Python requests教程:爬虫实战与浏览器工具分析
 已收录资源合集
已收录资源合集
需积分: 0 49 浏览量
更新于2024-08-03
收藏 6.94MB DOCX 举报
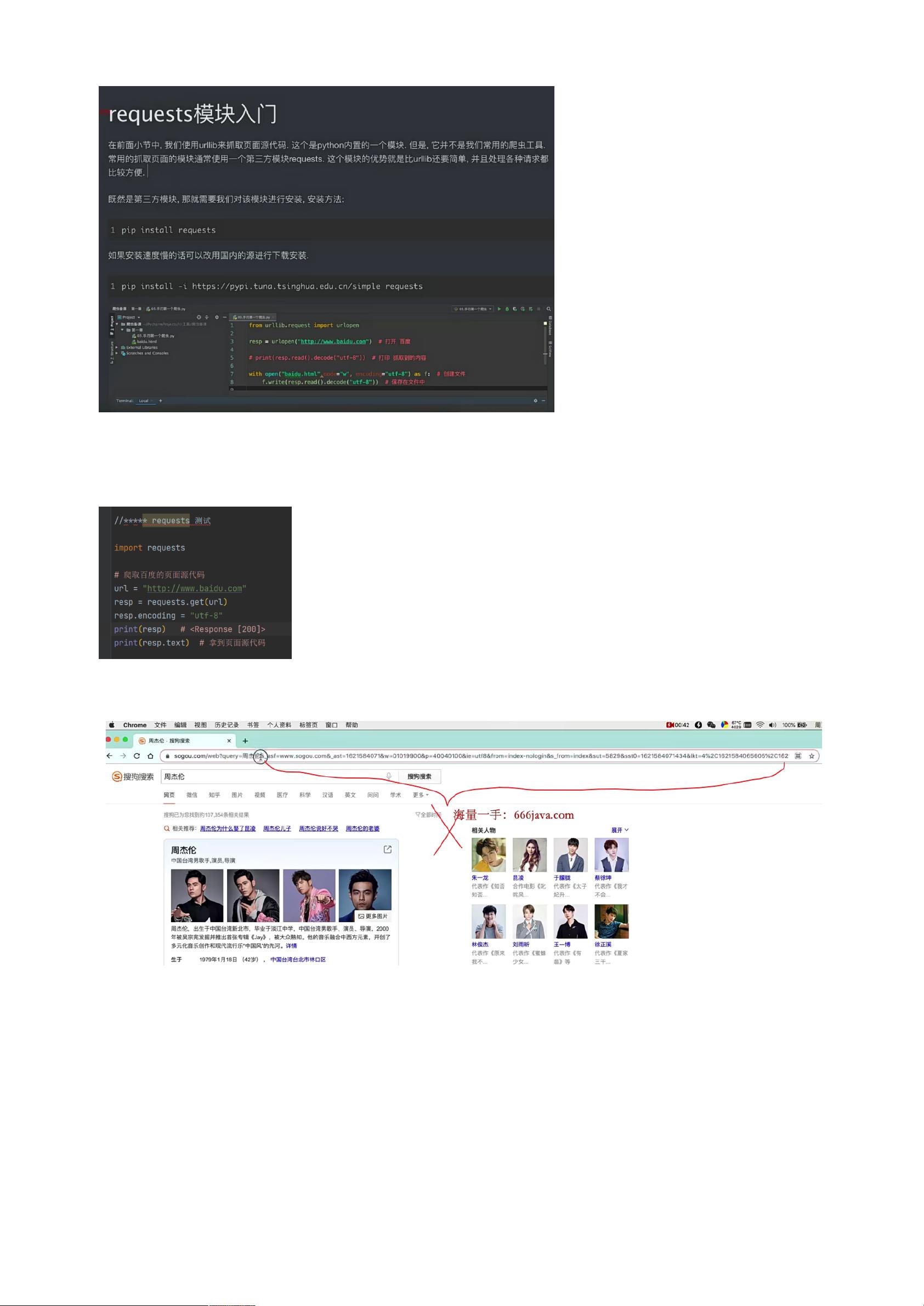
本文档主要介绍了如何使用Python的requests库进行爬虫操作,特别是在处理动态加载或需要加密数据的网站时的技巧。requests模块是Python中一个常用的HTTP库,用于发起HTTP请求,适合进行基础的网络数据抓取。
首先,针对那些访问量不高的网站,作者建议采用分步请求的方式。这意味着在实际爬取过程中,不是一次性发送所有的数据,而是先发送数据结构或请求头(即“壳子”),之后再根据返回的结构来决定何时发送具体的数据。这样做的好处包括减轻服务器压力、便于数据加密和维护,以及保持请求的隐蔽性。
在分析网页时,通常直接查看源代码("Source")并不能获取完整的数据,因为某些内容可能是通过JavaScript动态生成或加密的。这时,开发者可以利用浏览器的开发者工具,如"Elements"和"Network"(抓包工具)来辅助工作。Elements显示的是经过脚本处理后的页面内容,而Network则展示了完整的请求过程,包括发送的RequestHeaders(请求附加信息)、ResponseHeaders(服务器响应头)等。
ResponseHeaders包含重要的信息,比如状态码,如200表示正常访问,404表示URL错误,500代表服务器内部错误。在处理敏感数据时,可能需要关注ResponseHeaders中的cookies,它们是网站用来存储用户信息的,如登录凭证。加密的数据可能通过特定的密钥在响应头中隐藏。
若遇到终端环境问题无法直接使用requests模块,可以通过pip install requests命令进行安装。至于文档提到的周杰伦部分,显然这部分内容与爬虫技术无关,可以忽略。
本文强调了在实际爬虫项目中,理解和利用requests库的细致之处,以及如何通过浏览器工具来解析动态加载的网页内容,这对于深入理解网络请求和数据抓取技术至关重要。
如果,你的终端(terminal)无法打开,那就看下面的四种方法解决就行。文章后面有~~
终端输入:pip install requests 下载 requests 模块
去代码块***
周杰伦,后面的内容都没用!可以删掉
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-12-22 上传
2023-08-26 上传
2024-02-21 上传
2023-03-09 上传
2024-09-08 上传

麦合学长
- 粉丝: 185
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
