深度学习进阶:过拟合、欠拟合与解决策略
7 浏览量
更新于2024-08-29
1
收藏 324KB PDF 举报
本篇文章主要探讨深度学习任务中的核心概念,包括过拟合、欠拟合,以及与之相关的梯度消失和梯度爆炸问题。在深度学习模型训练过程中,理解并解决这些问题至关重要。
首先,文章介绍了训练误差(training error)和泛化误差(generalization error)的概念。训练误差是模型在训练数据集上的表现,而泛化误差则是模型对未知数据的预测能力,通常通过测试集误差来近似。为了准确评估模型性能,不能仅依赖训练误差,因为这可能会导致过拟合或欠拟合。
模型选择是避免这两种问题的关键步骤。为了防止在测试阶段出现偏差,应当使用验证数据集(validation set),而不是测试数据集进行模型选择和参数调整。K折交叉验证作为一种解决方法,当数据集较小不足以预留验证集时,会将数据划分为多个子集,交替训练和验证,以更全面地评估模型性能。
过拟合和欠拟合是训练过程中常见的问题。欠拟合表现为模型在训练和测试数据上都表现不佳,可能是因为模型复杂度过低,无法捕捉数据的复杂性。而过拟合则表现为模型在训练数据上表现良好,但在测试数据上性能下滑,原因可能是模型过于复杂,过度适应了训练数据的噪声。
文章还提到,模型复杂度是影响过拟合和欠拟合的重要因素,当模型过于复杂时,容易发生过拟合。此外,数据集的大小也起着决定性作用,训练数据集过小,特别是小于模型参数数量时,过拟合的风险增大。因此,增加数据量和控制模型复杂度是优化模型性能的有效策略。
文章以多项式函数拟合为例,展示了如何使用PyTorch库进行实际操作,通过初始化模型参数,进行训练和验证,以理解和处理这些深度学习中的关键概念。在这个过程中,理解梯度下降、梯度消失和梯度爆炸的影响及应对措施也是必不可少的,它们与模型训练过程中的权重更新和优化算法密切相关。
总结来说,本文提供了深度学习中关键问题的理论框架,包括如何通过验证数据集和K折交叉验证来评估模型,以及如何通过调整模型复杂度和数据集大小来防止过拟合和欠拟合。同时,通过实例演示,帮助读者掌握了实际操作中如何处理这些挑战。
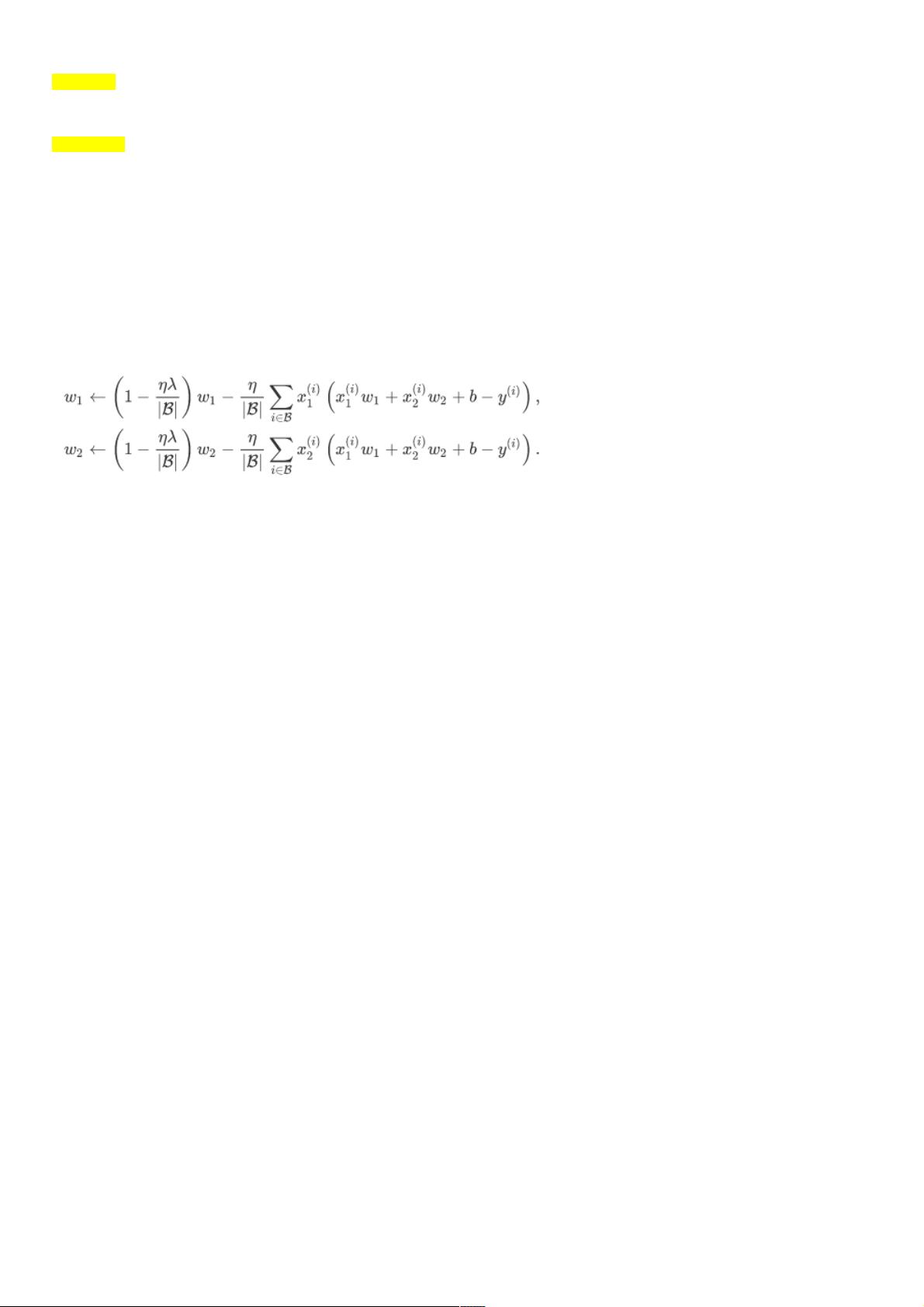
bias tensor([5.0013])
overfitting
fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :], labels[0:2], labels[n_train:])
underfitting
fit_and_plot(features[:n_train, :], features[n_train:, :], labels[:n_train], labels[n_train:])
解决过拟合问题的方法解决过拟合问题的方法
权重衰减权重衰减——L2范数正则化(范数正则化(regularization))
正则化是通过为损失函数添加惩罚项使学出的模型参数值较小
L2
范数正则化
在模型原损失函数的基础上添加L2范数惩罚项,从而得到训练所需要的最小化的函数。L2范数惩罚项是指
模型权重参数每个
元素的平方和与一个正的常数的乘积
在有了L2范数惩罚项之后,在小批量随机梯度下降中,线性回归中的权重的迭代方程变为:
可见,L2范数正则化令权重先自乘小于1的数,再减去不含惩罚项的梯度。因此L2范数正则化,又叫作权重衰减,权重衰减通
过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能会对过拟合有效
高维线性回归实验从零开始的实现
——L2范数正则化的应用
导入需要的
package
import torch
import numpy as np
import torch.nn as nn
import sys
import d2lzh as d2l
初始化模型参数
n_train, n_test, num_inputs = 20, 100, 200
true_w, true_b = torch.ones(num_inputs, 1) * 0.01, 0.05
features = torch.randn((n_train + n_test, num_inputs))
labels = torch.matmul(features, true_w) + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
train_features, test_features = features[:n_train, :], features[n_train:, :] train_labels, test_labels = labels[:n_train],
labels[n_train:]``
# 定义参数初始化函数,初始化模型参数并且附上梯度
def init_param():
w = torch.randn((num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
定义范数惩罚项
def l2_penalty(w):
return (w**2).sum()/2
定义训练和测试
batch_size, num_epochs, lr = 1, 100, 0.003
net, loss = d2l.linreg, d2l.squared_loss
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
def fit_and_plot(lambd):
w, b = init_params()
train_ls, test_ls = [], [] for _ in range(num_epochs):
for X, y in train_iter:
剩余10页未读,继续阅读
2021-01-07 上传
2021-01-20 上传
2021-01-07 上传
2021-12-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38646914
- 粉丝: 1
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
