Scrapy配合Selenium抓取豆瓣阅读排行榜全教程
180 浏览量
更新于2024-08-31
收藏 217KB PDF 举报
在本文中,我们将深入探讨如何利用Scrapy和Selenium框架一起爬取豆瓣阅读(Douban Read)的数据,特别是图书排行榜的信息。首先,我们从创建一个基础的Scrapy项目开始。通过命令`scrapy startproject douban_read`,我们初始化了一个名为`douban_read`的项目,这将作为我们的爬虫开发环境。
在项目创建完成后,我们需要为特定的爬虫定义一个spider。使用`scrapy genspider douban_spider url`命令,我们为名为`DoubanSpiderSpider`的爬虫创建了配置文件,并指定初始URL为`https://read.douban.com/charts`,这是豆瓣阅读的图书排行榜页面。
在`douban_spider.py`文件中,定义了爬虫类`DoubanSpiderSpider`,它继承自`scrapy.Spider`。这个类包含了几个关键方法:
1. `name`属性设置为`'douban_spider'`,这是Spiders的唯一标识。
2. `allowed_domains`列表设置为`['www']`,尽管在这个例子中不是必需的,但可以确保爬虫只访问豆瓣阅读的合法域。
3. `start_urls`属性是一个列表,包含我们想要爬取的第一个网页地址。
`parse`方法是爬虫的主要入口点,这里主要负责解析响应并提取所需数据。首先,它使用XPath表达式获取图书分类的链接,这些链接通常包含查询参数。然后,通过正则表达式`re.search`,从链接中提取出动态加载部分的参数,如图书类型和索引。
接下来,构造一个AJAX请求的URL,使用`format`方法将动态参数插入到固定格式的URL中。这里的`ajax_url`将被用来发起一个异步请求,因为豆瓣阅读的部分数据是通过JavaScript动态加载的,不能直接通过HTTP请求获取。`callback`参数指定处理AJAX响应的函数,这里是`self.parse_ajax`。
`parse_ajax`方法会接收从AJAX请求返回的响应,进一步解析和处理数据。由于没有提供实际的`parse_ajax`代码,我们可以假设这里将使用Selenium来模拟浏览器行为,获取动态加载的页面内容。Selenium可以帮助我们在服务器端执行JavaScript,以便获取完整的数据集,包括未在初始HTML中直接提供的部分。
在爬虫运行过程中,Scrapy会根据定义好的逻辑,依次发送请求、解析响应、提取数据,并可能递归地处理后续的AJAX请求,直到所有的数据都被抓取或达到预定的深度限制。
总结来说,本教程详细介绍了如何结合Scrapy和Selenium技术来爬取豆瓣阅读的图书排行榜数据,通过动态处理AJAX请求和解析动态加载的内容,实现了对受限网页的高效抓取。如果你在实际操作中遇到问题,记得检查关键注释代码,或者根据文档和社区资源进行调整和学习。
scrapy利用利用selenium爬取豆瓣阅读的全步骤爬取豆瓣阅读的全步骤
首先创建首先创建scrapy项目项目
命令:scrapy startproject douban_read
创建spider
命令:scrapy genspider douban_spider url
网址:https://read.douban.com/charts
关键注释代码中有,若有不足,请多指教
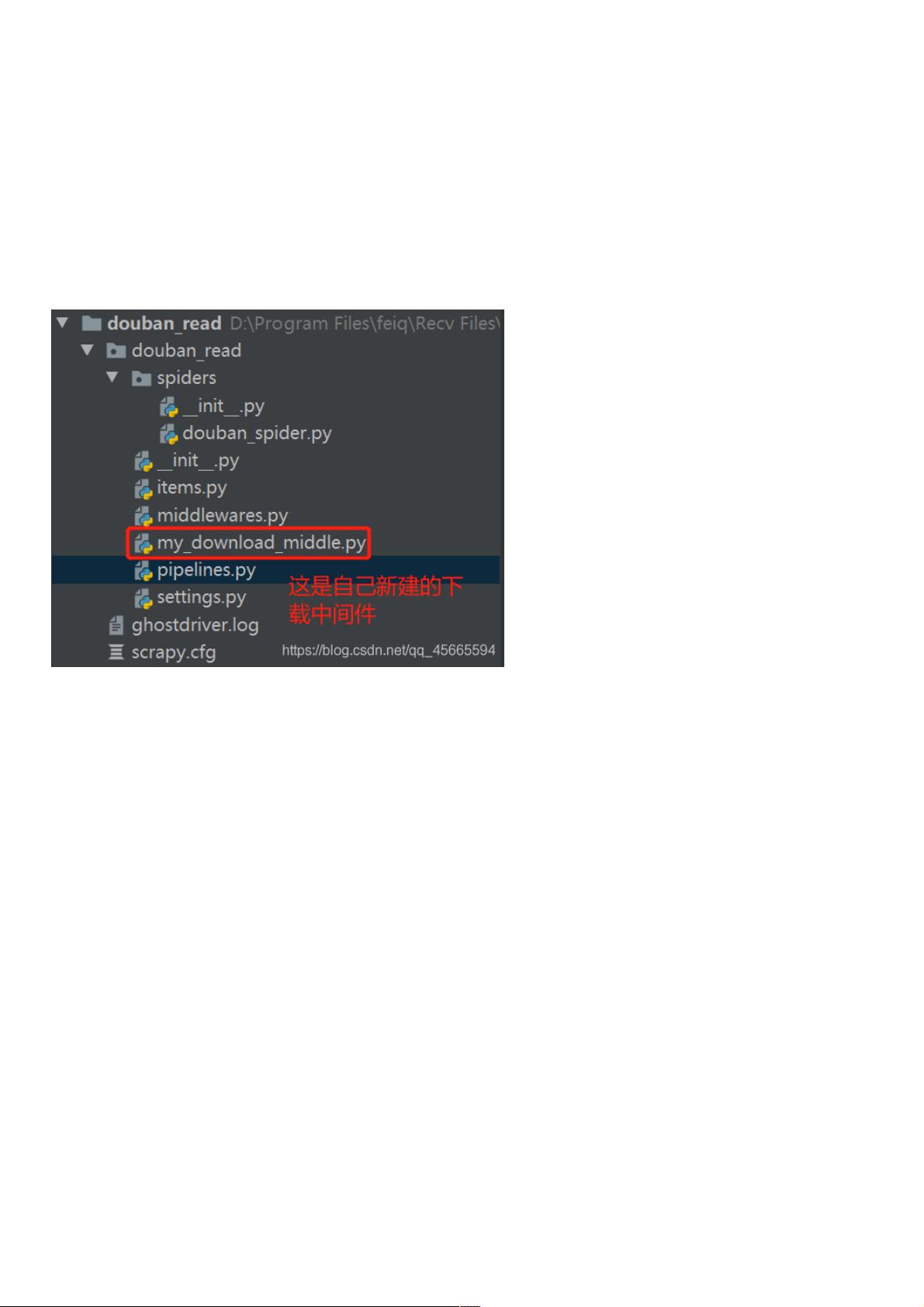
scrapy项目目录结构如下项目目录结构如下
douban_spider.py文件代码文件代码
爬虫文件
import scrapy
import re, json
from ..items import DoubanReadItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# allowed_domains = ['www'] start_urls = ['https://read.douban.com/charts']
def parse(self, response):
# print(response.text)
# 获取图书分类的url
type_urls = response.xpath('//div[@class="rankings-nav"]/a[position()>1]/@href').extract()
# print(type_urls)
for type_url in type_urls:
# /charts?type=unfinished_column&index=featured&dcs=charts&dcm=charts-nav
part_param = re.search(r'charts\?(.*?)&dcs', type_url).group(1)
# https://read.douban.com/j/index//charts?type=intermediate_finalized&index=science_fiction&verbose=1
ajax_url = 'https://read.douban.com/j/index//charts?{}&verbose=1'.format(part_param)
yield scrapy.Request(ajax_url, callback=self.parse_ajax, encoding='utf-8', meta={'request_type': 'ajax'})
def parse_ajax(self, response):
# print(response.text)
# 获取分类中图书的json数据
json_data = json.loads(response.text)
for data in json_data['list']:
item = DoubanReadItem()
item['book_id'] = data['works']['id'] item['book_url'] = data['works']['url'] item['book_title'] = data['works']['title'] item['book_author'] =
data['works']['author'] item['book_cover_image'] = data['works']['cover'] item['book_abstract'] = data['works']['abstract']
item['book_wordCount'] = data['works']['wordCount'] item['book_kinds'] = data['works']['kinds'] # 把item yield给Itempipeline
下载后可阅读完整内容,剩余4页未读,立即下载
2024-03-04 上传
2024-04-09 上传
2020-12-21 上传
2024-03-29 上传
2024-04-09 上传
2023-04-02 上传
2020-09-20 上传
2024-05-21 上传

weixin_38616330
- 粉丝: 4
- 资源: 950
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
