CUDA优化技巧:提升GPU性能的秘诀
需积分: 9 118 浏览量
更新于2024-07-15
收藏 1.61MB PDF 举报
"CUDA优化技巧指南,由Stephen Jones在GTC2017上提出,主要探讨了在使用NVIDIA CUDA进行计算优化时的一些关键策略和注意事项,旨在帮助开发者更高效地利用GPU性能。"
CUDA(Compute Unified Device Architecture)是NVIDIA推出的一种并行计算平台和编程模型,它允许程序员直接利用GPU的并行处理能力来加速计算密集型任务。在CUDA编程中,优化是提高应用程序性能的关键步骤,本指南提供了几个重要的优化技巧和建议。
1. **不要过度努力(Rule #1: Don't Try Too Hard)**
开发者往往在优化初期会投入大量精力,但回报并不总是与付出成正比。图示显示了性能、时间和峰值性能的关系,强调应避免过早的兴奋和在“绝望的低谷”中放弃。正确的做法是在找到最佳平衡点后,适度投入时间减少无效工作,提升效率,进入性能增长曲线。
2. **性能约束(Performance Constraints)**
- **内存**:75%的性能问题可能源自内存。优化内存访问模式和减少内存带宽需求是关键。
- **占位率(Occupancy)**:GPU的占位率对性能有很大影响,占位率低可能导致计算单元利用率不足。
- **指令**:仅2%的性能问题可能与指令有关,优化代码流水线和减少分支预测错误可以提高性能。
- **分歧(Divergence)**:GPU的并行执行中,分支指令可能导致数据流分歧,影响效率,应尽量减少分歧。
- **计算强度(Compute Intensity)**:高计算强度的任务能更好地利用GPU,优化计算与内存访问的比例可以提高性能。
3. **CPU与GPU交互的性能约束**
- **数据传输**:CPU与GPU之间的数据传输速度较慢,应减少不必要的数据交换。
- **缓存效率**:有效利用GPU的缓存层次结构可显著提升性能。
- **寄存器溢出(Register Spilling)**:避免过多使用寄存器导致溢出,溢出的数据将被存储到速度较慢的全局内存中。
- **非一致访问(Divergent Access)**:确保所有线程块内的线程有相同的内存访问模式,以避免性能下降。
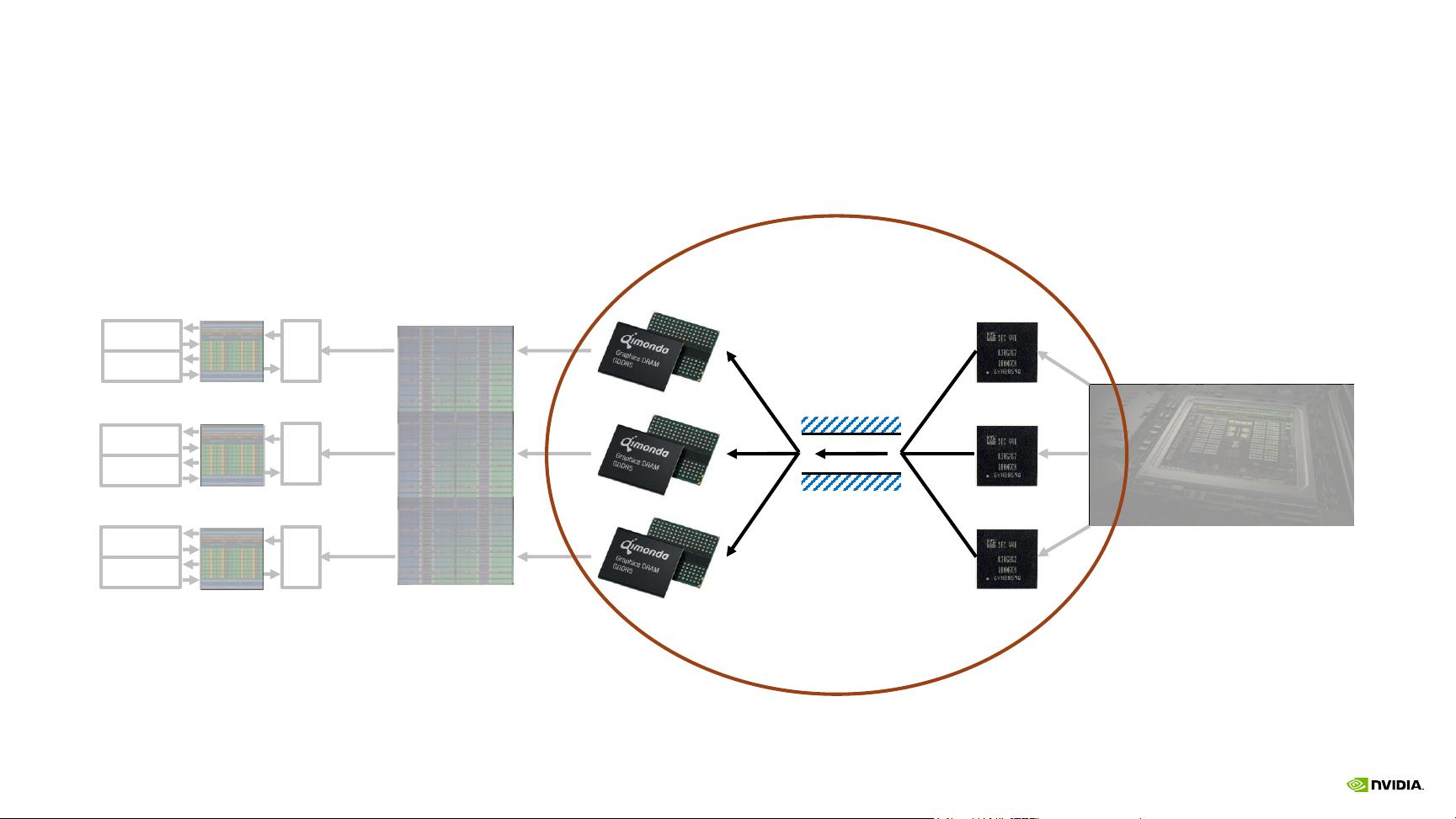
4. **内存访问的速度差异**
- CPU的DRAM、GPU的GDRAM、L2 Cache、L1 Cache以及共享内存(SM)的访问速度相差几个数量级。了解这些差异并设计合适的内存访问模式至关重要。
通过遵循这些CUDA优化技巧,开发者可以更好地理解和解决GPU计算中的性能瓶颈,实现更高的计算效率和应用性能。在实际项目中,结合具体场景和硬件特性进行针对性优化,将使CUDA程序发挥出更大的潜力。



2021-08-24 上传
2020-07-14 上传
2019-05-29 上传
2019-10-21 上传
2007-05-16 上传
2009-10-30 上传
2024-08-18 上传

TracelessLe
- 粉丝: 5w+
- 资源: 466
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
