"深入探索Spark实现的分层聚类算法——藏经阁涵盖UberEats与Mo"
需积分: 5 66 浏览量
更新于2024-03-11
收藏 6.92MB PDF 举报
The "Hierarchical clustering using spark" document, authored by Chen Jin, provides a comprehensive overview of the application of hierarchical clustering in the context of big data analysis using the Spark framework. The document begins by introducing the concept of hierarchical clustering and its significance in data analysis, particularly in the field of machine learning and pattern recognition. It then delves into the technical aspects of implementing hierarchical clustering using Spark, discussing key algorithms and methodologies involved in the process.
The document emphasizes the scalability and efficiency of using Spark for hierarchical clustering, highlighting its ability to handle large volumes of data and perform computations in a distributed manner. It also provides practical examples and code snippets to illustrate the implementation of hierarchical clustering algorithms using Spark, making it a valuable resource for data scientists and engineers working in the field of big data analytics.
Additionally, the document discusses the potential applications of hierarchical clustering in real-world scenarios, such as customer segmentation in the food delivery industry (as exemplified by UberEats). It demonstrates how hierarchical clustering can be used to group similar entities together based on their attributes, enabling businesses to gain valuable insights and make data-driven decisions.
Overall, the "Hierarchical clustering using spark" document serves as a comprehensive guide for understanding and implementing hierarchical clustering in the context of big data analysis using Spark. Its practical approach, combined with theoretical insights, makes it an invaluable resource for professionals and researchers seeking to leverage the power of hierarchical clustering for deriving meaningful patterns and insights from large datasets.
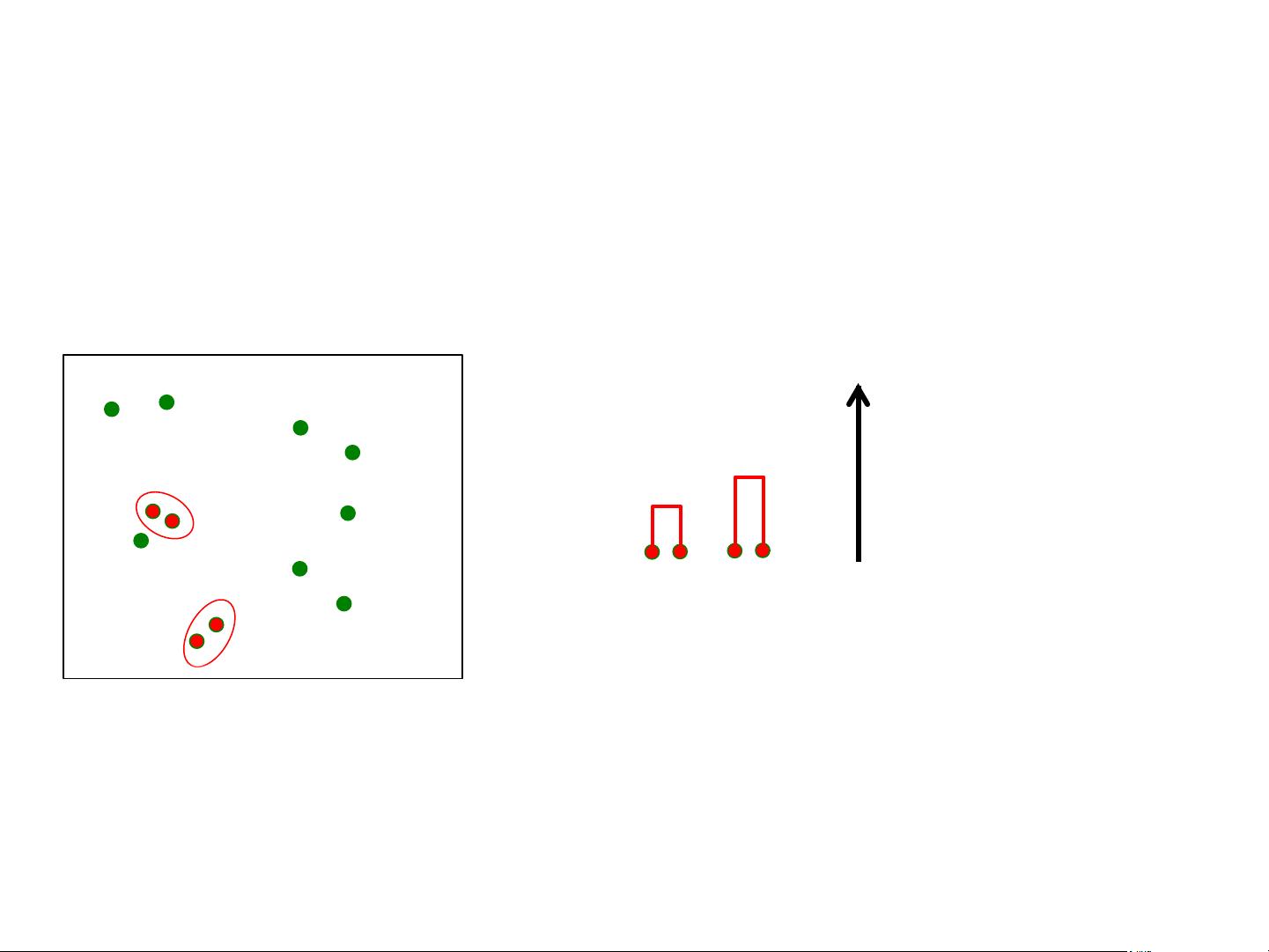
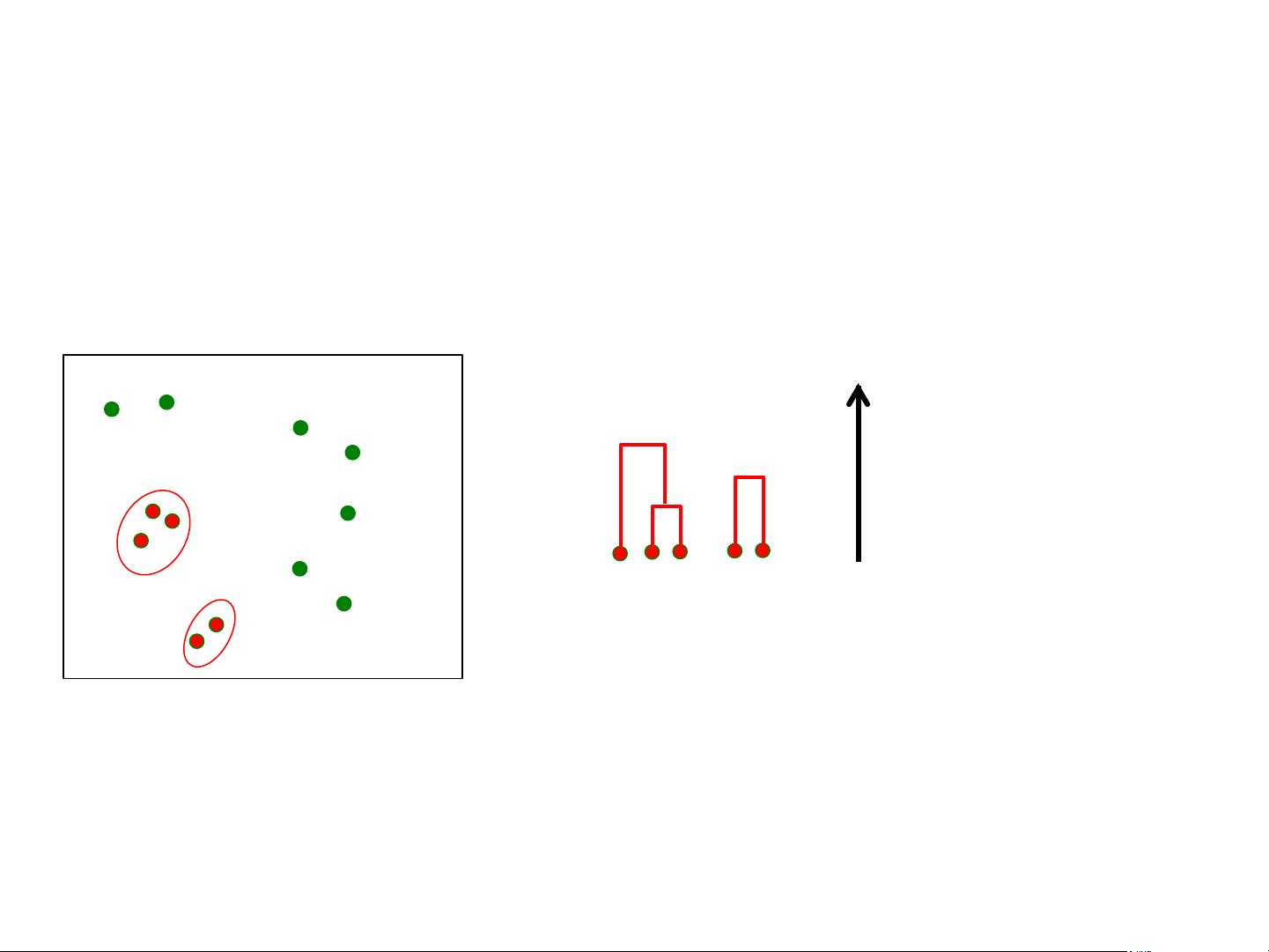
Example:'Hierarchical'Clustering'
(Iter'2)'
Dendrogram:'Data:'
Height'of'the'
join'indicates'
dissimilarity'
剩余30页未读,继续阅读
2023-04-24 上传
2023-03-30 上传
2023-05-04 上传
2023-04-19 上传
2023-06-08 上传
2023-05-24 上传
2023-04-17 上传
2023-03-04 上传

weixin_40191861_zj
- 粉丝: 83
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
