Hadoop 2.7伪分布环境搭建及配置详解
需积分: 10 116 浏览量
更新于2024-09-09
收藏 407KB PDF 举报
本篇文档是一份详尽的Hadoop2.7环境搭建手册,主要介绍了如何在Linux系统上安装和配置Hadoop 2.7环境,特别是针对HDFS(Hadoop Distributed File System)部分的设置。以下是关键步骤:
1. **Java环境准备**:
首先,你需要安装Java 1.8版本,通过解压安装包并将其移动到`/usr/local`目录下。接着,修改用户`~/.bashrc`文件,添加JAVA_HOME、JRE_HOME、CLASSPATH和PATH变量,确保它们指向正确路径。测试Java安装是否成功,通过运行`$java`、`$javac`和`$java -version`命令。
2. **Hadoop伪分布式安装**:
下载并解压Hadoop 2.7.2安装包,将其移动到用户自定义的`bigdata`目录(如`~/bigdata`),这里假设你已经创建了该目录。配置Hadoop环境变量,同样编辑`~/.bashrc`文件,添加`HADOOP_HOME`变量,并将`PATH`变量设置为包含Hadoop bin和sbin目录。最后,运行`$source ~/.bashrc`使配置生效,通过`$hadoop version`检查Hadoop是否安装成功。
3. **Hadoop配置**:
配置的核心是Hadoop的环境变量,包括`hadoop-env.sh`文件。这个文件位于`hadoop安装目录/etc/hadoop/`下。你需要编辑此文件,查找和设置必要的环境变量,例如JAVA_HOME引用、HADOOP_OPTS等,这些参数会影响Hadoop的运行行为和性能。
4. **HDFS配置**:
HDFS配置通常涉及到`core-site.xml`、`hdfs-site.xml`和`yarn-site.xml`等配置文件。这些文件定义了HDFS集群的元数据存储、数据块大小、副本策略、网络设置等重要参数。你需要根据实际情况调整这些配置,确保数据的安全性、可用性和容错性。
5. **启动Hadoop服务**:
完成上述配置后,可以使用`start-all.sh`或`sbin/start-dfs.sh`(HDFS)和`sbin/start-yarn.sh`(YARN)命令启动Hadoop服务。在实际生产环境中,可能还需要设置Hadoop的守护进程守护模式,以便实现长期运行。
6. **验证与监控**:
在Hadoop服务启动后,你可以通过web界面(http://localhost:50070/)查看HDFS和YARN的状态,以及运行的任务。此外,定期监控Hadoop的日志文件也很重要,可以帮助识别和解决问题。
这份指南详细阐述了在Linux系统上搭建Hadoop 2.7环境的每个环节,从基础环境配置到核心组件的部署,旨在帮助读者构建一个稳定且高效的Hadoop分布式计算平台。
实验环境搭建——hadoop 伪分布式
软件准备:jdk1.8 安装包 + Hadoop2.7.2 安装包
1、jdk 安装
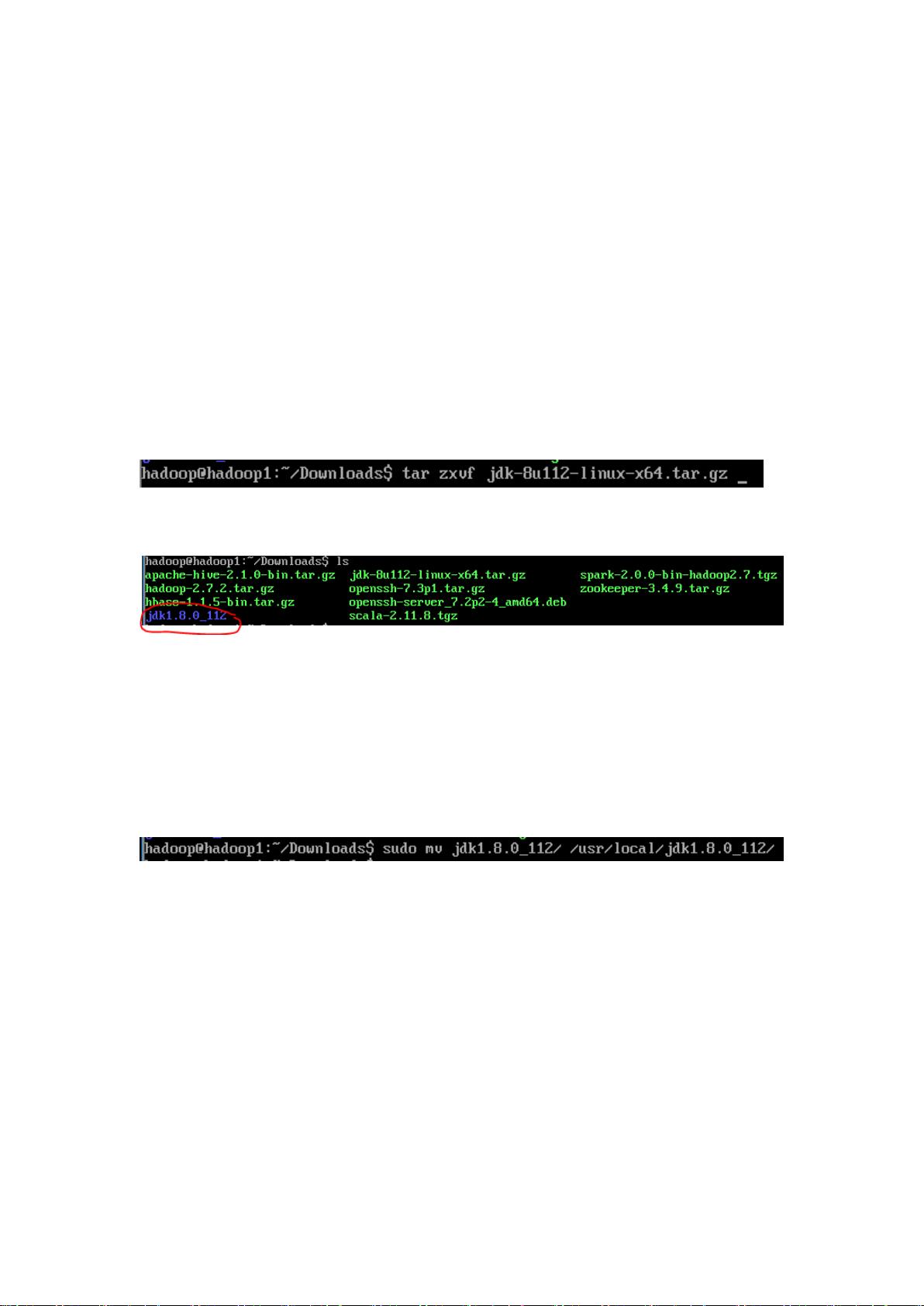
先解压 jdk 安装包,使用命令 $ tar zxvf <你的 jdk 安装包>
在当前目录中会生成 jdk 目录
//将 local 改为 lib
然后把 jdk 目录移动到指定的路径下,这里移动到/usr/local/下,
使用命令 $ sudo mv <你的 jdk 目录/> /usr/local/<新 jdk 目录名>
然后配置 java 环境变量
编辑用户目录下的.bashrc 文件,命令为$ vim ~/.bashrc
在文件最后添加 java 环境变量:
export JAVA_HOME=你的 jdk 目录
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
下载后可阅读完整内容,剩余7页未读,立即下载
192 浏览量
116 浏览量
点击了解资源详情
132 浏览量
点击了解资源详情
165 浏览量
285 浏览量
137 浏览量
2024-05-06 上传

Evan_Gu
- 粉丝: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java Json转换工具:JsonObjectjar库的下载与应用
- 自定义iOS zbar扫描界面,打造完美的条码识别体验
- goless库:在Stackless Python上实现Go并发模式
- Altium Designer R10版本3D库组件详览
- Android Launcher2源代码适配与调试指南
- 探索Base16《冰雪奇缘》黑暗语法主题的深度
- 掌握Matlab符号方程绘图技巧与应用
- Philips Hue监控新工具:hue_exporter Prometheus集成教程
- 轻松学会GPS定位计算方法
- 掌握多屏幕任务栏显示设置技巧
- Cocos Creator游戏开发实战教程:从安装到APK打包
- LG Optimus 4X HD P880成功获取ROOT权限方法
- Zutilo:为Zotero增强编辑功能的开源插件介绍
- 深入React组件库构建全指南:从准备到部署
- Elasticsearch轻包装:HuBMAP搜索API及其索引功能详解
- 联想A2207平板升级工具使用指南
