大数据平台架构设计:lambda与kappa探讨,实战提升业务效能
版权申诉
3 浏览量
更新于2024-09-03
收藏 466KB DOCX 举报
本文深入探讨了大数据平台架构设计的关键要素,特别是在当今企业日益重视数据资产管理和利用的背景下。首先,作者概述了大数据的基础组件,如Hadoop/Spark/Flink等,并介绍了Python在大数据领域的应用,特别是与数据仓库(Data Warehouse)的结合。这部分旨在为读者提供一个全面的技术背景,理解数据处理的核心技术。
接下来,文章重点讨论了lambda架构和kappa架构这两种主流的大数据处理模式。Lambda架构以其灵活性和容错性,允许开发人员构建高可用的分布式系统,而kappa架构则强调事件驱动和最终一致性。这两者各有优缺点,企业需要根据自身业务需求和复杂性选择合适的架构模式。
在第三部分,作者详述了基于lambda或kappa架构的大数据架构模型,涵盖了数据处理的整个生命周期,包括数据采集、传输、实时计算和离线分析。这部分内容有助于读者理解如何在实际场景中整合这些组件,以实现高效的数据处理流程。
第四部分,作者揭示了在暴露的数据架构体系下,数据从端到端存在的挑战和痛点,比如数据不可知性、需求实现困难和数据共享难题。这些问题促使架构设计必须考虑业务需求的优先级,减少数据开发中的痛点。
最后,文章的核心部分是优秀的大数据平台整体设计。目标是通过集成各种数据平台和组件,构建一个易于使用且高度集中的数据平台,简化业务开发者的数据处理工作。这种设计允许开发者使用SQL等标准工具进行一站式开发,从而降低对底层技术的依赖,使得大数据不再仅仅是数据工程师的专业技能,而是所有业务人员都能触达的工具。
总结来说,本文围绕大数据平台架构设计,从技术栈、架构模式、实际操作难题到解决方案进行了深入剖析,为企业在数字化转型过程中设计和优化数据基础设施提供了实用指南。无论是对于数据专业人员还是业务用户,这篇文章都是一份宝贵的参考资料。
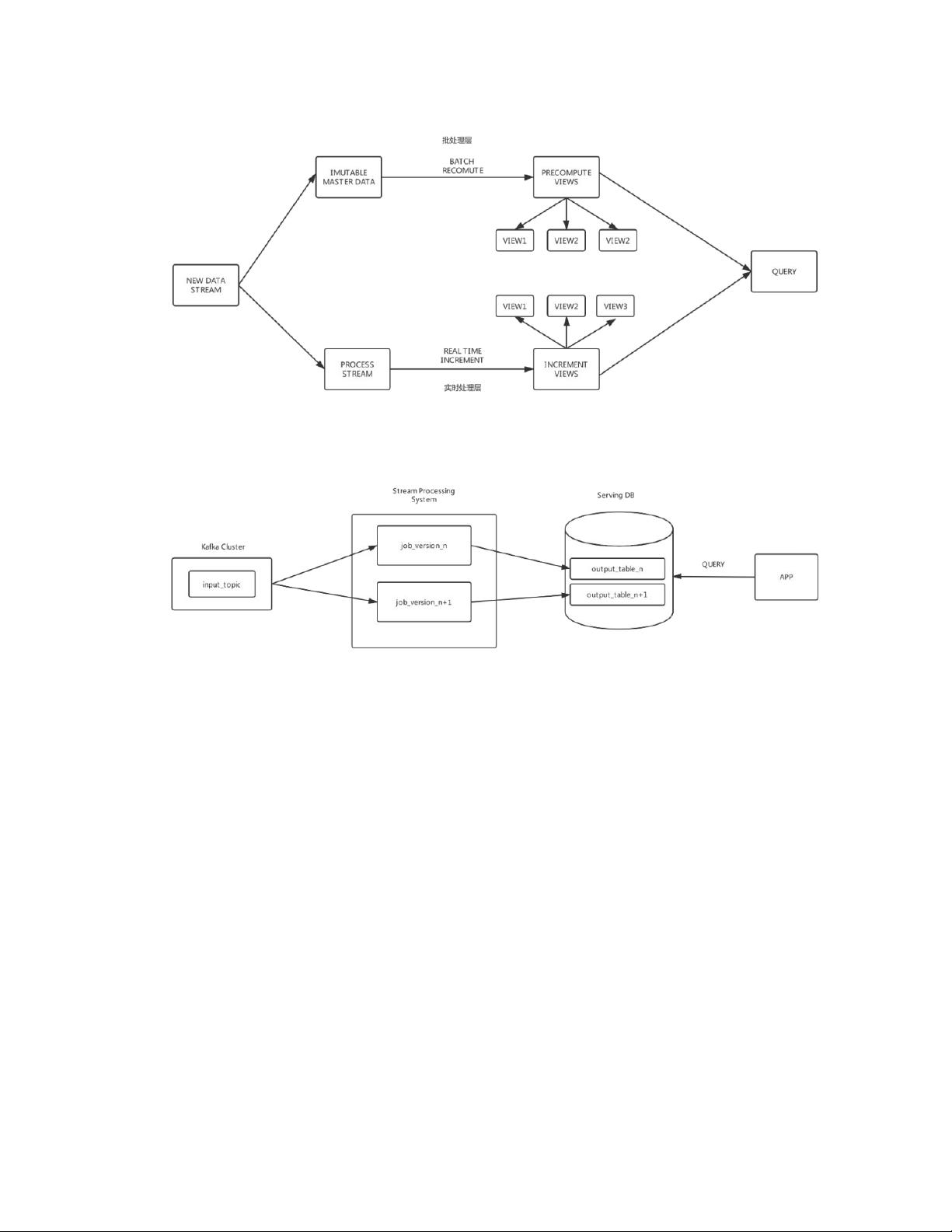
Kappa 架构
三、kappa 架构和 lambda 架构下的大数据架构
目前各大公司基本上都是使用 kappa 架构或者 lambda 架构模式,这两种模
式下大数据全体架构在晚期进展阶段可能是下面这样的:
剩余11页未读,继续阅读
2022-11-13 上传
2022-07-14 上传
2022-06-13 上传
2022-02-16 上传
2022-12-18 上传
2021-10-31 上传
2021-11-01 上传
2022-02-23 上传
2022-01-25 上传

bingbingbingduan
- 粉丝: 0
- 资源: 7万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
