CD2-pFed: 联邦学习中的循环蒸馏引导通道个性化
需积分: 0 193 浏览量
更新于2024-08-03
收藏 1.53MB PDF 举报
在2022年的计算机视觉与模式识别(CVPR)会议上,一篇名为"CD2-pFed:联邦学习中模型个性化循环蒸馏引导通道解耦"的论文引起了广泛关注。该研究旨在解决联邦学习(Federated Learning,FL)中的一个重要挑战,即如何处理异质性数据客户端,因为数据分布的差异通常会限制全球模型在每个参与方上的泛化能力。
论文提出了一种创新的方法,即循环蒸馏指导的通道解耦(CyclicDistillation-guidedChannelDecoupling, CD2-pFed),以实现模型个性化。与之前主要依赖于层级个性化(即针对每个客户端进行单独调整的模型结构)的方法不同,CD2-pFed首次尝试通过通道级别的分配来实现模型个性化,也称为通道解耦。这种策略允许模型更好地适应各个客户端的数据特性,从而提高整体性能。
具体而言,CD2-pFed框架的工作原理是通过周期性的知识蒸馏(Knowledge Distillation,KD)过程,将全局模型的知识传递给本地模型,同时对模型的通道权重进行解耦处理。知识蒸馏在这里是一种迁移学习技术,它利用一个训练好的教师模型(如具有较大样本量的中心模型)指导学生模型(每个客户端的本地模型)的学习。通过这种方法,即使数据分布不一致,每个客户端也能获得一个更贴合其本地数据的个性化模型。
为了进一步促进协作学习,CD2-pFed可能还采用了指数移动平均(Exponential Moving Average, EMA)算法,这是一种常用的模型更新策略,它可以在保持模型稳定的同时,逐渐融入新学习的信息。这种算法有助于防止模型过早收敛,确保在全局模型和本地模型之间找到一个平衡点。
CD2-pFed在联邦学习环境下提供了一种创新的策略,通过通道解耦和循环蒸馏相结合的方式,有效地应对了数据异质性问题,有望提升模型在各客户端上的泛化能力和个性化效果,为联邦学习领域的模型个性化研究开辟了新的方向。这将有助于改善现实世界中的许多场景,如医疗健康、物联网设备等,其中数据分散且隐私保护需求强烈。
CD
2
-pFed: Cyclic Distillation-guided Channel Decoupling for Model
Personalization in Federated Learning
Yiqing Shen
1
, Yuyin Zhou
2
, Lequan Yu
3
*
1
Shanghai Jiao Tong University,
2
UC Santa Cruz,
3
The University of Hong Kong
shenyq@sjtu.edu.cn, zhouyuyiner@gmail.com, lqyu@hku.hk
Abstract
Federated learning (FL) is a distributed learning
paradigm that enables multiple clients to collaboratively
learn a shared global model. Despite the recent progress,
it remains challenging to deal with heterogeneous data
clients, as the discrepant data distributions usually pre-
vent the global model from delivering good generalization
ability on each participating client. In this paper, we pro-
pose CD
2
-pFed, a novel Cyclic Distillation-guided Channel
Decoupling framework, to personalize the global model in
FL, under various settings of data heterogeneity. Differ-
ent from previous works which establish layer-wise per-
sonalization to overcome the non-IID data across different
clients, we make the first attempt at channel-wise assign-
ment for model personalization, referred to as channel de-
coupling. To further facilitate the collaboration between
private and shared weights, we propose a novel cyclic dis-
tillation scheme to impose a consistent regularization be-
tween the local and global model representations during the
federation. Guided by the cyclical distillation, our chan-
nel decoupling framework can deliver more accurate and
generalized results for different kinds of heterogeneity, such
as feature skew, label distribution skew, and concept shift.
Comprehensive experiments on four benchmarks, including
natural image and medical image analysis tasks, demon-
strate the consistent effectiveness of our method on both lo-
cal and external validations.
1. Introduction
Deep learning techniques have received notable attention
in various vision tasks, such as image classification [7], ob-
ject detection [31], and semantic segmentation [25]. Yet,
the success of deep neural networks heavily relies on a
tremendous volume of valuable training images. One possi-
ble solution is to collaboratively curate numerous data sam-
ples from different parties (e.g., different mobile devices
*
Corresponding Author.
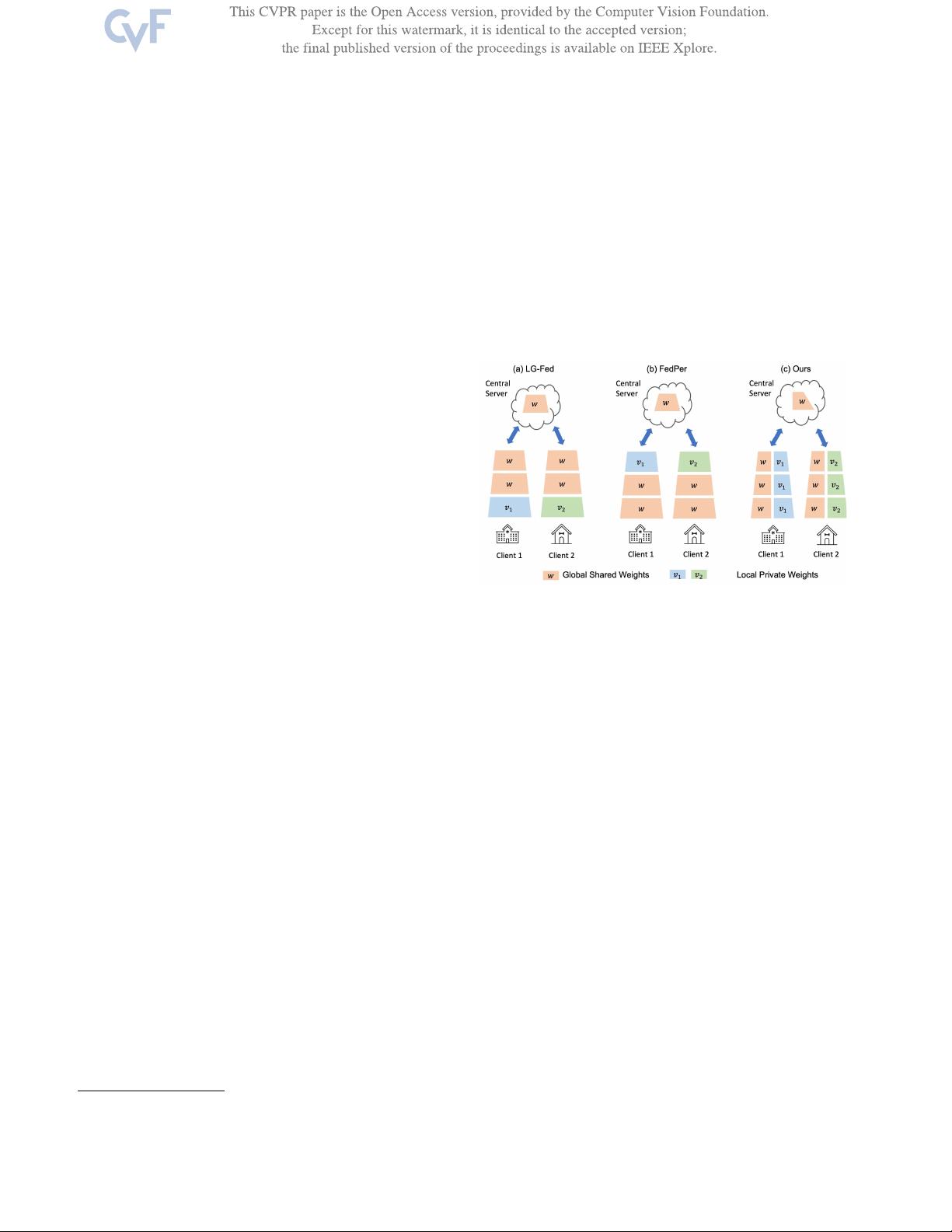
Figure 1. Illustration of different parameter decoupling manners
for model personalization in Federated Learning. The previous
approaches combine local and global parameters in a layer-wise
mechanism, including LG-Fed [22] in low-level input layers (a)
and FedPer [2] in high-level output layers (b). Instead, we achieve
model personalization via channel-wise decoupling (c).
and companies). However, collecting distributed data into a
centralized storage facility is costly and time-consuming.
Additionally, in real practice, decentralized image data
should not be directly shared, due to privacy concerns or
legal restrictions [1, 39]. In this case, conventional central-
ized machine learning frameworks fail to satisfy the data
privacy protection constraint.
Therefore, the data-private distributed training
paradigms, especially Federated Learning (FL), have
received an increasing popularity [3–5,19,24,28,36,47,50].
To be more specific, in FL, a shared model is globally
trained with an orchestration of local updates within data
stored at each client. A pioneering FL algorithm named
Federated Average (FedAVG), aggregates parameters at the
central server by communication across clients once per
global epoch, without explicit data sharing [28]. Compared
with local training, the federation on a larger scale of
training data has demonstrated its superiority to boost the
generalization ability on unseen data, with the orchestration
of distributed private data [6, 28].
10041
下载后可阅读完整内容,剩余9页未读,立即下载
2022-05-07 上传
2019-04-29 上传
2023-07-27 上传
2023-10-18 上传
2023-05-31 上传
2023-06-13 上传
2023-09-09 上传
2023-03-04 上传

Fun_Rock
- 粉丝: 5976
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
