FCOS:无锚点单阶段目标检测算法
需积分: 20 62 浏览量
更新于2024-09-02
收藏 3.25MB PDF 举报
FCOS全卷积单阶段目标检测(FCOS: Fully Convolutional One-Stage Object Detection)是一项创新的深度学习方法,由Zhi Tian、Chunhua Shen等人提出,发表在论文中。该研究旨在解决物体检测问题,以像素级预测的方式进行,类似于语义分割任务。与当时主流的诸如RetinaNet、SSD、YOLOv3和Faster R-CNN等依赖预定义锚框的检测器不同,FCOS是一个无锚框、无提案的检测器。
FCOS的核心优势在于其彻底摒弃了预先定义的锚框。这消除了与锚框相关的复杂计算,如训练时的重叠计算,从而简化了算法流程。更为关键的是,FCOS消除了与锚框相关的超参数调整,这些参数往往对最终的检测性能具有显著影响。这意味着模型的训练更加直观,减少了对繁琐参数调优的需求。
FCOS的主要贡献在于其单一模型和单尺度测试下的性能表现。使用ResNeXt-64x4d-101架构,FCOS在保持简单性的同时,实现了44.7%的AP(平均精度),这一成绩超越了许多现有的单阶段检测器,证明了其在效率和精度方面的优越性。此外,作者首次展示了目标检测任务可以采用一种更为简单且灵活的方法来实现,这为未来的研究提供了新的思路。
该工作对于物体检测领域来说是一次重大突破,它不仅提高了检测性能,还降低了技术复杂度,使得模型更容易部署和优化。FCOS的出现,标志着单阶段目标检测技术向着更加成熟和实用的方向发展,对后续的研究者和工程师具有重要的参考价值。
x4
Classification
H
x
W
x
C
Center-ness
H
x
W
x
1
x4
H
x
W
x256
Regression
H
x
W
x
4
Shared Heads Between Feature Levels
C5
C4
C3
P7
P6
P5
P4
P3
Head
Backbone Feature Pyramid
Head
Head
Head
Head
Classification + Center-ness + Regression
100x128 /8
50x64 /16
25x32 /32
1 3x1 6 /64
7x8 /128
H
x
W
/
s
800x1 024
H
x
W
x256
H
x
W
x256
H
x
W
x256
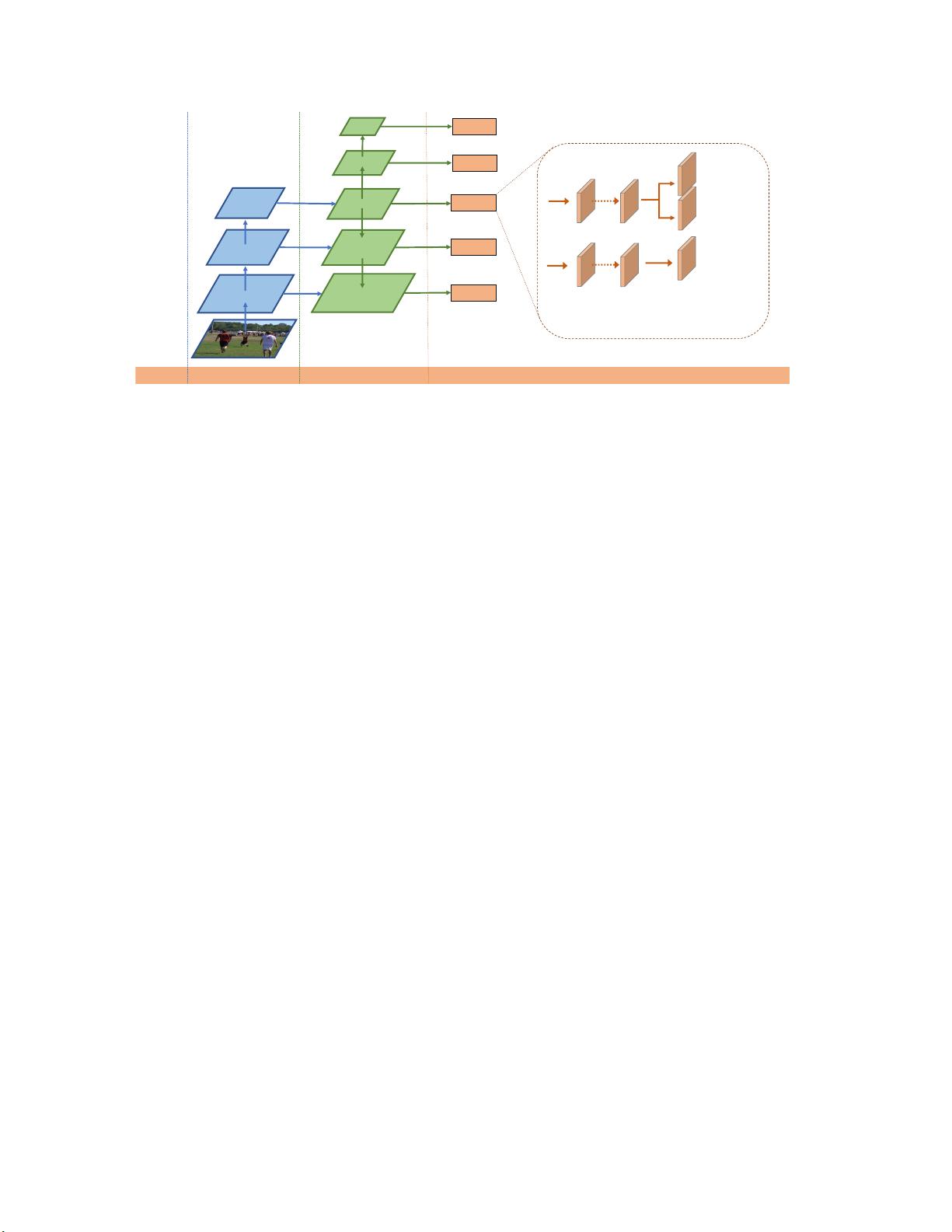
Figure 2 – The network architecture of FCOS, where C3, C4, and C5 denote the feature maps of the backbone network and P3 to P7 are
the feature levels used for the final prediction. H × W is the height and width of feature maps. ‘/s’ (s = 8, 16, ..., 128) is the down-
sampling ratio of the feature maps at the level to the input image. As an example, all the numbers are computed with an 800 × 1024
input.
to be carefully tuned in order to achieve good perfor-
mance. Besides the above hyper-parameters describing an-
chor shapes, the anchor-based detectors also need other
hyper-parameters to label each anchor box as a positive,
ignored or negative sample. In previous works, they of-
ten employ intersection over union (IOU) between anchor
boxes and ground-truth boxes to determine the label of an
anchor box (e.g., a positive anchor if its IOU is in [0.5, 1]).
These hyper-parameters have shown a great impact on the
final accuracy, and require heuristic tuning. Meanwhile,
these hyper-parameters are specific to detection tasks, mak-
ing detection tasks deviate from a neat fully convolutional
network architectures used in other dense prediction tasks
such as semantic segmentation.
Anchor-free Detectors. The most popular anchor-free
detector might be YOLOv1 [21]. Instead of using anchor
boxes, YOLOv1 predicts bounding boxes at points near
the center of objects. Only the points near the center are
used since they are considered to be able to produce higher-
quality detection. However, since only points near the cen-
ter are used to predict bounding boxes, YOLOv1 suffers
from low recall as mentioned in YOLOv2 [22]. As a result,
YOLOv2 [22] employs anchor boxes as well. Compared to
YOLOv1, FCOS takes advantages of all points in a ground
truth bounding box to predict the bounding boxes and the
low-quality detected bounding boxes are suppressed by the
proposed “center-ness” branch. As a result, FCOS is able to
provide comparable recall with anchor-based detectors as
shown in our experiments.
CornerNet [13] is a recently proposed one-stage anchor-
free detector, which detects a pair of corners of a bound-
ing box and groups them to form the final detected bound-
ing box. CornerNet requires much more complicated post-
processing to group the pairs of corners belonging to the
same instance. An extra distance metric is learned for the
purpose of grouping.
Another family of anchor-free detectors such as [32] are
based on DenseBox [12]. The family of detectors have been
considered unsuitable for generic object detection due to
difficulty in handling overlapping bounding boxes and the
recall being relatively low. In this work, we show that both
problems can be largely alleviated with multi-level FPN
prediction. Moreover, we also show together with our pro-
posed center-ness branch, the much simpler detector can
achieve even better detection performance than its anchor-
based counterparts.
3. Our Approach
In this section, we first reformulate object detection in
a per-pixel prediction fashion. Next, we show that how
we make use of multi-level prediction to improve the re-
call and resolve the ambiguity resulted from overlapped
bounding boxes. Finally, we present our proposed “center-
ness” branch, which helps suppress the low-quality detected
bounding boxes and improves the overall performance by a
large margin.
3.1. Fully Convolutional One-Stage Object Detector
Let F
i
∈ R
H×W ×C
be the feature maps at layer i of
a backbone CNN and s be the total stride until the layer.
The ground-truth bounding boxes for an input image are
3
剩余12页未读,继续阅读
1673 浏览量
1684 浏览量
4652 浏览量
2024-12-12 上传
542 浏览量
183 浏览量
221 浏览量
178 浏览量
2023-05-14 上传

小睿羊今天好好学习了吗
- 粉丝: 38
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易二维码签到系统:会议活动签到解决方案
- Ceres库与SDK集成指南:C++环境配置及测试程序
- 深入理解Servlet与JSP技术应用与源码分析
- 初学者指南:掌握VC摄像头抓图源代码实现
- Java实现头像剪裁与上传的camera.swf组件
- FileTime 2013汉化版:单文件修改文件时间的利器
- 波斯语话语项目:实现discourse-persian配置指南
- MP4视频文件数据恢复工具介绍
- 微信与支付宝支付功能封装工具类介绍
- 深入浅出HOOK编程技术与应用
- Jettison 1.0.1源码与Jar包免费下载
- JavaCSV.jar: 解析CSV文档的Java必备工具
- Django音乐网站项目开发指南
- 功能全面的FTP客户端软件FlashFXP_3.6.0.1240_SC发布
- 利用卷积神经网络在Torch 7中实现声学事件检测研究
- 精选网站设计公司官网模板推荐
