LLM原理与ChatPDF实现详解
版权申诉
"LLM原理与ChatPDF实现.pdf"
这篇文档主要探讨了大模型的原理以及如何实现ChatPDF,特别提到了Transformer、BERT和GPT等模型,还对比了国产的大模型,如百度的文心一言和科大讯飞的星火。文档内容涵盖了从大模型的基础理论到具体应用的多个层面。
首先,大模型的原理部分介绍了Transformer架构,这是由Google在2017年提出的革命性模型,它通过自注意力机制解决了RNN和LSTM在处理长序列信息时的效率问题。BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer的一个重要模型,2018年发布后在NLP领域创造了多项记录。BERT的特点在于其双向的预训练策略,能同时理解单词的前后文信息,从而提供更丰富的语境理解。此外,BERT还使用了Masked Language Modeling(MLM)和Next Sentence Prediction(NSP)的任务进行预训练,增强模型对语言的理解能力。
接着,文档提到了国产大模型——百度的文心一言。文心一言在经过多次迭代后,其理解和回答能力有了显著提升,目前已经在多个领域得到了应用。而科大讯飞的星火也有类似的功能,并提供了相应的服务接口供开发者使用。
搭建ChatPDF的部分,讲解了Indexes的使用、Embedding原理以及ChatPDF的实现。Indexes是用于高效检索大模型输出的关键组件,Embedding则是将词汇转换为连续向量的过程,这对于模型理解语义至关重要。ChatPDF的实现可能结合了LangChain和ChatGLM等工具,这些工具通常用于构建对话系统,使得大模型可以进行自然、流畅的人机对话。
最后,文档中还列举了社会关系推理的问题,分别用百度文心一言、讯飞星火和ChatGPT进行了模拟回答,展示了大模型在理解复杂情境和人类情感方面的潜力。同时,BERT模型的简要介绍强调了它在深度学习、自然语言处理领域的应用,以及其在语音识别等领域的潜在价值。
这篇文档深入浅出地介绍了大模型的原理和实际应用,特别是围绕BERT模型展开的讨论,以及如何利用这些技术来构建ChatPDF这样的对话系统。对于想要了解大模型及其应用的人来说,是一份非常有价值的参考资料。
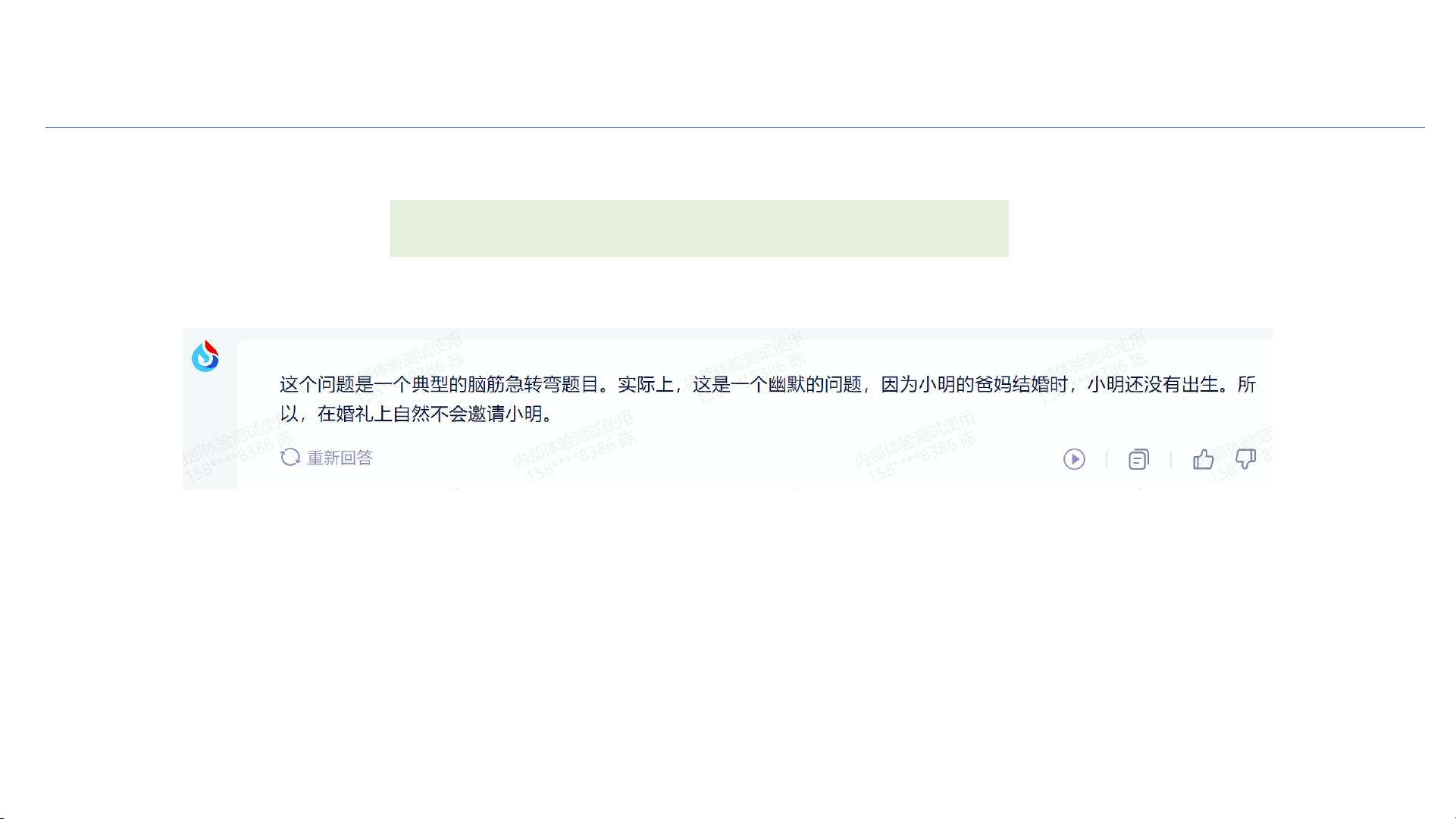
社会关系推理(讯飞星火)
小明的爸爸妈妈结婚,没有邀请小明,小明会生气么?

剩余42页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-10-27 上传
2024-07-18 上传
2023-12-06 上传

安全方案
- 粉丝: 2538
- 资源: 3960
 我的内容管理
展开
我的内容管理
展开







最新资源
- n2h2p-开源
- LilyNice.gk9potbknt.gadJ3Ld
- volar:手掌| 一页最小视差模板
- beap:Python中的beap(双亲堆)算法参考实现
- UCAB_IngSoftware:未知〜电厂管理项目
- 美赛:Matlib下层次分析法,多属性模型
- MCFI.zip_界面编程_C#_
- mini-projects-3
- opengl实现画图板VS2010项目
- EventPlanner
- C++套接字实现UDP通讯,客户端以及服务端demo
- keap:Keap是一种堆数据结构,具有稳定的PriorityQueue和稳定的Keapsort排序算法
- ClickLearn Chrome Connector-crx插件
- pands-problem-sheet
- shader-playground:着色器游乐场的乐趣
- mysql2pg-开源
