理解GBDT:从梯度提升到XGBoost与LightGBM
下载需积分: 14 | PDF格式 | 2.57MB |
更新于2024-07-09
| 14 浏览量 | 举报
"该PDF文件主要探讨了GBDT(Gradient Boosting Decision Tree)、XGBoost以及LightGBM这三种机器学习中的集成学习方法,特别是它们在数据科学和人工智能领域的应用。文档介绍了GBDT的基本概念、训练过程以及其与Boosting和Bagging的区别,特别强调了GBDT中负梯度拟合的概念。"
GBDT(Gradient Boosting Decision Tree)是一种基于决策树的机器学习算法,它属于Boosting家族。Boosting是一种集成学习技术,通过组合多个弱分类器或回归器,构建出一个强学习器。与Bagging(Bootstrap Aggregating)并行训练多个模型不同,Boosting是逐步添加模型,每个新模型都是为了修正之前模型的错误或不足。
在GBDT的训练过程中,采用的是Additive Training,即逐次增加模型的方式。首先从一个常数预测开始,每次迭代时,会拟合上一轮所有模型预测后的残差,这个残差的方向指示了优化的方向。通过构建新的决策树来拟合这些残差,从而在下一次预测时减小整体误差。这种基于残差的训练方式,使得每一棵树都专注于解决上一棵树未能处理的问题,从而提高整体模型的性能。
文档提到,GBDT的目标是在每次迭代中找到一个CART(Classification And Regression Trees)回归树,以最小化损失函数。但是,损失函数的形式各异,如何找到一个通用的优化方法呢?这里引入了负梯度拟合的概念。Freidman提出使用损失函数的负梯度作为目标,通过最小化这个负梯度来构建回归树。这样,每一轮的决策树都试图沿着损失函数下降最快的方向移动,从而逐渐优化模型。
GBDT算法的流程大致如下:
1. 初始化一个简单的模型,通常是常数值。
2. 对于t次迭代(t=1,2,...,T),执行以下步骤:
a) 计算每个样本的负梯度,这是当前模型的优化方向。
b) 使用这些负梯度信息训练一个CART回归树。
c) 在每个叶节点区域确定最佳拟合值,更新模型。
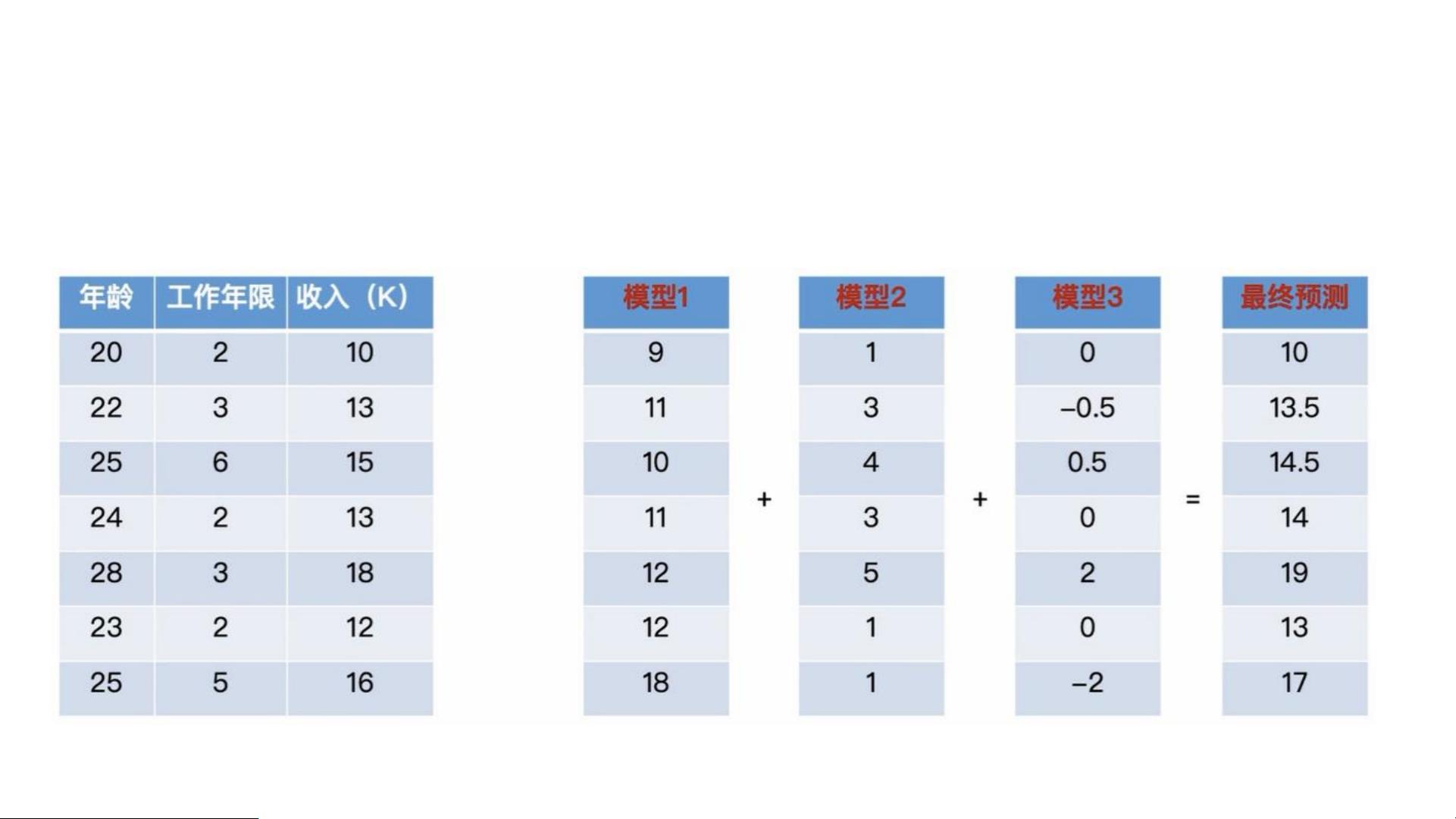
最后,GBDT的最终预测结果是所有弱学习器预测结果的加权和。这种迭代过程使得GBDT能够逐步改进模型,有效地处理非线性和交互效应,广泛应用于各种预测任务,包括分类和回归问题。
XGBoost和LightGBM是GBDT的优化实现,它们在效率和准确性上进行了提升,例如,XGBoost通过并行计算和列采样提高了训练速度,而LightGBM采用了直方图法和Leaf-wise生长策略,进一步减少了计算量和过拟合的风险。这些优化的GBDT实现使得在大数据和高维特征的场景下,模型训练变得更加可行和高效。
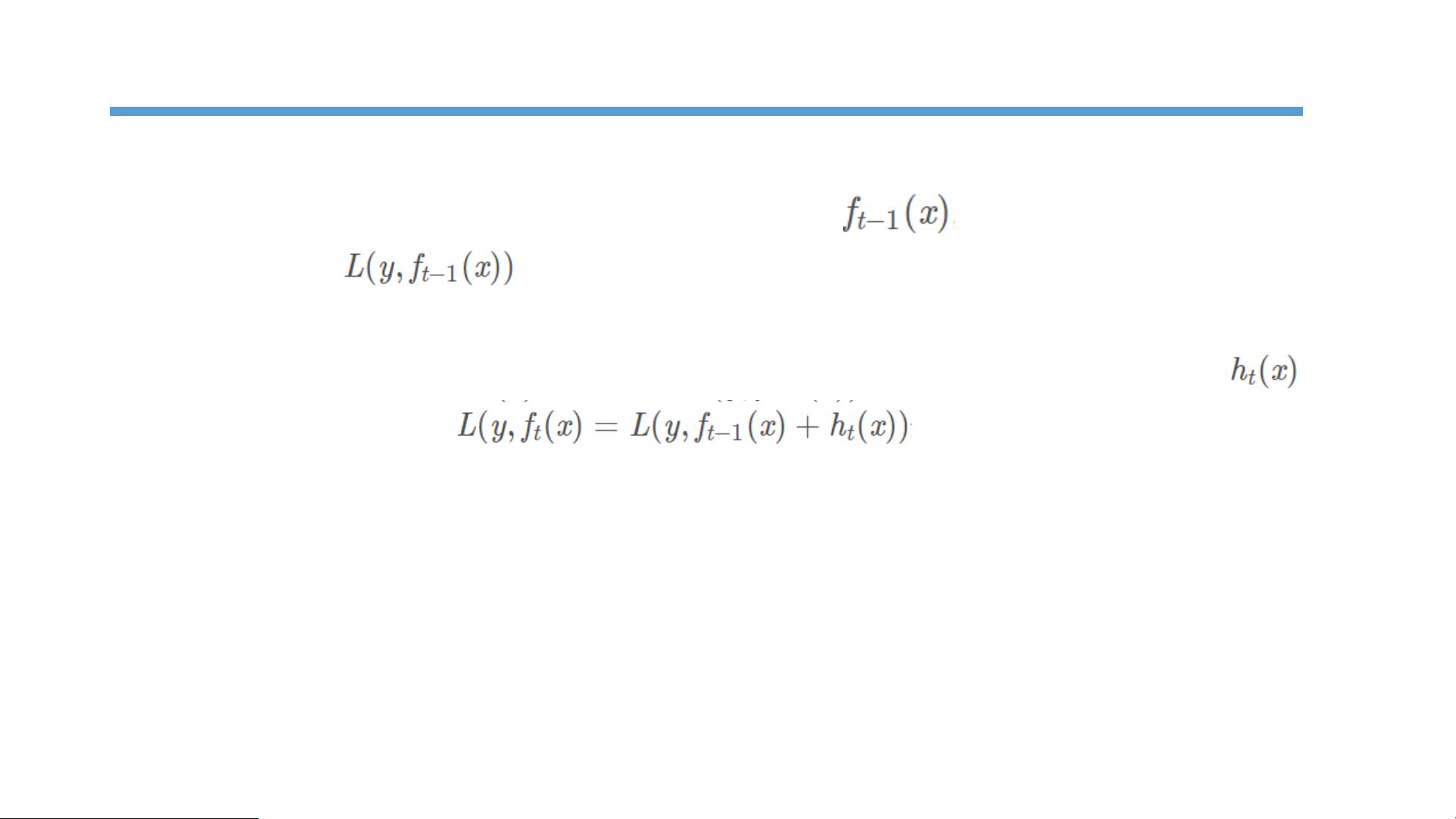

相关推荐




weixin_53576108
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
