Java调用执行Kettle的Transformation与Job指南
"Java调用执行Kettle的transformation和job是通过Kettle的Java API实现的,这允许开发者在Java应用程序中集成ETL(提取、转换、加载)流程。Kettle,又称Pentaho Data Integration (PDI),提供了一套强大的工具集,包括transformation(转换)和job(工作流),用于数据处理和集成。
首先,让我们理解几个关键概念:
1. **Transformation**:在Kettle中,transformation是一系列步骤的集合,用于对数据进行清洗、转换和加载。这些步骤之间通过流连接,形成数据处理的工作流程。
2. **Job**:与transformation不同,job主要用于协调多个transformation和/或其他job,它可以包含条件分支、循环、错误处理等逻辑控制。
3. **Repository**:资源库是Kettle存储元数据的地方,包括transformation、job和其他对象。它可以是一个数据库,存储元数据的表结构由Kettle创建和管理。Repository提供了版本控制、权限管理和集中管理的好处。
配置Repository的步骤如下:
1. 启动Spoon工具,首次运行可能需要创建Repository。Repository可以是无资源库模式(transformation和job以XML文件形式存储在本地),也可以是连接到一个数据库的资源库模式。
2. 在Repository配置中,需要设置DatabaseConnection,这是连接到用于存储Repository元数据的数据库。例如,对于Oracle,需要指定连接类型、访问方式、主机名、数据库名称、端口、用户名和密码。
3. 创建或升级Repository后,使用配置好的Repository登录Kettle,此时可以在Repository模式下设计和存储transformation和job。
在Java应用程序中调用执行transformation和job,你需要以下步骤:
1. 引入Kettle的Java库,通常包括`pentaho-kettle-core`、`pentaho-kettle-engine`和`pentaho-kettle-repository-libs`等相关依赖。
2. 使用`TransMeta`类加载transformation的元数据,`JobMeta`类加载job的元数据。这些元数据可以从Repository中读取,也可以从XML文件加载。
3. 创建`Trans`或`Job`实例,并传递元数据对象。
4. 对于transformation,使用`Trans.execute()`方法执行转换;对于job,使用`Job.execute()`方法启动工作流。
5. 监控和管理执行过程,如错误处理、日志记录和结果检查。
6. 完成执行后,确保正确关闭所有资源,如数据库连接。
在Kettle的API中,还有其他高级功能,如并行执行、错误处理策略、暂停和恢复执行等。同时,Kettle还支持通过Job和Transformation监听器来扩展其行为,以便在特定事件发生时执行自定义逻辑。
Java调用Kettle的transformation和job是通过Kettle的API进行的,这使得在Java应用程序中集成复杂的ETL流程变得可能,同时也便于自动化和管理数据处理任务。正确配置和使用Repository可以提高管理和协作效率,确保数据集成的稳定性和可维护性。"
本文介绍如何在 java 应用程序中调用执行 transformation 和 job。
(一)起步,配置资源库和数据库连接
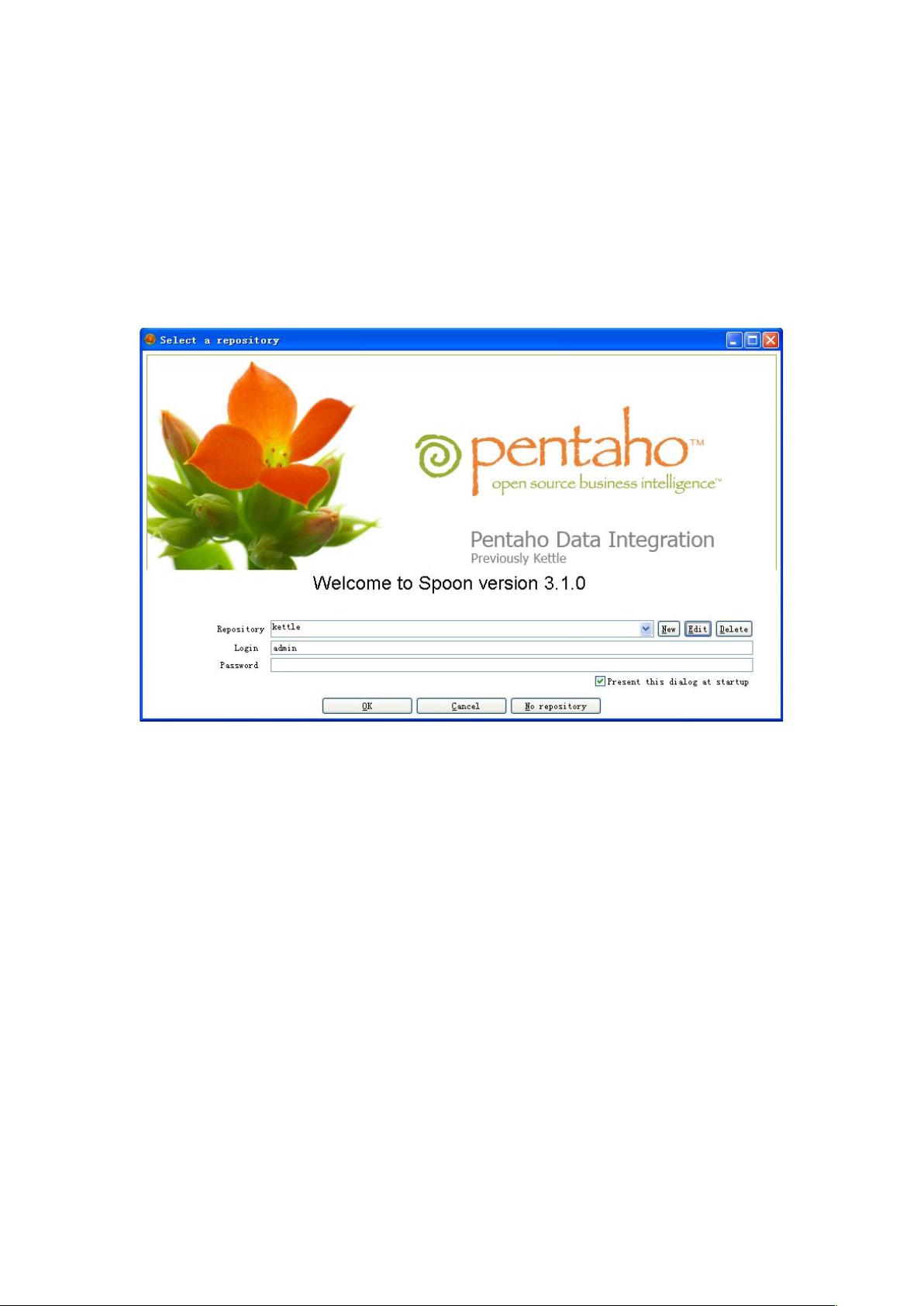
运行 Spoon.bat,启动登录界面,如下图所示:
第一次运行时,Repository 为空,需要创建 Repository。
(什么是 Repository?Repository 即资源库,是 kettle 用于存储元数据的多张数据表,在资源
库模式下设计的 transformation 和 job 都被存储在这些数据表中。)
如果点击界面上的“No repository”,可以在无资源库模式下进行设计,设计的对象最终以
xml 文件的形式存储到本地目录。
点击“New”配置新的 Repository,点击“Edit”编辑现有的 Repository,点击“Delete”删除现有
的 Repository。
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
227 浏览量
2023-06-09 上传
2019-11-16 上传
2012-12-11 上传
2021-05-10 上传
2024-06-15 上传

xiaozheng009
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







