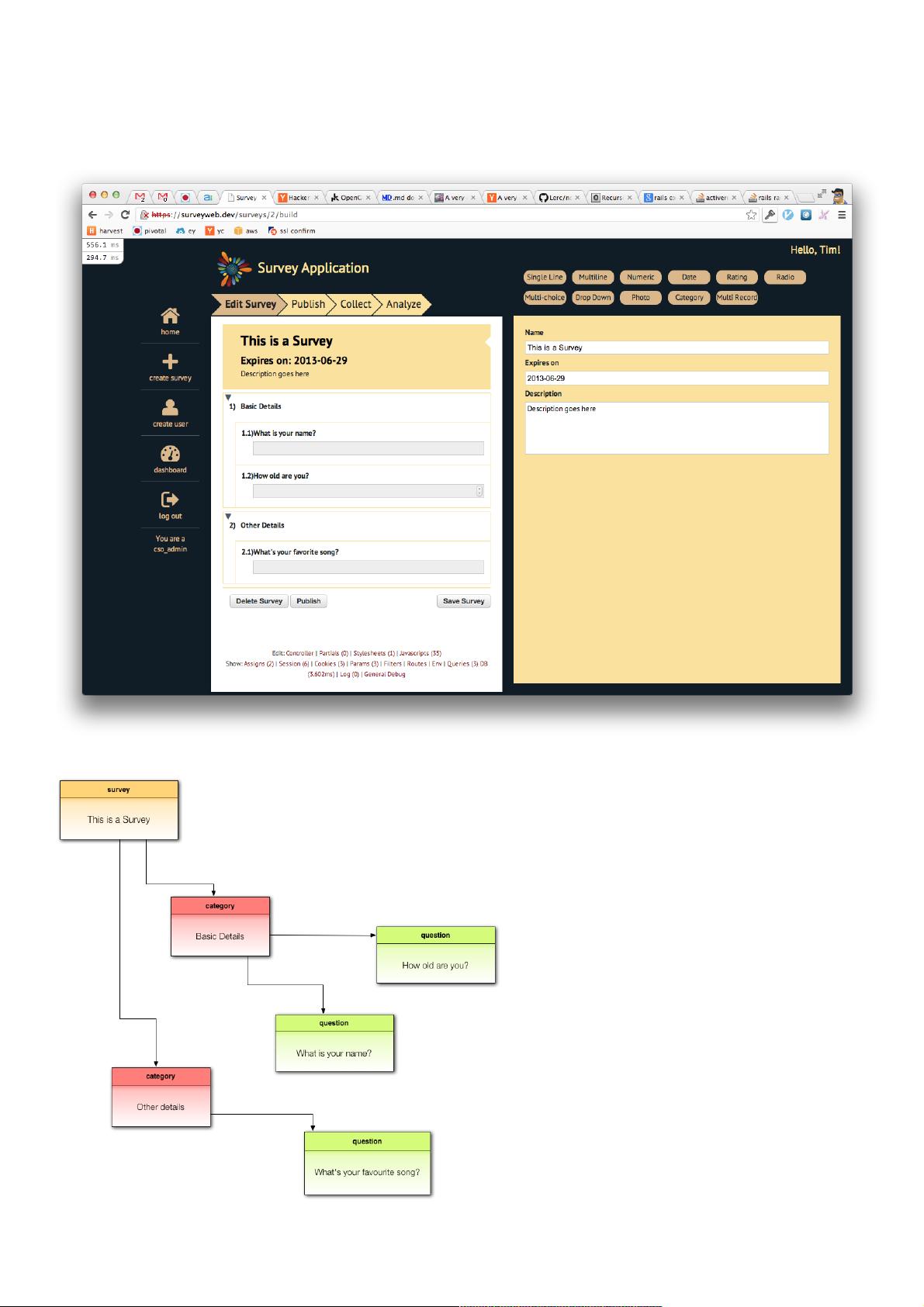
在Nilenso,哥在搞一个 (开源的哦!)用来设计和发起调查的应用。
下面这个是一个调查的例子:
在内部,它是这样表示滴:
一个调查包括了许多问题(question)。一系列问题可以归到(可选)一个分类(category)中。我们实际的数据结构会复杂一点(特别是子问题sub-question部分),但先当它就只有question跟
category吧。
下载后可阅读完整内容,剩余4页未读,立即下载

weixin_38609401
- 粉丝: 5
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- VC动态链接库实例打包下载
- vim官方使用手册--详细,实例
- 嵌入式试验开发环境搭建全攻略.pdf
- Makefile 手册
- 学生选课系统毕业论文
- 嵌入式系统教材(系统设计方法)
- JavaFX Script 编程语言中文教程
- 2FSK调制与解调电路
- word实用技巧让您工作效率提高
- 八路数显抢答器的设计
- 卓有成效的程序员 productive_programmer_minibook_infoq
- 领域驱动设计 quickly-chinese-version
- PureMVC最佳实现
- Thinking In Java (第三版) 中文版
- jsp验证码学习代码
- struts2学习 starting-struts2-chinese
