SQL Server 实时分析处理:内存优化与列存储增强
需积分: 0 160 浏览量
更新于2024-08-03
收藏 1.26MB PDF 举报
"使用 Microsoft SQL Server 进行实时分析处理(Real-Time Analytical Processing)"
Microsoft SQL Server 是一种广泛使用的数据库管理系统,它具有丰富的特性和工具,可以满足现代企业对实时数据分析处理的需求。实时分析处理(Real-Time Analytical Processing, RTAP)在当前大数据时代尤为重要,因为它允许企业快速响应不断变化的数据并作出及时决策。
1. 实时数据处理需求:
RTAP 概念强调了企业在实时环境中获取、分析和响应数据的能力。随着数据生成的速度加快,企业需要能够即时处理和解析这些数据,以便对市场动态、用户行为和其他关键业务指标做出快速反应。这种需求源于对决策速度和准确性的追求,尤其是在金融、零售和互联网服务等行业。
2. SQL Server 的实时分析功能:
- 内存优化表:SQL Server 提供的内存优化表可以显著提升数据处理速度,因为它们将数据保留在内存中,减少了磁盘I/O操作。
- 列存储索引:列式存储对于分析查询特别有效,因为它优化了对大量数据的读取,尤其适合于聚合操作。
- 实时数据传输:SQL Server 支持多种方式实时获取和处理数据,如Change Data Capture (CDC) 和流处理,这些技术可以帮助系统实时捕获和处理新产生的数据。
3. 架构设计:
构建实时分析处理的 SQL Server 架构涉及多个层面的设计。这包括选择合适的数据采集方法(如ETL流程)、内存管理和存储策略(如使用列存储索引)、以及优化查询处理(例如使用适当的数据分区和索引)。此外,需要考虑系统扩展性,确保在数据量增长时仍能保持高性能。
4. 性能优化:
为了确保在高负载下稳定运行,SQL Server 提供了多种性能优化手段,包括资源调度器来管理并发查询,以及性能监视和调优工具。例如,可以通过调整内存分配、索引优化和查询计划选择来提升查询性能。
5. 案例研究:
论文可能会提供具体实例,展示如何在不同行业中运用 SQL Server 实现RTAP。这些案例可能涵盖如何利用SQL Server的特性解决特定的实时分析挑战,比如实时监控销售数据、预测库存需求或分析用户行为。
"Real-Time Analytical Processing with SQL Server" 论文深入探讨了如何通过 SQL Server 的特性来满足实时分析处理的需求,提供了从架构设计到性能优化的全方位指导,帮助企业利用最新的数据库技术实现数据驱动的实时决策。
references only Hekaton tables can be compiled into native ma-
chine code for further performance gains [3].
2.2.1 Tables and indexes
Hekaton tables and indexes are optimized for memory-resident
data. Rows are referenced directly by physical pointers, not indi-
rectly by a logical pointer such as a row ID or primary key. Row
pointers are stable; a record is never moved after it has been created.
A table can have multiple indexes, any combination of hash indexes
and range indexes. A hash index is simply an array where each en-
try is the head of a linked list through rows. Range indexes are im-
plemented as Bw-trees which is novel latch-free version of B-trees
optimized for main-memory [10].
2.2.2 Multi-versioning
Hekaton uses multi-versioning where an update creates a com-
pletely new version of a row. The lifetime of a version is defined
by two timestamps, a begin timestamp and an end timestamp and
different versions of the same row have non-overlapping lifetimes.
A transaction specifies a logical read time for all its reads and only
versions whose lifetime overlaps the read time are visible to the
transaction.
Multi-versioning improves scalability because readers no longer
block writers. (Writers may still conflict with other writers though.)
Read-only transactions have little effect on update activity; they
simply read older versions of records as needed. Multi-versioning
also speeds up query processing be reducing copying of records.
Since a version is never modified it is safe to pass around a pointer
to it instead of making a copy.
3. CSI ON IN-MEMORY TABLES
The Hekaton engine stores tables in memory and is very efficient
on OLTP workloads. SQL Server 2016 allows users to create col-
umn store indexes also on in-memory tables. This enables efficient
and concurrent real-time analysis and reporting on operational data
without unduly hurting the performance of transaction processing.
3.1 Architecture
A user creates a Hekaton table with a secondary CSI using the fol-
lowing syntax.
CREATE TABLE <table_name> (
···
INDEX <index_name> CLUSTERED COLUMNSTORE
···
) WITH (MEMORY_OPTIMIZED = ON)
The table is defined with the MEMORY_OPTIMIZED option set
to ON so it is stored in memory and managed by Hekaton. A sec-
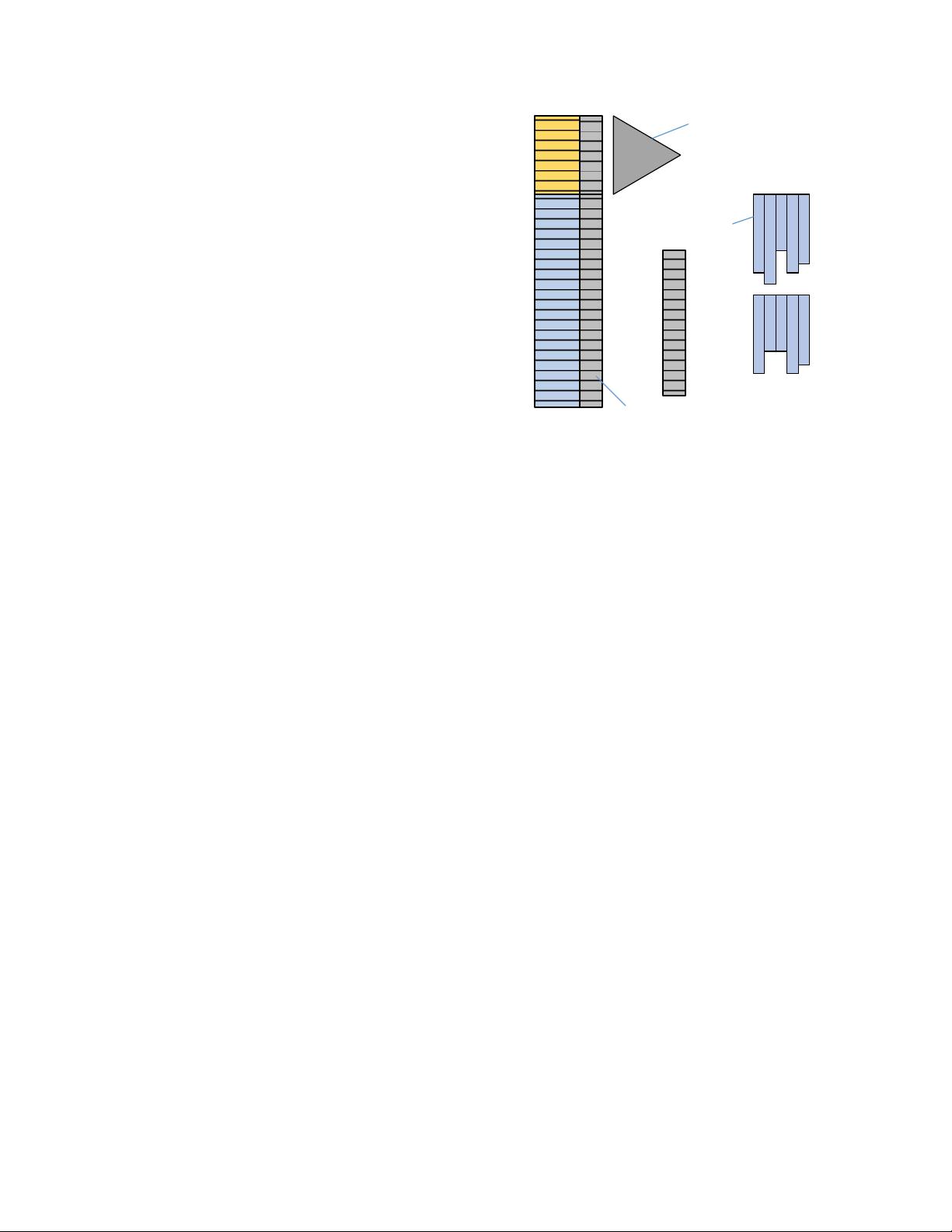
ondary CSI covering all columns is also created. Figure 2 shows
the components constructed when the table is created.
All rows are stored in the in-memory Hekaton table (shown on the
left) which may have one or more hash or range indexes. Most of
the rows (shown in blue) are also stored in the CSI in columnar
format. The CSI is shown as containing two row groups, each with
five compressed column segments. Data is duplicated between the
Hekaton table and the CSI but in practice the space overhead is
small because of compression. The space overhead is data depend-
ent but typically in the range 10% to 20%.
The upper portion (in yellow) of the Hekaton table in Figure 2 rep-
resents rows that are not yet included in the CSI. We call this por-
tion the tail of the table. New rows and new versions of rows are
inserted into the Hekaton table only, thus growing the tail. A back-
ground thread is responsible for copying rows in the tail portion
into the column store (see Section 3.3 for details).
The Hekaton table contains a hidden row ID (RID) column that in-
dicates the location of the row in the column store. A RID consists
of a row group ID that identifies the compressed row group and the
position within the row group. The RID column allows a row in the
column store to be efficiently located in CSI which is crucial for
fast online processing of updates and deletes.
For rows in the tail of the Hekaton table, the value in the RID col-
umn is a special invalid value which makes it easy to identify rows
still in the tail. These rows are included in a hidden Tail Index
which is shown as a triangle to the right of the table in Figure 2. All
rows not yet included in the CSI can be easily found by scanning
the Tail Index. This is needed for table scans that use the CSI and
also when migrating rows to the CSI.
The Deleted Rows Table shown in Figure 2 is a hidden Hekaton
table that contains RIDs of rows in the CSI that have been deleted
from the user table. This table is checked during scans to identify
rows that have been logically deleted and thus should be skipped.
The compression and decompression algorithms are the same for
this CSI as for regular SQL Server CSI but the storage for com-
pressed data is different. The compressed row groups and all
metadata about them are stored in internal Hekaton tables, which
allows Hekaton versioning to work correctly for CSI scans.
Each row group is stored in a separate file on stable storage; this
permits the system to evict a compressed segment from memory
and reload it as needed, so that only segments that are in use will
consume memory resources.
3.2 User Operations
Hekaton normally manages the most performance-critical tables of
a database so it is crucial that adding a CSI not significantly reduce
OLTP performance. Ideally, the overhead during normal operations
should be no higher than that of a Bw-tree index.
Inserting a new row or row version into the user table consists of
inserting the row into the in-memory Hekaton table and adding it
In-memory
table
Columnstore
index
Deleted
rows table
RID column
Tail index covers rows
not (yet) included in
column store
Figure 2: Components of design enabling
column store indexes on Hekaton tables
Row group with 5
column segments
1742
剩余11页未读,继续阅读
2021-02-19 上传
2019-05-04 上传
2015-11-19 上传
2022-08-04 上传
2022-06-19 上传
2022-09-14 上传
点击了解资源详情
点击了解资源详情

Mr.恰饭
- 粉丝: 34
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
