深入理解与实战 Memcached 分布式缓存技术
需积分: 32 135 浏览量
更新于2024-07-27
收藏 611KB PDF 举报
"本文主要介绍了Memcached的基本原理和使用方法,包括它的介绍、安装与使用、一些实用技巧以及常见问题解答。"
Memcached是互联网上广泛使用的高性能分布式内存缓存系统,由LiveJournal的开发团队设计,目的是加速动态Web应用程序的运行速度,通过缓存数据库查询结果来减少对数据库的访问,从而提升系统的可扩展性。它最初是为了优化社区网站的性能而诞生的,并且随着时间的发展,成为了许多大型网站和应用的关键组件。
**Memcached的原理:**
Memcached基于一个简单的键值存储模型,将数据存储在内存中,以提供快速的读取速度。它的工作机制是,当客户端需要获取数据时,首先尝试从缓存中查找,如果找到则直接返回,无需访问后端数据库;若未找到,则从数据库获取数据并存储到缓存中,以便后续请求可以直接使用。这种设计极大地减少了数据库的负载,尤其是在高并发场景下。
**Memcached的安装与使用:**
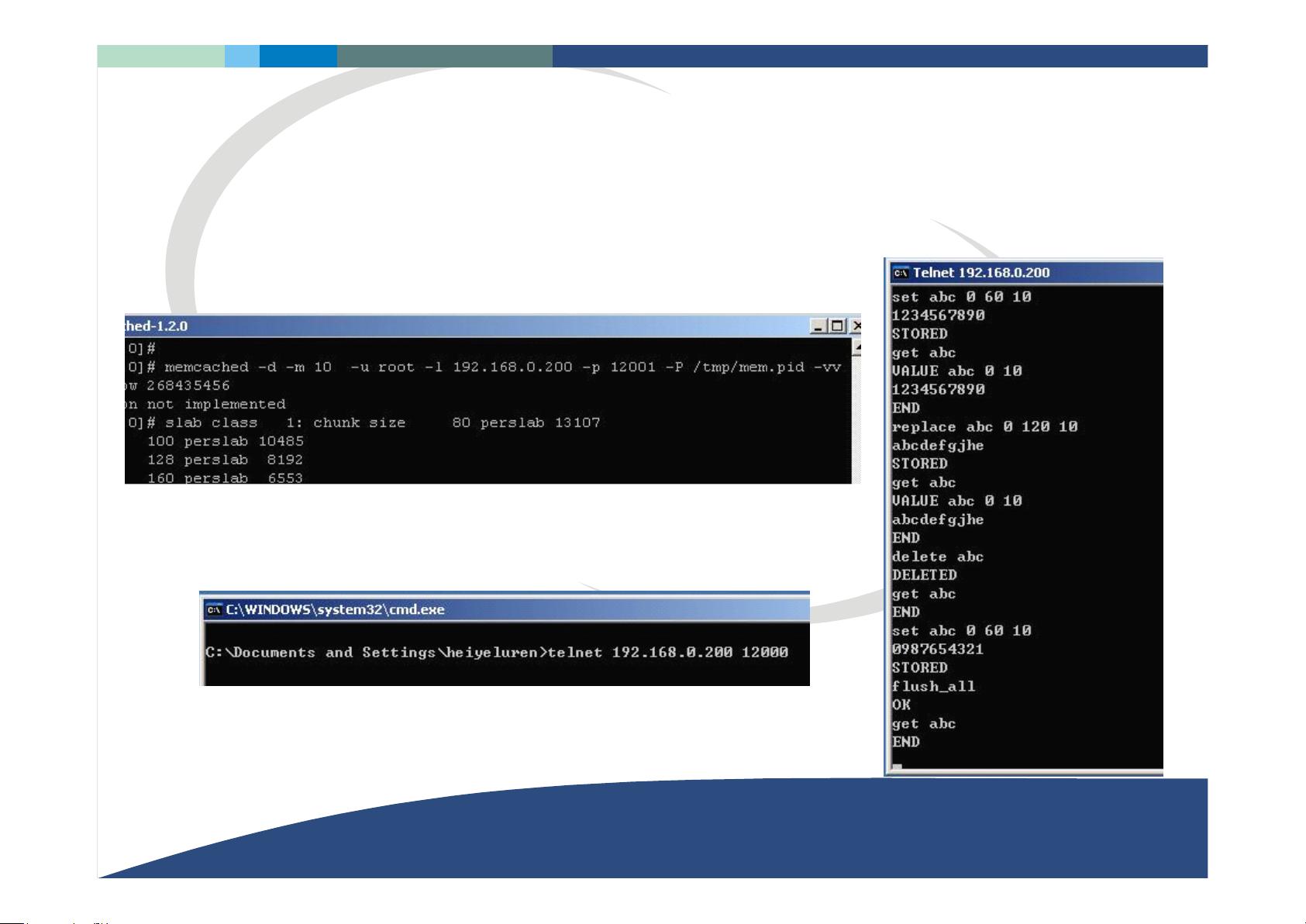
安装Memcached通常涉及编译源代码并在服务器上启动服务。在Linux系统中,可以通过包管理器如`apt-get`或`yum`进行安装。配置完成后,使用命令行工具启动服务。对于应用开发者,需要集成Memcached客户端库,如Python的`pylibmc`,PHP的`memcache`扩展等,以与Memcached服务进行交互。
**一些技巧:**
1. **数据过期策略**:Memcached支持设置缓存项的生存时间(TTL),超过这个时间后,缓存项会自动失效。
2. **空间利用**:由于内存资源有限,合理地设置数据大小和数量,避免浪费空间。
3. **一致性哈希**:用于在多台Memcached服务器之间分配数据,减少数据迁移的影响。
4. **预热策略**:在系统启动或更新后,可以预先加载常用数据到缓存中,提高系统响应速度。
5. **缓存击穿与穿透**:避免大量请求同一不存在的键导致数据库压力增大,可以使用布隆过滤器等手段预防。
**Q&A:**
常见问题可能包括内存管理、缓存一致性、故障恢复、性能优化等。例如,当内存不足时,Memcached会采用LRU(Least Recently Used)策略淘汰最近最少使用的数据。在分布式环境中,如何确保数据的一致性是一个挑战,通常需要结合业务逻辑来处理。此外,监控和调整Memcached的参数也是保证其高效运行的重要环节。
Memcached作为一款轻量级、高效的缓存解决方案,对于提升Web应用性能有着显著的作用。理解和掌握其原理及使用技巧,可以帮助开发者更好地优化系统架构,解决高并发下的性能瓶颈。

7
Memcached
Memcached
介绍
介绍
Memcached
Memcached
的主要特点
的主要特点
•
•
基于
基于
C/S
C/S
架构,
架构,
协议简单
协议简单
•
•
基于
基于
libevent
libevent
的事件处理
的事件处理
•
•
自主内存存储处理
自主内存存储处理
•
•
基于客户端的
基于客户端的
Memcached
Memcached
分布式
分布式
剩余39页未读,继续阅读
2019-07-23 上传
2009-05-21 上传
2013-05-17 上传
2018-08-03 上传
2023-09-18 上传
2010-10-27 上传
2009-03-24 上传
点击了解资源详情
点击了解资源详情

lixin493467132
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
